Dans cet article, je vais vous montrer comment installer et utiliser CURL sur Ubuntu 18.04 Castor bionique. Commençons.
Installation de CURL
Mettez d'abord à jour le cache du référentiel de packages de votre machine Ubuntu avec la commande suivante :
$ sudo apt-get mise à jour
Le cache du référentiel de packages doit être mis à jour.
CURL est disponible dans le référentiel de packages officiel d'Ubuntu 18.04 Castor bionique.
Vous pouvez exécuter la commande suivante pour installer CURL sur Ubuntu 18.04 :
$ sudo apt-get install curl
CURL doit être installé.
Utilisation de CURL
Dans cette section de l'article, je vais vous montrer comment utiliser CURL pour différentes tâches liées à HTTP.
Vérifier une URL avec CURL
Vous pouvez vérifier si une URL est valide ou non avec CURL.
Vous pouvez exécuter la commande suivante pour vérifier si une URL par exemple https://www.Google.com est valide ou non.
$ curl https://www.Google.com
Comme vous pouvez le voir sur la capture d'écran ci-dessous, de nombreux textes sont affichés sur le terminal. Cela signifie l'URL https://www.Google.com est valide.
J'ai exécuté la commande suivante juste pour vous montrer à quoi ressemble une mauvaise URL.
$ curl http://notfound.pas trouvé
Comme vous pouvez le voir sur la capture d'écran ci-dessous, il est dit Impossible de résoudre l'hôte. Cela signifie que l'URL n'est pas valide.
Télécharger une page Web avec CURL
Vous pouvez télécharger une page Web à partir d'une URL en utilisant CURL.
Le format de la commande est :
$ curl -o FILENAME URLIci, FILENAME est le nom ou le chemin du fichier où vous souhaitez enregistrer la page Web téléchargée. L'URL est l'emplacement ou l'adresse de la page Web.
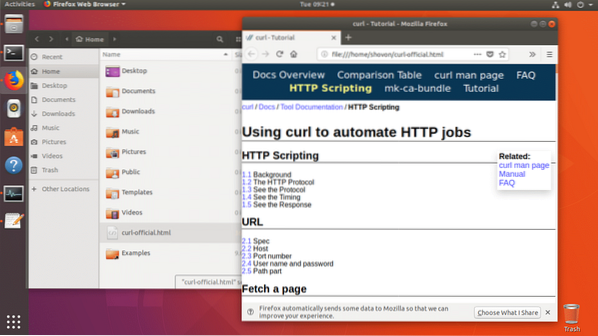
Disons que vous voulez télécharger la page Web officielle de CURL et l'enregistrer en tant que curl-official.fichier html. Exécutez la commande suivante pour le faire :
$ curl -o curl-official.html https://curl.haxx.se/docs/httpscripting.html
La page Web est téléchargée.

Comme vous pouvez le voir à partir de la sortie de la commande ls, la page Web est enregistrée dans curl-official.fichier html.

Vous pouvez également ouvrir le fichier avec un navigateur Web comme vous pouvez le voir sur la capture d'écran ci-dessous.
Télécharger un fichier avec CURL
Vous pouvez également télécharger un fichier sur Internet en utilisant CURL. CURL est l'un des meilleurs téléchargeurs de fichiers en ligne de commande. CURL prend également en charge la reprise des téléchargements.
Le format de la commande CURL pour télécharger un fichier depuis Internet est :
$ curl -O FILE_URLIci FILE_URL est le lien vers le fichier que vous souhaitez télécharger. L'option -O enregistre le fichier avec le même nom que sur le serveur Web distant.
Par exemple, disons que vous voulez télécharger le code source du serveur HTTP Apache depuis Internet avec CURL. Vous exécuteriez la commande suivante :
$ curl -O http://www-eu.apache.org/dist//httpd/httpd-2.4.29.le goudron.gz
Le fichier est en cours de téléchargement.

Le fichier est téléchargé dans le répertoire de travail actuel.

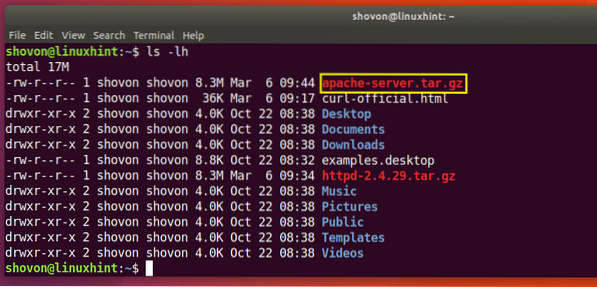
Vous pouvez voir dans la section marquée de la sortie de la commande ls ci-dessous, le http-2.4.29.le goudron.gz que je viens de télécharger.

Si vous souhaitez enregistrer le fichier sous un nom différent de celui du serveur Web distant, exécutez simplement la commande comme suit.
$ curl -o serveur-apache.le goudron.gz http://www-eu.apache.org/dist//httpd/httpd-2.4.29.le goudron.gz
Le téléchargement est terminé.

Comme vous pouvez le voir dans la section marquée de la sortie de la commande ls ci-dessous, le fichier est enregistré sous un nom différent.
Reprendre les téléchargements avec CURL
Vous pouvez également reprendre les téléchargements échoués avec CURL. C'est ce qui fait de CURL l'un des meilleurs téléchargeurs en ligne de commande.
Si vous avez utilisé l'option -O pour télécharger un fichier avec CURL et qu'il a échoué, vous exécutez la commande suivante pour le reprendre à nouveau.
$ curl -C - -O YOUR_DOWNLOAD_LINKIci YOUR_DOWNLOAD_LINK est l'URL du fichier que vous avez essayé de télécharger avec CURL mais cela a échoué.
Supposons que vous essayiez de télécharger l'archive source Apache HTTP Server et que votre réseau s'est déconnecté à mi-chemin et que vous souhaitiez reprendre le téléchargement.
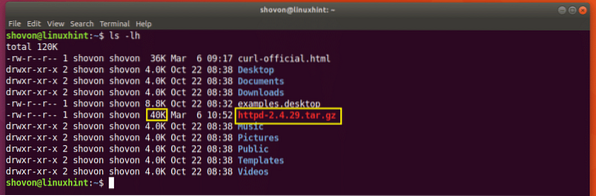
Exécutez la commande suivante pour reprendre le téléchargement avec CURL :
$ curl -C - -O http://www-eu.apache.org/dist//httpd/httpd-2.4.29.le goudron.gz
Le téléchargement reprend.

Si vous avez enregistré le fichier sous un nom différent de celui du serveur Web distant, vous devez exécuter la commande comme suit :
$ curl -C - -o FILENAME DOWNLOAD_LINKIci FILENAME est le nom du fichier que vous avez défini pour le téléchargement. N'oubliez pas que le FILENAME doit correspondre au nom de fichier que vous avez essayé d'enregistrer le téléchargement comme lorsque le téléchargement a échoué.
Limiter la vitesse de téléchargement avec CURL
Vous pouvez avoir une seule connexion Internet connectée au routeur Wi-Fi que tous les membres de votre famille ou de votre bureau utilisent. Si vous téléchargez un gros fichier avec CURL, les autres membres du même réseau peuvent avoir des problèmes lorsqu'ils essaient d'utiliser Internet.
Vous pouvez limiter la vitesse de téléchargement avec CURL si vous le souhaitez.
Le format de la commande est :
$ curl --limit-rate DOWNLOAD_SPEED -O DOWNLOAD_LINKIci DOWNLOAD_SPEED est la vitesse à laquelle vous souhaitez télécharger le fichier.
Disons que vous voulez que la vitesse de téléchargement soit de 10 Ko, exécutez la commande suivante pour le faire :
$ curl --limit-rate 10K -O http://www-eu.apache.org/dist//httpd/httpd-2.4.29.le goudron.gz
Comme vous pouvez le voir, la vitesse est limitée à 10 kilo-octets (Ko), ce qui équivaut à près de 10 000 octets (B).

Obtenir des informations d'en-tête HTTP à l'aide de CURL
Lorsque vous travaillez avec des API REST ou développez des sites Web, vous devrez peut-être vérifier les en-têtes HTTP d'une certaine URL pour vous assurer que votre API ou votre site Web envoie les en-têtes HTTP souhaités. Vous pouvez le faire avec CURL.
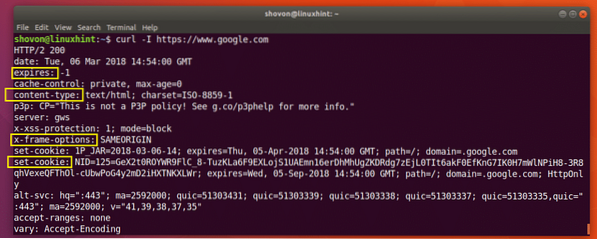
Vous pouvez exécuter la commande suivante pour obtenir les informations d'en-tête de https://www.Google.com :
$ curl -I https://www.Google.com
Comme vous pouvez le voir sur la capture d'écran ci-dessous, tous les en-têtes de réponse HTTP de https://www.Google.com est répertorié.
C'est ainsi que vous installez et utilisez CURL sur Ubuntu 18.04 Castor bionique. Merci d'avoir lu cet article.


