Dans cette leçon sur l'apprentissage automatique avec scikit-learn, nous allons apprendre divers aspects de cet excellent package Python qui nous permet d'appliquer des capacités d'apprentissage automatique simples et complexes sur un ensemble diversifié de données ainsi que des fonctionnalités pour tester l'hypothèse que nous établissons.
Le package scikit-learn contient des outils simples et efficaces pour appliquer l'exploration de données et l'analyse de données sur des ensembles de données et ces algorithmes sont disponibles pour être appliqués dans différents contextes. Il s'agit d'un package open source disponible sous licence BSD, ce qui signifie que nous pouvons utiliser cette bibliothèque même commercialement. Il est construit sur matplotlib, NumPy et SciPy, il est donc de nature polyvalente. Nous utiliserons Anaconda avec le cahier Jupyter pour présenter des exemples dans cette leçon.
Ce que propose scikit-learn?
La bibliothèque scikit-learn se concentre entièrement sur la modélisation des données. Veuillez noter qu'il n'y a pas de fonctionnalités majeures présentes dans le scikit-learn en ce qui concerne le chargement, la manipulation et la synthèse des données. Voici quelques-uns des modèles populaires que scikit-learn nous fournit :
- Regroupement pour regrouper des données étiquetées
- Ensembles de données pour fournir des ensembles de données de test et étudier les comportements des modèles
- Validation croisée pour estimer la performance des modèles supervisés sur des données invisibles
- Méthodes d'ensemble à combiner les prédictions de plusieurs modèles supervisés
- Extraction de caractéristiques pour définir des attributs dans les données d'image et de texte
Installer Python scikit-learn
Juste une note avant de commencer le processus d'installation, nous utilisons un environnement virtuel pour cette leçon que nous avons fait avec la commande suivante :
python -m virtualenv scikitsource scikit/bin/activer
Une fois l'environnement virtuel actif, nous pouvons installer la bibliothèque pandas dans l'environnement virtuel afin que les exemples que nous créons ensuite puissent être exécutés :
pip installer scikit-learnOu, nous pouvons utiliser Conda pour installer ce package avec la commande suivante :
conda installer scikit-learnNous voyons quelque chose comme ceci lorsque nous exécutons la commande ci-dessus :

Une fois l'installation terminée avec Conda, nous pourrons utiliser le package dans nos scripts Python comme :
importer sklearnCommençons à utiliser scikit-learn dans nos scripts pour développer des algorithmes d'apprentissage automatique impressionnants.
Importation de jeux de données
L'un des avantages de scikit-learn est qu'il est préchargé avec des exemples d'ensembles de données avec lesquels il est facile de démarrer rapidement. Les ensembles de données sont les iris et chiffres ensembles de données pour la classification et la prix des maisons à boston ensemble de données pour les techniques de régression. Dans cette section, nous verrons comment charger et commencer à utiliser le jeu de données iris.
Pour importer un ensemble de données, nous devons d'abord importer le module correct, puis obtenir le maintien de l'ensemble de données :
à partir de jeux de données d'importation sklearniris = ensembles de données.load_iris()
chiffres = ensembles de données.load_digits()
chiffres.Les données
Une fois que nous avons exécuté l'extrait de code ci-dessus, nous verrons la sortie suivante :

Toutes les sorties sont supprimées par souci de concision. C'est l'ensemble de données que nous utiliserons principalement dans cette leçon, mais la plupart des concepts peuvent être appliqués à tous les ensembles de données.
Juste un fait amusant de savoir qu'il y a plusieurs modules présents dans le scikit écosystème, dont l'un est apprendre utilisé pour les algorithmes d'apprentissage automatique. Voir cette page pour de nombreux autres modules présents.
Exploration de l'ensemble de données
Maintenant que nous avons importé l'ensemble de données de chiffres fourni dans notre script, nous devons commencer à collecter des informations de base sur l'ensemble de données et c'est ce que nous allons faire ici. Voici les éléments de base que vous devriez explorer tout en cherchant des informations sur un ensemble de données :
- Les valeurs cibles ou les libellés
- L'attribut description
- Les clés disponibles dans l'ensemble de données donné
Écrivons un extrait de code court pour extraire les trois informations ci-dessus de notre ensemble de données :
print('Cible : ', chiffres.cible)print('Touches : ', chiffres.clés())
print('Description : ', chiffres.DESCR)
Une fois que nous avons exécuté l'extrait de code ci-dessus, nous verrons la sortie suivante :
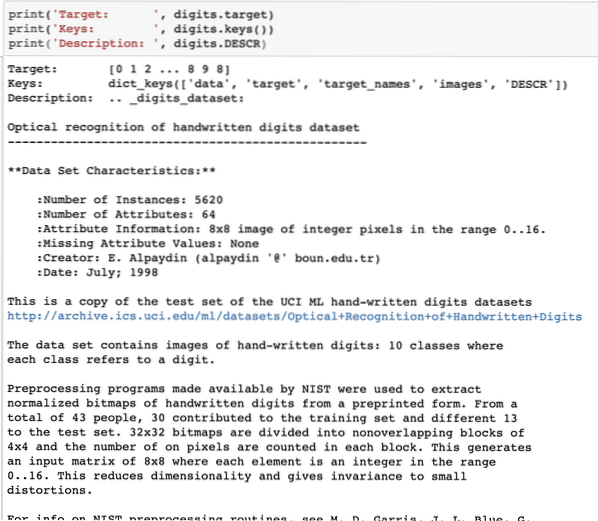
Veuillez noter que les chiffres variables ne sont pas simples. Lorsque nous avons imprimé l'ensemble de données de chiffres, il contenait en fait des tableaux numpy. Nous allons voir comment nous pouvons accéder à ces tableaux. Pour cela, notez les clés disponibles dans l'instance de chiffres que nous avons imprimée dans le dernier extrait de code.
Nous allons commencer par obtenir la forme des données du tableau, qui sont les lignes et les colonnes que le tableau a. Pour cela, nous devons d'abord obtenir les données réelles, puis obtenir leur forme :
digits_set = chiffres.Les donnéesprint(digits_set.façonner)
Une fois que nous avons exécuté l'extrait de code ci-dessus, nous verrons la sortie suivante :

Cela signifie que nous avons 1797 échantillons présents dans notre ensemble de données avec 64 caractéristiques de données (ou colonnes). De plus, nous avons également des étiquettes cibles que nous visualiserons ici à l'aide de matplotlib. Voici un extrait de code qui nous aide à le faire :
importer matplotlib.pyplot en tant que plt# Fusionner les images et les étiquettes cibles en une liste
images_and_labels = list(zip(chiffres.images, chiffres.cible))
pour index, (image, label) dans énumérer(images_and_labels[:8]):
# initialiser une sous-parcelle de 2X4 à la i+1-ième position
plt.sous-intrigue(2, 4, index + 1)
# Pas besoin de tracer des axes
plt.axe('off')
# Afficher les images dans toutes les sous-parcelles
plt.imshow(image, cmap=plt.cm.gray_r,interpolation='le plus proche')
# Ajoutez un titre à chaque sous-parcelle
plt.title('Formation : ' + str(libellé))
plt.spectacle()
Une fois que nous avons exécuté l'extrait de code ci-dessus, nous verrons la sortie suivante :

Notez comment nous avons compressé les deux tableaux NumPy avant de les tracer sur une grille 4 par 2 sans aucune information sur les axes. Maintenant, nous sommes sûrs des informations dont nous disposons sur l'ensemble de données avec lequel nous travaillons.
Maintenant que nous savons que nous avons 64 fonctionnalités de données (qui sont beaucoup de fonctionnalités d'ailleurs), il est difficile de visualiser les données réelles. Nous avons une solution pour cela cependant.
Analyse en Composantes Principales (ACP)
Ce n'est pas un tutoriel sur la PCA, mais donnons une petite idée de ce que c'est. Comme nous savons que pour réduire le nombre d'entités d'un jeu de données, nous avons deux techniques :
- Élimination des fonctionnalités
- Extraction de caractéristiques
Alors que la première technique est confrontée au problème des caractéristiques de données perdues même lorsqu'elles auraient pu être importantes, la deuxième technique ne souffre pas du problème car avec l'aide de l'ACP, nous construisons de nouvelles caractéristiques de données (moins nombreuses) où nous combinons les les variables d'entrée de manière à ce que nous puissions omettre les variables « moins importantes » tout en conservant les parties les plus précieuses de toutes les variables.
Comme anticipé, PCA nous aide à réduire la haute dimensionnalité des données qui est le résultat direct de la description d'un objet à l'aide de nombreuses fonctionnalités de données. Non seulement les chiffres, mais de nombreux autres ensembles de données pratiques ont un grand nombre de fonctionnalités, notamment des données institutionnelles financières, des données météorologiques et économiques pour une région, etc. Lorsque nous effectuons l'ACP sur l'ensemble de données des chiffres, notre objectif sera de trouver seulement 2 caractéristiques telles qu'elles aient la plupart des caractéristiques de l'ensemble de données.
Écrivons un simple extrait de code pour appliquer la PCA sur l'ensemble de données des chiffres afin d'obtenir notre modèle linéaire de seulement 2 caractéristiques :
de sklearn.décomposition importation PCAfeature_pca = PCA(n_composants=2)
Reduced_data_random = feature_pca.fit_transform(chiffres.Les données)
model_pca = PCA(n_composants=2)
Reduced_data_pca = model_pca.fit_transform(chiffres.Les données)
réduit_données_pca.façonner
print(reduced_data_random)
print(reduced_data_pca)
Une fois que nous avons exécuté l'extrait de code ci-dessus, nous verrons la sortie suivante :
[[ -1.2594655 21.27488324][ 7.95762224 -20.76873116]
[ 6.99192123 -9.95598191]
…
[ dix.8012644 -6.96019661]
[ -4.87210598 12.42397516]
[ -0.34441647 6.36562581]]
[[ -1.25946526 21.27487934]
[ 7.95761543 -20.76870705]
[ 6.99191947 -9.9559785 ]
…
[ dix.80128422 -6.96025542]
[ -4.87210144 12.42396098]
[ -0.3443928 6.36555416]]
Dans le code ci-dessus, nous mentionnons que nous n'avons besoin que de 2 fonctionnalités pour l'ensemble de données.
Maintenant que nous avons une bonne connaissance de notre ensemble de données, nous pouvons décider quel type d'algorithmes d'apprentissage automatique nous pouvons y appliquer. Connaître un ensemble de données est important car c'est ainsi que nous pouvons décider quelles informations peuvent en être extraites et avec quels algorithmes. Cela nous aide également à tester l'hypothèse que nous établissons tout en prédisant les valeurs futures.
Application du clustering k-means
L'algorithme de clustering k-means est l'un des algorithmes de clustering les plus simples pour l'apprentissage non supervisé. Dans ce clustering, nous avons un nombre aléatoire de clusters et nous classons nos points de données dans l'un de ces clusters. L'algorithme k-means trouvera le cluster le plus proche pour chacun des points de données donnés et attribuera ce point de données à ce cluster.
Une fois le clustering terminé, le centre du cluster est recalculé, les points de données se voient attribuer de nouveaux clusters en cas de changement. Ce processus est répété jusqu'à ce que les points de données cessent de changer de cluster pour atteindre la stabilité.
Appliquons simplement cet algorithme sans aucun prétraitement des données. Pour cette stratégie, l'extrait de code sera assez simple :
du cluster d'importation sklearnk = 3
k_means = cluster.KMoyenne(k)
# données d'ajustement
k_means.fit (chiffres.Les données)
# résultats d'impression
print(k_signifie.labels_[::10])
imprimer (chiffres.cible[::10])
Une fois que nous avons exécuté l'extrait de code ci-dessus, nous verrons la sortie suivante :
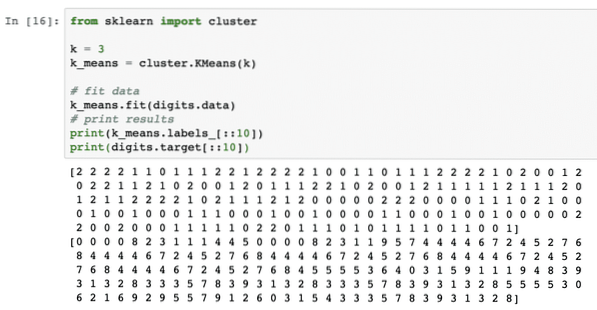
Dans la sortie ci-dessus, nous pouvons voir différents clusters fournis à chacun des points de données.
Conclusion
Dans cette leçon, nous avons examiné une excellente bibliothèque d'apprentissage automatique, scikit-learn. Nous avons appris qu'il existe de nombreux autres modules disponibles dans la famille scikit et nous avons appliqué un simple algorithme k-means sur l'ensemble de données fourni. Il existe de nombreux autres algorithmes qui peuvent être appliqués sur l'ensemble de données en dehors du clustering k-means que nous avons appliqué dans cette leçon, nous vous encourageons à le faire et à partager vos résultats.
Veuillez partager vos commentaires sur la leçon sur Twitter avec @sbmaggarwal et @LinuxHint.


