Pandas pour l'analyse numérique
Pandas a été développé pour répondre au besoin d'un moyen efficace de gérer les données financières en Python. Pandas est une bibliothèque qui peut être importée en python pour aider à manipuler et transformer des données numériques. Wes McKinney a lancé le projet en 2008. Pandas est désormais géré par un groupe d'ingénieurs et soutenu par l'association NUMFocus, qui assurera sa croissance et son développement futurs. Cela signifie que pandas sera une bibliothèque stable pendant de nombreuses années et pourra être inclus dans vos applications sans vous soucier d'un petit projet.
Bien que pandas ait été initialement développé pour modéliser des données financières, ses structures de données peuvent être utilisées pour manipuler une variété de données numériques. Pandas a un certain nombre de structures de données qui sont intégrées et peuvent être utilisées pour modéliser et manipuler facilement des données numériques. Ce tutoriel couvrira les pandas Trame de données structure de données en profondeur.
Qu'est-ce qu'un DataFrame?
UNE Trame de données est l'une des principales structures de données dans les pandas et représente une collection de données en 2D. Il existe de nombreux objets analogues à ce type de structure de données 2D dont certains incluent la feuille de calcul Excel toujours populaire, une table de base de données ou un tableau 2D trouvé dans la plupart des langages de programmation. Ci-dessous un exemple de Trame de données dans un format graphique. Il représente un groupe de séries chronologiques de cours de clôture par date.
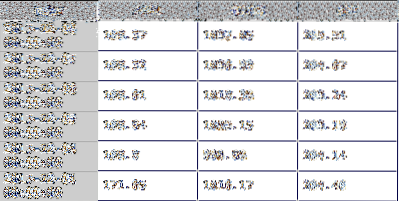
Ce didacticiel vous guidera à travers de nombreuses méthodes du bloc de données et j'utiliserai un modèle financier du monde réel pour démontrer ces fonctions.
Importation de données
Les classes Pandas ont des méthodes intégrées pour aider à importer des données dans une structure de données. Vous trouverez ci-dessous un exemple de la façon d'importer des données dans un panneau pandas avec le Lecteur de données classer. Il peut être utilisé pour importer des données à partir de plusieurs sources de données financières gratuites, notamment Quandl, Yahoo Finance et Google. Pour utiliser la bibliothèque pandas, vous devez l'ajouter en tant qu'import dans votre code.
importer des pandas au format pdLa méthode ci-dessous démarrera le programme en exécutant la méthode d'exécution du didacticiel.
if __name__ == "__main__":tutorial_run()
le tutorial_run la méthode est ci-dessous. C'est la prochaine méthode que je vais ajouter au code. La première ligne de cette méthode définit une liste de tickers boursiers. Cette variable sera utilisée plus tard dans le code comme une liste de stocks pour lesquels des données seront demandées afin de remplir le Trame de données. La deuxième ligne de code appelle le obtenir_données méthode. Comme nous le verrons, le obtenir_données la méthode prend trois paramètres en entrée. Nous transmettrons la liste des téléscripteurs, la date de début et la date de fin des données que nous demanderons.
def tutorial_run() :#Stock Tickers à source de Yahoo Finance
symboles = ['SPY', 'AAPL','GOOG']
#obtenir des données
df = get_data(symboles, '2006-01-03', '2017-12-31')
Ci-dessous, nous définirons le obtenir_données méthode. Comme je l'ai mentionné ci-dessus, il faut trois paramètres une liste de symboles, une date de début et de fin.
La première ligne de code définit un panel de pandas en instanciant un Lecteur de données classer. L'appel au Lecteur de données se connectera au serveur Yahoo Finance et demandera les valeurs de clôture quotidiennes maximales, minimales, de clôture et ajustées pour chacune des actions de la symboles liste. Ces données sont chargées dans un objet panel par les pandas.
UNE panneau est une matrice 3-D et peut être considérée comme une « pile » de DataFrames. Chaque Trame de données dans la pile contient l'une des valeurs quotidiennes pour les stocks et les plages de dates demandées. Par exemple, ci-dessous Trame de données, présenté plus tôt, est le cours de clôture Trame de données de la demande. Chaque type de prix (haut, bas, clôture et clôture ajustée) a son propre Trame de données dans le panneau résultant renvoyé de la demande.
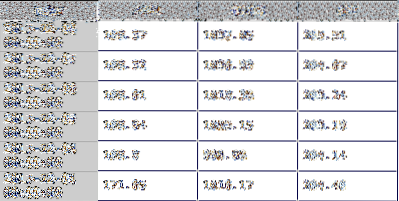
La deuxième ligne de code découpe le panneau en un seul Trame de données et attribue les données résultantes à df. Ce sera ma variable pour le Trame de données que j'utilise pour le reste du tuto. Il contient les valeurs de clôture quotidiennes des trois actions pour la plage de dates spécifiée. Le panneau est découpé en spécifiant lequel des panneaux DataFrames vous voudriez revenir. Dans cet exemple de ligne de code ci-dessous, il s'agit du 'Fermer'.
Une fois que nous avons notre Trame de données en place, je couvrirai certaines des fonctions utiles de la bibliothèque pandas qui nous permettront de manipuler les données dans le Trame de données objet.
def get_data(symboles, start_date, end_date):panneau = données.DataReader(symboles, 'yahoo', start_date, end_date)
df = panneau['Fermer']
imprimer (df.tête(5))
imprimer (df.queue (5))
retour df
Pile et face
La troisième et la quatrième ligne de obtenir_données imprimer la fonction tête et queue de la trame de données. Je trouve cela très utile pour le débogage et la visualisation des données, mais il peut également être utilisé pour sélectionner le premier ou le dernier échantillon des données dans le Trame de données. La fonction head and tail extrait les première et dernière lignes de données du Trame de données. Le paramètre entier entre parenthèses définit le nombre de lignes à sélectionner par la méthode.
.loc
le Trame de données loc la méthode tranche le Trame de données par indice. La ligne de code ci-dessous tranche le df Trame de données par l'indice 2017-12-12. J'ai fourni une capture d'écran des résultats ci-dessous.
imprimer df.loc["2017-12-12"]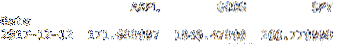
loc peut également être utilisé comme une tranche bidimensionnelle. Le premier paramètre est la ligne et le deuxième paramètre est la colonne. Le code ci-dessous renvoie une valeur unique qui est égale au cours de clôture d'Apple le 12/12/2014.
imprimer df.loc["2017-12-12", "AAPL" ]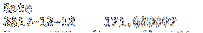
le loc La méthode peut être utilisée pour découper toutes les lignes d'une colonne ou toutes les colonnes d'une ligne. le : l'opérateur est utilisé pour désigner tout. La ligne de code ci-dessous sélectionne toutes les lignes de la colonne pour les cours de clôture de Google.
imprimer df.loc[: , "GOOG" ]
.remplir
Il est courant, en particulier dans les ensembles de données financières, d'avoir des valeurs NaN dans votre Trame de données. Pandas fournit une fonction pour remplir ces valeurs avec une valeur numérique. Ceci est utile si vous souhaitez effectuer une sorte de calcul sur les données qui peuvent être faussées ou échouer en raison des valeurs NaN.
le .remplir méthode remplacera la valeur spécifiée pour chaque valeur NaN dans votre ensemble de données. La ligne de code ci-dessous remplira tous les NaN de notre Trame de données avec un 0. Cette valeur par défaut peut être modifiée pour une valeur qui répond aux besoins de l'ensemble de données avec lequel vous travaillez en mettant à jour le paramètre qui est passé à la méthode.
df.remplir(0)Normalisation des données
Lorsque vous utilisez des algorithmes d'apprentissage automatique ou d'analyse financière, il est souvent utile de normaliser vos valeurs. La méthode ci-dessous est un calcul efficace pour normaliser les données d'un panda Trame de données. Je vous encourage à utiliser cette méthode car ce code s'exécutera plus efficacement que les autres méthodes de normalisation et peut afficher de grandes augmentations de performances sur de grands ensembles de données.
.iloc est une méthode similaire à .loc mais prend des paramètres basés sur l'emplacement plutôt que les paramètres basés sur les balises. Il prend un index basé sur zéro plutôt que le nom de la colonne du .loc Exemple. Le code de normalisation ci-dessous est un exemple de certains des calculs matriciels puissants qui peuvent être effectués. Je vais sauter la leçon d'algèbre linéaire, mais essentiellement cette ligne de code divisera la matrice entière ou Trame de données par la première valeur de chaque série temporelle. En fonction de votre ensemble de données, vous voudrez peut-être une norme basée sur min, max ou moyenne. Ces normes peuvent également être facilement calculées en utilisant le style basé sur la matrice ci-dessous.
def normaliser_données (df):retour df / df.iloc [0,:]
Tracer des données
Lorsqu'on travaille avec des données, il est souvent nécessaire de les représenter graphiquement. La méthode plot vous permet de créer facilement un graphique à partir de vos ensembles de données.
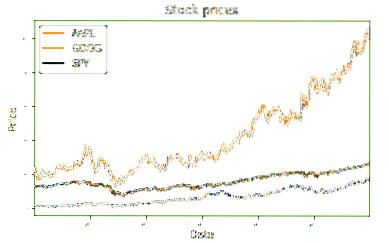
La méthode ci-dessous prend notre Trame de données et le trace sur un graphique linéaire standard. La méthode prend une Trame de données et un titre comme paramètres. La première ligne des jeux de codes hache à une parcelle de la DataFrame df. Il définit le titre et la taille de la police du texte. Les deux lignes suivantes définissent les étiquettes des axes x et y. La dernière ligne de code appelle la méthode show qui imprime le graphique sur la console. J'ai fourni une capture d'écran des résultats de l'intrigue ci-dessous. Cela représente les cours de clôture normalisés pour chacune des actions sur la période sélectionnée.
def plot_data(df, title="Prix des actions") :hache = df.plot(title=title,fontsize = 2)
hache.set_xlabel("Date")
hache.set_ylabel("Prix")
parcelle.spectacle()
Pandas est une bibliothèque de manipulation de données robuste. Il peut être utilisé pour différents types de données et présente un ensemble succinct et efficace de méthodes pour manipuler votre ensemble de données. Ci-dessous, j'ai fourni le code complet du didacticiel afin que vous puissiez le réviser et le modifier pour répondre à vos besoins. Il existe quelques autres méthodes qui vous aident à manipuler les données et je vous encourage à consulter les documents sur les pandas publiés dans les pages de référence ci-dessous. NumPy et MatPlotLib sont deux autres bibliothèques qui fonctionnent bien pour la science des données et peuvent être utilisées pour améliorer la puissance de la bibliothèque pandas.
Code complet
importer des pandas au format pddef plot_selected(df, colonnes, start_index, end_index):
plot_data(df.ix[start_index:end_index, colonnes])
def get_data(symboles, start_date, end_date):
panneau = données.DataReader(symboles, 'yahoo', start_date, end_date)
df = panneau['Fermer']
imprimer (df.tête(5))
imprimer (df.queue (5))
imprimer df.loc["2017-12-12"]
imprimer df.loc["2017-12-12", "AAPL" ]
imprimer df.loc[: , "GOOG" ]
df.remplir(0)
retour df
def normaliser_données (df):
retour df / df.ix[0,:]
def plot_data(df, title="Prix des actions") :
hache = df.plot(title=title,fontsize = 2)
hache.set_xlabel("Date")
hache.set_ylabel("Prix")
parcelle.spectacle()
def tutorial_run() :
#Choisir des symboles
symboles = ['SPY', 'AAPL','GOOG']
#obtenir des données
df = get_data(symboles, '2006-01-03', '2017-12-31')
plot_data(df)
if __name__ == "__main__":
tutorial_run()
Les références
Page d'accueil des pandas
Page Wikipédia des pandas
https://fr.Wikipédia.org/wiki/Wes_McKinney
Page d'accueil NumFocus


