Il existe également une option pour enregistrer une conception de graphique hors ligne afin qu'elle puisse être exportée facilement. Il existe de nombreuses autres fonctionnalités qui rendent l'utilisation de la bibliothèque très facile :
- Enregistrez les graphiques pour une utilisation hors ligne sous forme de graphiques vectoriels hautement optimisés à des fins d'impression et de publication
- Les graphiques exportés sont au format JSON et non au format image. Ce JSON peut être facilement chargé dans d'autres outils de visualisation comme Tableau ou manipulé avec Python ou R
- Les graphiques exportés étant de nature JSON, il est pratiquement très simple d'intégrer ces graphiques dans une application web
- Plotly est une bonne alternative à Matplotlib pour la visualisation
Pour commencer à utiliser le package Plotly, nous devons créer un compte sur le site Web mentionné précédemment pour obtenir un nom d'utilisateur et une clé API valides avec lesquels nous pouvons commencer à utiliser ses fonctionnalités. Heureusement, un plan tarifaire gratuit est disponible pour Plotly avec lequel nous obtenons suffisamment de fonctionnalités pour créer des graphiques de qualité production.
Installation de Plotly
Juste une remarque avant de commencer, vous pouvez utiliser un environnement virtuel pour cette leçon que nous pouvons faire avec la commande suivante :
python -m virtualenv plotlysource numpy/bin/activer
Une fois l'environnement virtuel actif, vous pouvez installer la bibliothèque Plotly dans l'environnement virtuel afin que les exemples que nous créons ensuite puissent être exécutés :
pip installer plotlyNous utiliserons Anaconda et Jupyter dans cette leçon. Si vous souhaitez l'installer sur votre machine, regardez la leçon qui décrit "Comment installer Anaconda Python sur Ubuntu 18.04 LTS" et partagez vos commentaires si vous rencontrez des problèmes. Pour installer Plotly avec Anaconda, utilisez la commande suivante dans le terminal d'Anaconda :
conda install -c plotly plotlyNous voyons quelque chose comme ceci lorsque nous exécutons la commande ci-dessus :
Une fois que tous les packages nécessaires sont installés et terminés, nous pouvons commencer à utiliser la bibliothèque Plotly avec l'instruction d'importation suivante :
importer le tracéUne fois que vous avez créé un compte sur Plotly, vous aurez besoin de deux choses - le nom d'utilisateur du compte et une clé API. Il ne peut y avoir qu'une seule clé API appartenant à chaque compte. Alors gardez-le dans un endroit sûr comme si vous le perdiez, vous devrez régénérer la clé et toutes les anciennes applications utilisant l'ancienne clé cesseront de fonctionner.
Dans tous les programmes Python que vous écrivez, mentionnez les informations d'identification comme suit pour commencer à travailler avec Plotly :
comploter.outils.set_credentials_file(username = 'username', api_key = 'your-api-key')Commençons maintenant avec cette bibliothèque.
Premiers pas avec Plotly
Nous utiliserons les importations suivantes dans notre programme :
importer des pandas au format pdimporter numpy en tant que np
importer scipy en tant que sp
importer le tracé.comploter en tant que py
Nous utilisons :
- Pandas pour lire efficacement les fichiers CSV
- NumPy pour des opérations tabulaires simples
- Scipy pour les calculs scientifiques
- Plotly pour la visualisation
Pour certains des exemples, nous utiliserons les propres ensembles de données de Plotly disponibles sur Github. Enfin, veuillez noter que vous pouvez également activer le mode hors ligne pour Plotly lorsque vous devez exécuter des scripts Plotly sans connexion réseau :
importer des pandas au format pdimporter numpy en tant que np
importer scipy en tant que sp
importer le tracé
comploter.hors ligne.init_notebook_mode(connected=True)
importer le tracé.hors ligne en tant que py
Vous pouvez exécuter l'instruction suivante pour tester l'installation de Plotly :
imprimer (intriguement.__version__)Nous voyons quelque chose comme ceci lorsque nous exécutons la commande ci-dessus :

Nous allons enfin télécharger le jeu de données avec Pandas et le visualiser sous forme de tableau :
importer le tracé.figure_factory comme ffdf = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/school_
gains.csv")
tableau = ff.create_table(df)
py.iplot(table, nom de fichier='table')
Nous voyons quelque chose comme ceci lorsque nous exécutons la commande ci-dessus :
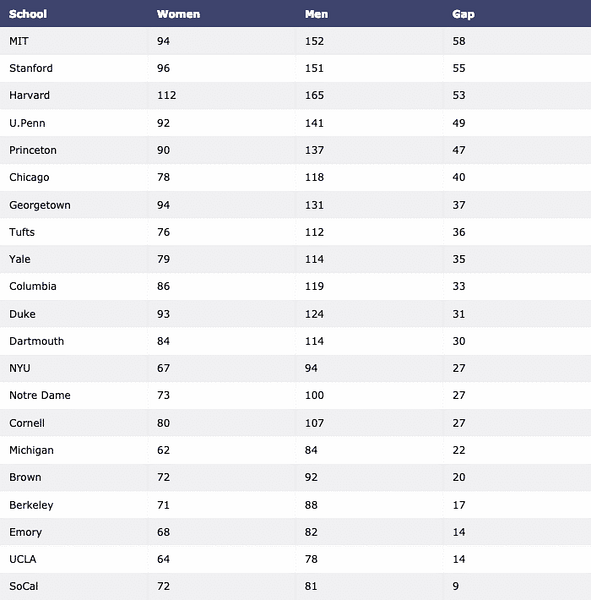
Maintenant, construisons un Graphique à barres pour visualiser les données :
importer le tracé.graph_objs au fur et à mesuredonnées = [aller.Barre(x=df.École, y=df.Femmes)]
py.iplot(data, filename='women-bar')
Nous voyons quelque chose comme ceci lorsque nous exécutons l'extrait de code ci-dessus :
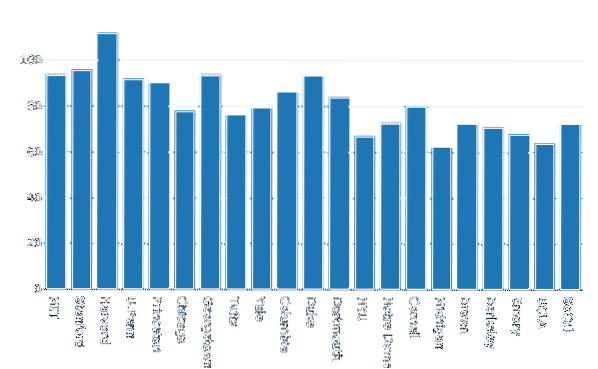
Lorsque vous voyez le graphique ci-dessus avec le bloc-notes Jupyter, diverses options de zoom avant/arrière sur une section particulière du graphique, la sélection Box & Lasso et bien plus encore vous seront présentées.
Graphiques à barres groupés
Plusieurs graphiques à barres peuvent être regroupés très facilement à des fins de comparaison avec Plotly. Utilisons le même ensemble de données pour cela et montrons la variation de la présence des hommes et des femmes dans les universités :
femmes = aller.Barre(x=df.École, y=df.Femmes)hommes = aller.Barre(x=df.École, y=df.Hommes)
données = [hommes, femmes]
mise en page = aller.Layout(barmode = "groupe")
figue = aller.Figure (données = données, mise en page = mise en page)
py.iplot (fig)
Nous voyons quelque chose comme ceci lorsque nous exécutons l'extrait de code ci-dessus :

Bien que cela semble bon, les étiquettes dans le coin supérieur droit ne sont pas correctes! Corrigons-les :
femmes = aller.Barre(x=df.École, y=df.Femmes, nom = "Femmes")hommes = aller.Barre(x=df.École, y=df.Hommes, nom = "Hommes")
Le graphique semble maintenant beaucoup plus descriptif :
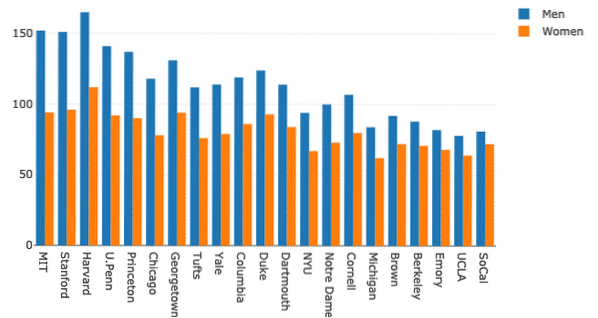
Essayons de changer le barmode :
mise en page = aller.Layout(barmode = "relative")figue = aller.Figure (données = données, mise en page = mise en page)
py.iplot (fig)
Nous voyons quelque chose comme ceci lorsque nous exécutons l'extrait de code ci-dessus :
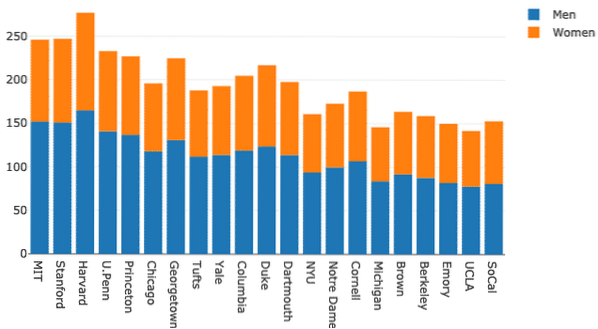
Graphiques à secteurs avec Plotly
Maintenant, nous allons essayer de construire un camembert avec Plotly qui établit une différence fondamentale entre le pourcentage de femmes dans toutes les universités. Le nom des universités sera les étiquettes et les nombres réels seront utilisés pour calculer le pourcentage de l'ensemble. Voici l'extrait de code pour le même:
trace = aller.Tarte (étiquettes = df.École, valeurs = df.Femmes)py.iplot([trace], nom de fichier='tarte')
Nous voyons quelque chose comme ceci lorsque nous exécutons l'extrait de code ci-dessus :
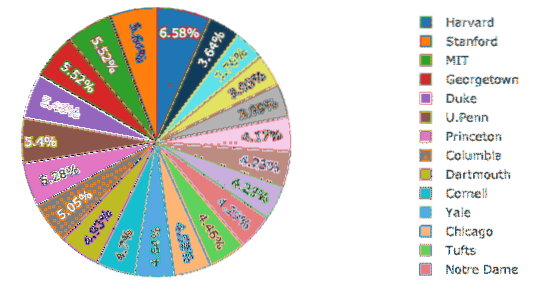
La bonne chose est que Plotly est livré avec de nombreuses fonctionnalités de zoom avant et arrière et de nombreux autres outils pour interagir avec le graphique construit.
Visualisation des données de séries temporelles avec Plotly
La visualisation des données de séries chronologiques est l'une des tâches les plus importantes qui se présentent lorsque vous êtes un analyste de données ou un ingénieur de données.
Dans cet exemple, nous utiliserons un ensemble de données distinct dans le même référentiel GitHub, car les données précédentes n'impliquaient spécifiquement aucune donnée horodatée. Comme ici, nous allons tracer la variation de l'action boursière d'Apple au fil du temps :
financier = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/finances-graphiques-apple.csv")
données = [aller.Dispersion(x=financier.Date, y=financier['AAPL.Fermer'])]
py.iplot(données)
Nous voyons quelque chose comme ceci lorsque nous exécutons l'extrait de code ci-dessus :
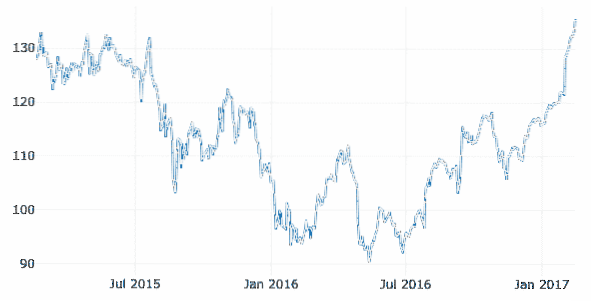
Une fois que vous passez votre souris sur la ligne de variation du graphique, vous pouvez des détails de points spécifiques :

Nous pouvons également utiliser les boutons de zoom avant et arrière pour voir les données spécifiques à chaque semaine.
Graphique OHLC
Un graphique OHLC (Open High Low close) est utilisé pour montrer la variation d'une entité sur une période de temps. C'est facile à construire avec PyPlot :
à partir de datetime importer datetimeopen_data = [33.0, 35.3, 33.5, 33.0, 34.1]
données_élevées = [33.1, 36.3, 33.6, 33.2, 34.8]
low_data = [32.7, 32.7, 32.8, 32.6, 32.8]
close_data = [33.0, 32.9, 33.3, 33.1, 33.1]
dates = [datetime(année=2013, mois=10, jour=10),
datetime(année=2013, mois=11, jour=10),
datetime(année=2013, mois=12, jour=10),
datetime(année=2014, mois=1, jour=10),
datetime(année=2014, mois=2, jour=10)]
trace = aller.Ohlc(x=dates,
open=open_data,
high=high_data,
low=low_data,
close=close_data)
données = [trace]
py.iplot(données)
Ici, nous avons fourni quelques exemples de points de données qui peuvent être déduits comme suit :
- Les données ouvertes décrivent le cours de l'action à l'ouverture du marché
- Les données élevées décrivent le taux de stock le plus élevé atteint au cours d'une période de temps donnée
- Les données faibles décrivent le taux de stock le plus bas atteint au cours d'une période de temps donnée
- Les données de clôture décrivent le cours du stock de clôture lorsqu'un intervalle de temps donné était terminé
Maintenant, exécutons l'extrait de code que nous avons fourni ci-dessus. Nous voyons quelque chose comme ceci lorsque nous exécutons l'extrait de code ci-dessus :
C'est une excellente comparaison sur la façon d'établir des comparaisons temporelles d'une entité avec la sienne et de la comparer à ses réalisations élevées et faibles.
Conclusion
Dans cette leçon, nous avons examiné une autre bibliothèque de visualisation, Plotly qui est une excellente alternative à Matplotlib dans les applications de production qui sont exposées en tant qu'applications Web, Plotly est une bibliothèque très dynamique et riche en fonctionnalités à utiliser à des fins de production, donc c'est définitivement une compétence que nous devons avoir à notre actif.
Retrouvez tout le code source utilisé dans cette leçon sur Github. Veuillez partager vos commentaires sur la leçon sur Twitter avec @sbmaggarwal et @LinuxHint.


