Science des données
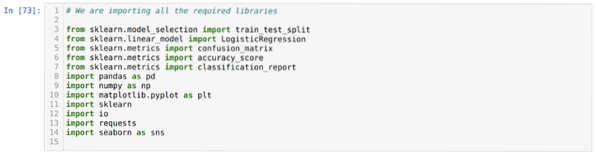
Régression logistique en Python
La régression logistique est un algorithme de classification d'apprentissage automatique. La régression logistique est également similaire à la régres...
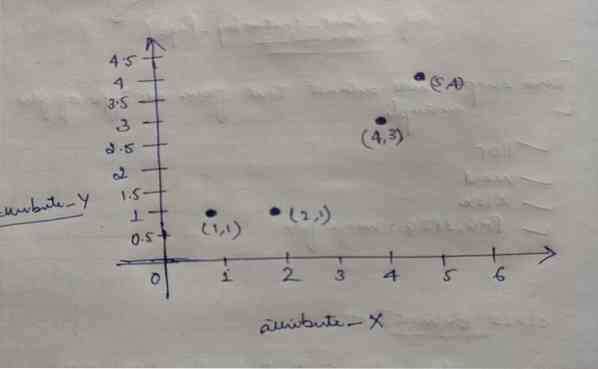
Clustering K-Means
Le code de ce blog, ainsi que l'ensemble de données, sont disponibles sur le lien suivant https://github.com/shekharpandey89/k-means Le clustering K-M...

Comment créer un tableau croisé dynamique dans Pandas Python
Dans le python de panda, le tableau croisé dynamique comprend des fonctions de somme, de nombre ou d'agrégation dérivées d'un tableau de données. Les ...
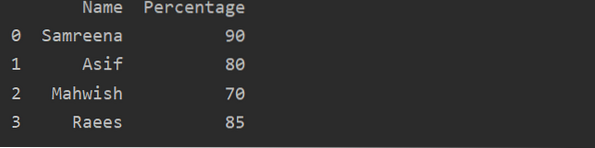
Comment créer un DataFrame Pandas en Python?
Pandas DataFrame est une structure de données annotée 2D (bidimensionnelle) dans laquelle les données sont alignées sous forme de tableau avec différe...
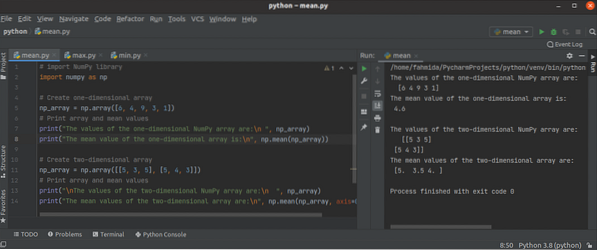
Comment utiliser les fonctions Python NumPy Mean(), min() et max()?
La bibliothèque Python NumPy possède de nombreuses fonctions agrégées ou statistiques pour effectuer différents types de tâches avec le tableau unidim...
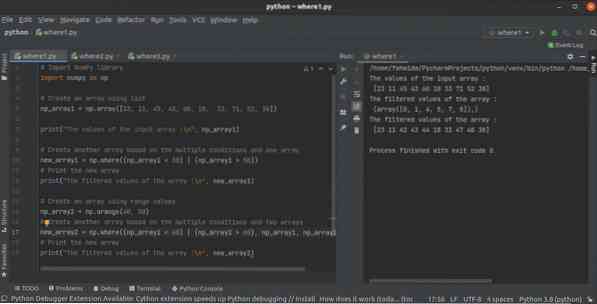
Comment utiliser la fonction python NumPy where() avec plusieurs conditions
La bibliothèque NumPy a de nombreuses fonctions pour créer le tableau en python. La fonction where () est l'une d'entre elles pour créer un tableau à ...
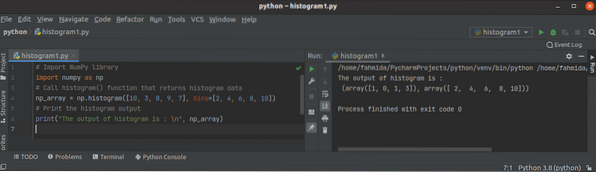
Tutoriel sur l'histogramme Python NumPy()
Un histogramme est un mappage d'intervalles en fréquences. Il est utilisé pour approximer la fonction de densité de probabilité de la variable particu...
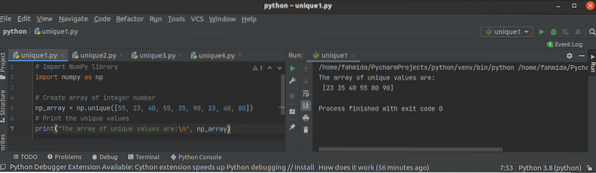
Comment utiliser la fonction Python NumPy unique ()
La bibliothèque NumPy est utilisée en python pour créer un ou plusieurs tableaux dimensionnels, et elle a de nombreuses fonctions pour travailler avec...
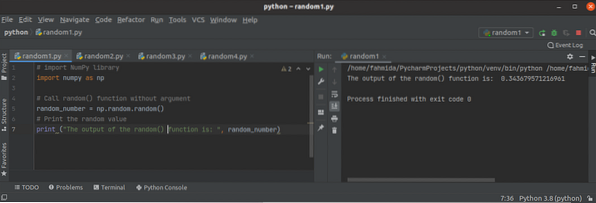
Comment utiliser la fonction aléatoire Python NumPy?
Lorsque la valeur du nombre change à chaque exécution du script, alors ce nombre est appelé un nombre aléatoire. Les nombres aléatoires sont principal...


