Le World Wide Web est la source universelle et ultime de toutes les données disponibles. Le développement rapide qu'a connu Internet au cours des trois dernières décennies a été sans précédent. En conséquence, le Web est monté avec des centaines de téraoctets de données chaque jour qui passe.
Toutes ces données ont une certaine valeur pour une certaine personne. Par exemple, votre historique de navigation est important pour les applications de médias sociaux, car elles l'utilisent pour personnaliser les publicités qu'elles vous montrent. Et il y a aussi beaucoup de concurrence pour ces données ; quelques Mo de plus de certaines données peuvent donner aux entreprises un avantage substantiel sur leurs concurrents.
Exploration de données avec Python
Pour aider ceux d'entre vous qui débutent dans le grattage de données, nous avons préparé ce guide dans lequel nous montrerons comment extraire des données du Web à l'aide de Python et de Beautiful soup Library.
Nous supposons que vous avez déjà une connaissance intermédiaire de Python et HTML, car vous travaillerez avec les deux en suivant les instructions de ce guide.
Soyez prudent quant aux sites sur lesquels vous essayez vos nouvelles compétences en exploration de données, car de nombreux sites considèrent cela comme intrusif et savent qu'il pourrait y avoir des répercussions.
Installation et préparation des bibliothèques
Maintenant, nous allons utiliser deux bibliothèques que nous allons utiliser : la bibliothèque de requêtes de python pour charger le contenu des pages Web et la bibliothèque Beautiful Soup pour le processus de grattage réel. Il existe des alternatives à BeautifulSoup, remarquez, et si vous connaissez l'un des éléments suivants, n'hésitez pas à les utiliser à la place : Scrappy, Mechanize, Selenium, Portia, kimono et ParseHub.
La bibliothèque de requêtes peut être téléchargée et installée avec la commande pip comme ci-dessous :
# demandes d'installation de pip3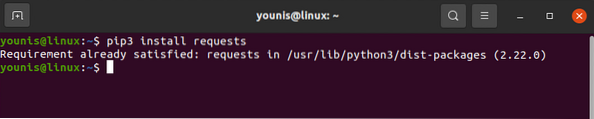
La bibliothèque de requêtes doit être installée sur votre appareil. De même, téléchargez également BeautifulSoup :
# pip3 installer beautifulsoup4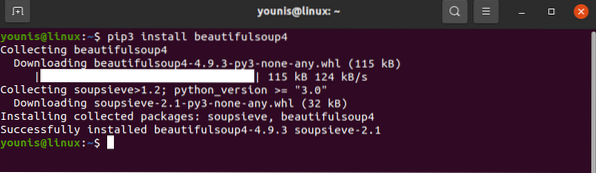
Avec cela, nos bibliothèques sont prêtes pour une action.
Comme mentionné ci-dessus, la bibliothèque de requêtes n'a pas beaucoup d'utilité autre que de récupérer le contenu des pages Web. La bibliothèque BeautifulSoup et les bibliothèques de requêtes ont une place dans chaque script que vous allez écrire, et elles doivent être importées avant chacune comme suit :
$ demandes d'importation$from bs4 importer BeautifulSoup en tant que bs
Cela ajoute le mot-clé demandé à l'espace de noms, signalant à Python la signification du mot-clé chaque fois que son utilisation est demandée. La même chose arrive au mot-clé bs, bien que nous ayons ici l'avantage d'attribuer un mot-clé plus simple pour BeautifulSoup.
page Web = demandes.obtenir(URL)Le code ci-dessus récupère l'URL de la page Web et en crée une chaîne directe, la stockant dans une variable.
$webcontent = page Web.contenuLa commande ci-dessus copie le contenu de la page Web et l'affecte au contenu Web variable.
Avec cela, nous en avons fini avec la bibliothèque de requêtes. Il ne reste plus qu'à changer les options de la bibliothèque de requêtes en options BeautifulSoup.
$htmlcontent = bs(webcontent, "html.analyseur »)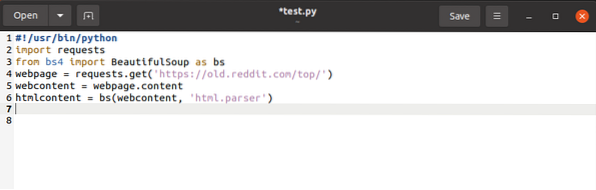
Cela analyse l'objet de requête et le transforme en objets HTML lisibles.
Avec tout cela pris en charge, nous pouvons passer au bit de raclage réel.
Web scraping avec Python et BeautifulSoup
Passons à autre chose et voyons comment nous pouvons rechercher des objets HTML de données avec BeautifulSoup.
Pour illustrer un exemple, pendant que nous expliquons les choses, nous allons travailler avec cet extrait html :
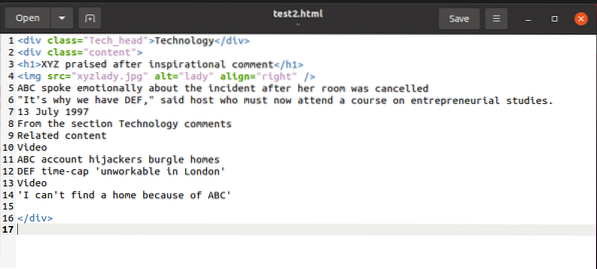
Nous pouvons accéder au contenu de cet extrait avec BeautifulSoup et l'utiliser sur la variable de contenu HTML comme ci-dessous :
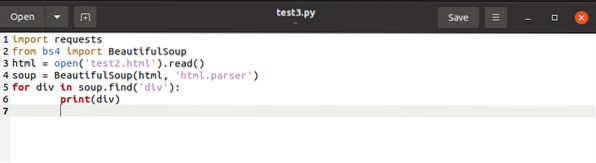
Le code ci-dessus recherche toutes les balises nommées
Pour enregistrer simultanément les balises nommées
à une liste, nous émettrons le code final comme ci-dessous :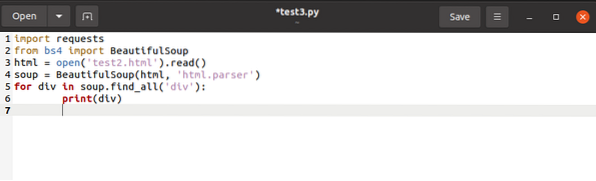
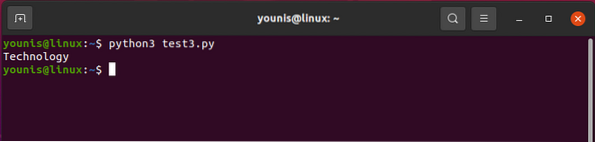
La sortie devrait revenir comme ceci :
Pour invoquer l'un des
Voyons maintenant comment choisir
tags gardant en perspective leurs caractéristiques. Pour séparer un , nous aurions besoin du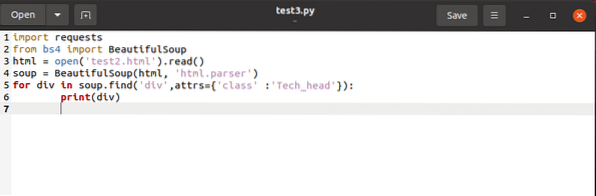
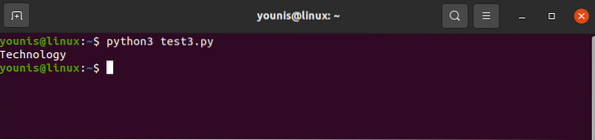
pour div dans la soupe.find_all('div',attrs='class'='Tech_head') :
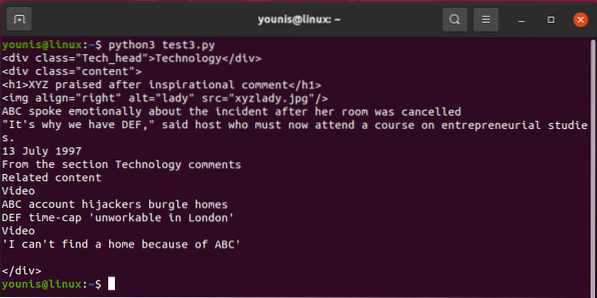
Cela récupère le
étiqueter.Vous obtiendrez :
La technologie
Le tout sans étiquette.
Enfin, nous verrons comment choisir la valeur de l'attribut dans une balise. Le code doit avoir cette balise :
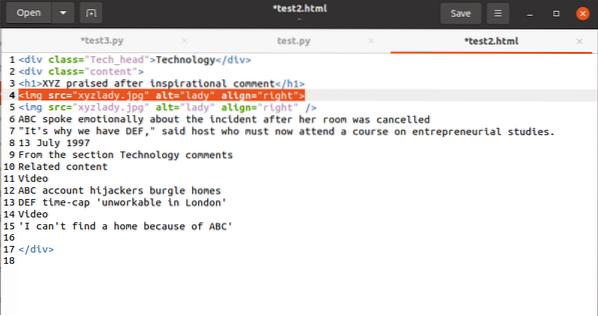

Pour exploiter la valeur associée à l'attribut src, vous utiliserez ce qui suit :
contenu html.trouver(“img“)[“src“]Et la sortie s'avérerait comme:
"images_4/a-guide-des-débutants-de-grattage-web-avec-python-et-belle-soupe.jpg"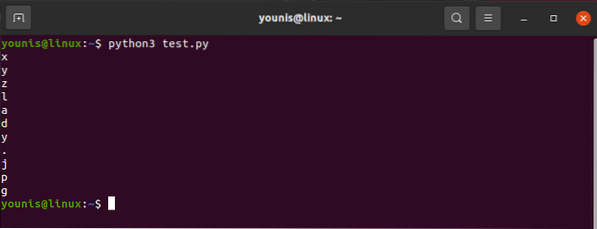
Oh mon garçon, c'est sûr que c'est beaucoup de travail!
Si vous pensez que votre familiarité avec python ou HTML est insuffisante ou si vous êtes simplement submergé par le grattage Web, ne vous inquiétez pas.
Si vous êtes une entreprise qui a besoin d'acquérir régulièrement un type particulier de données mais que vous ne pouvez pas effectuer vous-même le grattage Web, il existe des moyens de contourner ce problème. Mais sache que ça va te coûter de l'argent. Vous pouvez trouver quelqu'un pour faire le scraping pour vous, ou vous pouvez obtenir le service de données premium de sites Web comme Google et Twitter pour partager les données avec vous. Ceux-ci partagent des parties de leurs données en utilisant des API, mais ces appels d'API sont limités par jour. En dehors de cela, des sites Web tels que ceux-ci peuvent être très protecteurs de leurs données. En règle générale, de nombreux sites de ce type ne partagent aucune de leurs données.
Dernières pensées
Avant de conclure, laissez-moi vous dire à haute voix si cela n'a pas déjà été une évidence ; les commandes find(), find_all() sont vos meilleures amies lorsque vous grattez avec BeautifulSoup. Bien qu'il y ait beaucoup plus à couvrir pour maîtriser le grattage de données avec Python, ce guide devrait suffire à ceux d'entre vous qui commencent tout juste.


