Partie 1 : Configuration d'un seul nœud
Aujourd'hui, le stockage électronique de vos documents ou données sur un périphérique de stockage est à la fois simple et rapide, il est également relativement bon marché. En cours d'utilisation est une référence de nom de fichier qui vise à décrire le sujet du document. Alternativement, les données sont conservées dans un système de gestion de base de données (SGBD) comme PostgreSQL, MariaDB ou MongoDB pour ne citer que quelques options. Plusieurs supports de stockage sont connectés localement ou à distance à l'ordinateur, tels qu'une clé USB, un disque dur interne ou externe, un stockage en réseau (NAS), un stockage en nuage ou un GPU/Flash, comme dans un Nvidia V100 [10].
En revanche, le processus inverse, trouver les bons documents dans une collection de documents, est assez complexe. Il nécessite principalement de détecter le format de fichier sans faute, d'indexer le document et d'en extraire les concepts clés (classification de document). C'est là qu'intervient le framework Apache Solr. Il offre une interface pratique pour effectuer les étapes mentionnées - créer un index de documents, accepter les requêtes de recherche, effectuer la recherche proprement dite et renvoyer un résultat de recherche. Apache Solr constitue ainsi le noyau d'une recherche efficace sur une base de données ou un silo de documents.
Dans cet article, vous apprendrez comment fonctionne Apache Solr, comment configurer un seul nœud, indexer des documents, effectuer une recherche et récupérer le résultat.
Les articles de suivi s'appuient sur celui-ci et, dans ceux-ci, nous discutons d'autres cas d'utilisation plus spécifiques tels que l'intégration d'un SGBD PostgreSQL en tant que source de données ou l'équilibrage de charge sur plusieurs nœuds.
À propos du projet Apache Solr
Apache Solr est un framework de moteur de recherche basé sur le puissant serveur d'index de recherche Lucene [2]. Écrit en Java, il est maintenu sous l'égide de l'Apache Software Foundation (ASF) [6]. Il est disponible gratuitement sous la licence Apache 2.
Le sujet « Retrouver des documents et des données » joue un rôle très important dans le monde du logiciel et de nombreux développeurs le traitent de manière intensive. Le site Awesomeopensource [4] répertorie plus de 150 projets open source de moteurs de recherche. Au début de 2021, ElasticSearch [8] et Apache Solr/Lucene sont les deux meilleurs lorsqu'il s'agit de rechercher des ensembles de données plus volumineux. Développer votre moteur de recherche nécessite beaucoup de connaissances, Frank le fait avec la bibliothèque AdvaS Advanced Search [3] basée sur Python depuis 2002.
Configuration d'Apache Solr :
L'installation et le fonctionnement d'Apache Solr ne sont pas compliqués, c'est simplement toute une série d'étapes à réaliser par vos soins. Comptez environ 1 heure pour le résultat de la première requête de données. De plus, Apache Solr n'est pas seulement un projet de loisir mais est également utilisé dans un environnement professionnel. Par conséquent, l'environnement de système d'exploitation choisi est conçu pour une utilisation à long terme.
Comme environnement de base pour cet article, nous utilisons Debian GNU/Linux 11, qui est la prochaine version de Debian (au début de 2021) et devrait être disponible à la mi-2021. Pour ce tutoriel, nous nous attendons à ce que vous l'ayez déjà installé, soit en tant que système natif, dans une machine virtuelle comme VirtualBox, ou un conteneur AWS.
Outre les composants de base, les packages logiciels suivants doivent être installés sur le système :
- Boucle
- Par défaut-java
- Libcommons-cli-java
- Libxerces2-java
- Libtika-java (une bibliothèque du projet Apache Tika [11])
Ces paquets sont des composants standard de Debian GNU/Linux. S'ils ne sont pas encore installés, vous pouvez les post-installer en une seule fois en tant qu'utilisateur avec des droits d'administration, par exemple root ou via sudo, comme suit :
# apt-get install curl default-java libcommons-cli-java libxerces2-java libtika-javaAprès avoir préparé l'environnement, la 2ème étape est l'installation d'Apache Solr. Pour l'instant, Apache Solr n'est pas disponible en tant que paquet Debian standard. Par conséquent, il est nécessaire de récupérer Apache Solr 8.8 de la section de téléchargement du site Web du projet [9] d'abord. Utilisez la commande wget ci-dessous pour le stocker dans le répertoire /tmp de votre système :
$ wget -O /tmp https://téléchargements.apache.org/lucene/solr/8.8.0/solr-8.8.0.tgzLe commutateur -O raccourcit -output-document et permet à wget de stocker le tar récupéré.gz dans le répertoire donné. L'archive a une taille d'environ 190M. Ensuite, décompressez l'archive dans le répertoire /opt à l'aide de tar. En conséquence, vous trouverez deux sous-répertoires - /opt/solr et /opt/solr-8.8.0, alors que /opt/solr est configuré comme un lien symbolique vers ce dernier. Apache Solr est livré avec un script de configuration que vous exécutez ensuite, il est le suivant :
# /opt/solr-8.8.0/bin/install_solr_service.shCela se traduit par la création de l'utilisateur Linux solr s'exécute dans le service Solr plus son répertoire personnel sous /var/solr établit le service Solr, ajouté avec ses nœuds correspondants, et démarre le service Solr sur le port 8983. Ce sont les valeurs par défaut. Si vous n'êtes pas satisfait d'eux, vous pouvez les modifier pendant l'installation ou même plus tard puisque le script d'installation accepte les commutateurs correspondants pour les ajustements de configuration. Nous vous recommandons de consulter la documentation Apache Solr concernant ces paramètres.
Le logiciel Solr est organisé dans les répertoires suivants :
- poubelle
contient les binaires et les fichiers Solr pour exécuter Solr en tant que service - contrib
bibliothèques Solr externes telles que le gestionnaire d'importation de données et les bibliothèques Lucene - dist
bibliothèques Solr internes - documents
lien vers la documentation Solr disponible en ligne - Exemple
exemples d'ensembles de données ou plusieurs cas d'utilisation/scénarios - licences
licences logicielles pour les différents composants Solr - serveur
fichiers de configuration du serveur, tels que serveur/etc pour les services et les ports
Plus en détail, vous pouvez lire sur ces répertoires dans la documentation Apache Solr [12].
Gestion d'Apache Solr :
Apache Solr s'exécute en tant que service en arrière-plan. Vous pouvez le démarrer de deux manières, soit en utilisant systemctl (première ligne) en tant qu'utilisateur avec des autorisations administratives, soit directement depuis le répertoire Solr (deuxième ligne). Nous listons les deux commandes de terminal ci-dessous :
# systemctl start solr$ solr/bin/solr start
L'arrêt d'Apache Solr se fait de la même manière :
# systemctl stop solr$ solr/bin/solr arrêt
Il en va de même pour le redémarrage du service Apache Solr :
# systemctl redémarrer solr$ solr/bin/solr redémarrer
De plus, l'état du processus Apache Solr peut être affiché comme suit :
# systemctl status solr$ solr/bin/solr statut
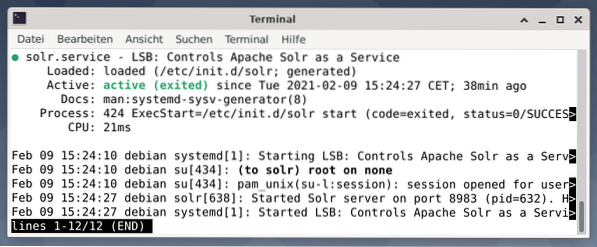
La sortie répertorie le fichier de service qui a été démarré, à la fois l'horodatage et les messages de journal correspondants. La figure ci-dessous montre que le service Apache Solr a été démarré sur le port 8983 avec le processus 632. Le processus s'exécute avec succès pendant 38 minutes.
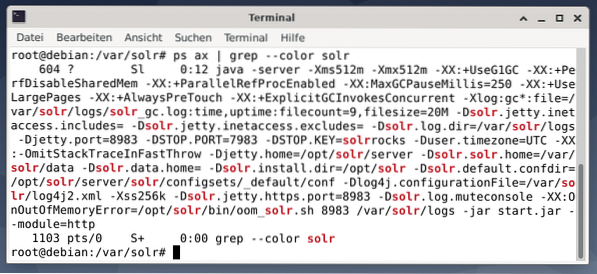
Pour voir si le processus Apache Solr est actif, vous pouvez également effectuer une vérification croisée à l'aide de la commande ps en combinaison avec grep. Cela limite la sortie ps à tous les processus Apache Solr actuellement actifs.
# ps hache | grep --color solrLa figure ci-dessous le montre pour un seul processus. Vous voyez l'appel de Java qui est accompagné d'une liste de paramètres, par exemple l'utilisation de la mémoire (512M) les ports à écouter sur 8983 pour les requêtes, 7983 pour les requêtes d'arrêt, et le type de connexion (http).
Ajout d'utilisateurs :
Les processus Apache Solr s'exécutent avec un utilisateur spécifique nommé solr. Cet utilisateur est utile pour gérer les processus Solr, télécharger des données et envoyer des demandes. Lors de la configuration, l'utilisateur solr n'a pas de mot de passe et devrait en avoir un pour se connecter pour continuer. Définissez un mot de passe pour l'utilisateur solr comme l'utilisateur root, il est affiché comme suit :
# passwd solrAdministration de Solr :
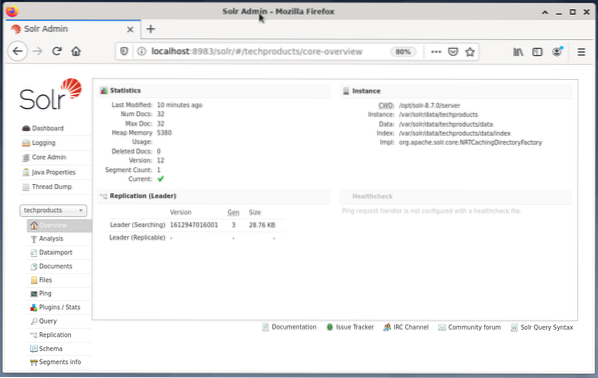
La gestion d'Apache Solr se fait à l'aide du tableau de bord Solr. Ceci est accessible via un navigateur Web à partir de http://localhost:8983/solr. La figure ci-dessous montre la vue principale.
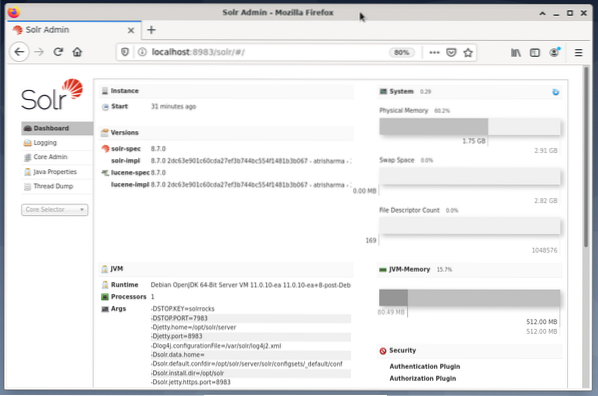
Sur la gauche, vous voyez le menu principal qui vous mène aux sous-sections pour la journalisation, l'administration des cœurs Solr, la configuration Java et les informations d'état. Choisissez le noyau souhaité à l'aide de la boîte de sélection sous le menu. Sur le côté droit du menu, les informations correspondantes sont affichées. L'entrée du menu Tableau de bord affiche plus de détails concernant le processus Apache Solr, ainsi que la charge actuelle et l'utilisation de la mémoire.
Sachez que le contenu du Dashboard change en fonction du nombre de cœurs Solr, et des documents qui ont été indexés. Les modifications affectent à la fois les éléments de menu et les informations correspondantes qui sont visibles sur la droite.
Comprendre le fonctionnement des moteurs de recherche :
En termes simples, les moteurs de recherche analysent les documents, les catégorisent et vous permettent de faire une recherche en fonction de leur catégorisation. Fondamentalement, le processus se compose de trois étapes, appelées exploration, indexation et classement [13].
Rampant est la première étape et décrit un processus par lequel le contenu nouveau et mis à jour est collecté. Le moteur de recherche utilise des robots également appelés spiders ou crawlers, d'où le terme crawling pour parcourir les documents disponibles.
La deuxième étape est appelée indexage. Le contenu précédemment collecté est rendu consultable en transformant les documents originaux dans un format que le moteur de recherche comprend. Les mots-clés et les concepts sont extraits et stockés dans des bases de données (massives).
La troisième étape est appelée classement et décrit le processus de tri des résultats de la recherche en fonction de leur pertinence avec une requête de recherche. Il est courant d'afficher les résultats par ordre décroissant afin que le résultat le plus pertinent par rapport à la requête du chercheur arrive en premier.
Apache Solr fonctionne de manière similaire au processus en trois étapes décrit précédemment. Comme le moteur de recherche populaire Google, Apache Solr utilise une séquence de collecte, de stockage et d'indexation de documents provenant de différentes sources et les rend disponibles/recherchables en temps quasi réel.
Apache Solr utilise différentes manières d'indexer les documents, notamment les suivantes [14] :
- Utilisation d'un gestionnaire de demande d'index lors du téléchargement des documents directement sur Solr. Ces documents doivent être au format JSON, XML/XSLT ou CSV.
- Utilisation du gestionnaire de requêtes d'extraction (cellule Solr). Les documents doivent être au format PDF ou Office, qui sont pris en charge par Apache Tika.
- Utilisation du gestionnaire d'importation de données, qui transporte les données d'une base de données et les catalogue à l'aide de noms de colonnes. Le gestionnaire d'importation de données récupère les données des e-mails, des flux RSS, des données XML, des bases de données et des fichiers texte brut en tant que sources.
Un gestionnaire de requêtes est utilisé dans Apache Solr lorsqu'une requête de recherche est envoyée. Le gestionnaire de requêtes analyse la requête donnée sur la base du même concept du gestionnaire d'index pour faire correspondre la requête et les documents précédemment indexés. Les matchs sont classés en fonction de leur pertinence ou de leur pertinence. Un bref exemple d'interrogation est illustré ci-dessous.
Téléchargement de documents :
Par souci de simplicité, nous utilisons un exemple de jeu de données pour l'exemple suivant qui est déjà fourni par Apache Solr. Le téléchargement des documents se fait en tant qu'utilisateur solr. L'étape 1 est la création d'un noyau avec le nom techproducts (pour un certain nombre d'articles technologiques).
$ solr/bin/solr create -c techproducts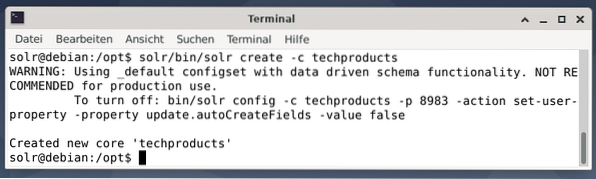
Tout va bien si vous voyez le message « Créé un nouveau noyau 'techproducts' ». L'étape 2 consiste à ajouter des données (données XML de exampledocs) aux produits technologiques de base précédemment créés. En cours d'utilisation est l'outil post qui est paramétré par -c (nom du noyau) et les documents à télécharger.
$ solr/bin/post -c techproducts solr/example/exampledocs/*.xmlCela donnera le résultat indiqué ci-dessous et contiendra l'intégralité de l'appel ainsi que les 14 documents qui ont été indexés.
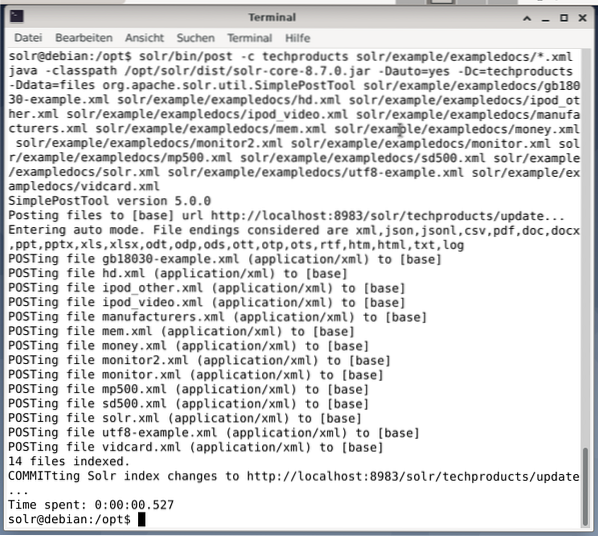
De plus, le tableau de bord montre les changements. Une nouvelle entrée nommée techproducts est visible dans le menu déroulant sur le côté gauche, et le nombre de documents correspondants modifié sur le côté droit. Malheureusement, une vue détaillée des ensembles de données brutes n'est pas possible.
Au cas où le noyau/la collection doit être supprimé, utilisez la commande suivante :
$ solr/bin/solr delete -c produits techInterrogation des données :
Apache Solr propose deux interfaces pour interroger les données : via le tableau de bord Web et la ligne de commande. Nous expliquerons les deux méthodes ci-dessous.
L'envoi de requêtes via le tableau de bord Solr se fait comme suit :
- Choisissez le nœud techproducts dans le menu déroulant.
- Choisissez l'entrée Requête dans le menu sous le menu déroulant.
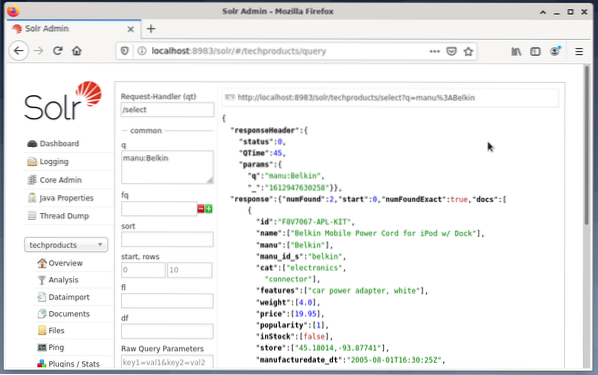
Les champs de saisie s'affichent sur le côté droit pour formuler la requête comme le gestionnaire de requêtes (qt), la requête (q) et l'ordre de tri (sort). - Choisissez le champ de saisie Requête et modifiez le contenu de l'entrée de "*:*" à "manu:Belkin". Cela limite la recherche de « tous les champs avec toutes les entrées » à « ensembles de données portant le nom Belkin dans le champ manu ». Dans ce cas, le nom manu abrège le fabricant dans l'exemple de jeu de données.
- Ensuite, appuyez sur le bouton avec Exécuter la requête. Le résultat est une requête HTTP imprimée en haut et un résultat de la requête de recherche au format de données JSON ci-dessous.
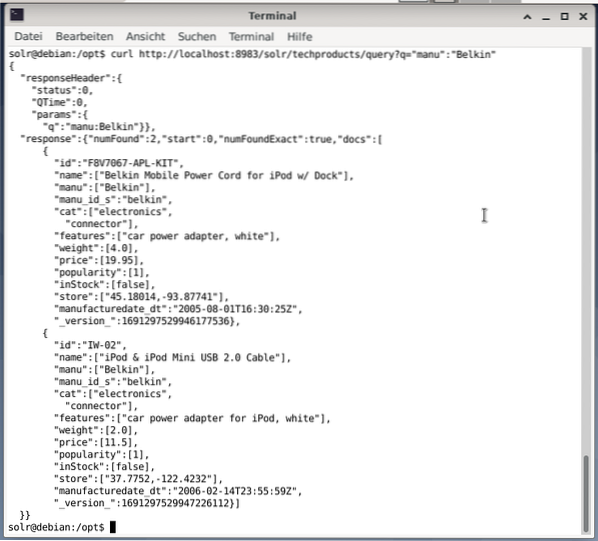
La ligne de commande accepte la même requête que dans le tableau de bord. La différence est que vous devez connaître le nom des champs de requête. Afin d'envoyer la même requête que ci-dessus, vous devez exécuter la commande suivante dans un terminal :
$ bouclehttp://localhost:8983/solr/techproducts/query?q=”manu”:”Belkin
La sortie est au format JSON, comme indiqué ci-dessous. Le résultat se compose d'un en-tête de réponse et de la réponse réelle. La réponse se compose de deux ensembles de données.
Emballer:
Toutes nos félicitations! Vous avez franchi la première étape avec succès. L'infrastructure de base est configurée et vous avez appris à télécharger et à interroger des documents.
La prochaine étape couvrira comment affiner la requête, formuler des requêtes plus complexes et comprendre les différents formulaires Web fournis par la page de requête Apache Solr. Nous verrons également comment post-traiter le résultat de la recherche à l'aide de différents formats de sortie tels que XML, CSV et JSON.
À propos des auteurs:
Jacqui Kabeta est environnementaliste, chercheuse passionnée, formatrice et mentor. Dans plusieurs pays africains, elle a travaillé dans l'industrie informatique et les environnements d'ONG.
Frank Hofmann est développeur informatique, formateur et auteur et préfère travailler depuis Berlin, Genève et Cape Town. Co-auteur du livre de gestion des paquets Debian disponible auprès de dpmb.organisation
- [1] Apache Solr, https://lucene.apache.org/solr/
- [2] Bibliothèque de recherche Lucene, https://lucene.apache.org/
- [3] Recherche avancée AdvaS, https://pypi.org/project/AdvaS-Advanced-Search/
- [4] Les 165 meilleurs projets open source de moteurs de recherche, https://awesomeopensource.com/projects/moteur-de-recherche
- [5] ElasticSearch, https://www.élastique.co/de/elasticsearch/
- [6]Apache Software Foundation (ASF), https://www.apache.org/
- [7]FESS, https://fess.bibliothèques de codes.org/index.html
- [8] ElasticSearch, https://www.élastique.code/
- [9] Apache Solr, section Téléchargement, https://lucene.apache.org/solr/téléchargements.htm
- [10] Nvidia V100, https://www.nvidia.fr/en-us/data-center/v100/
- [11] Apache Tika, https://tika.apache.org/
- [12] Disposition du répertoire Apache Solr, https://lucene.apache.org/solr/guide/8_8/installation-solr.html#directory-layout
- [13] Fonctionnement des moteurs de recherche : exploration, indexation et classement. Le guide du débutant en SEO https://moz.com/beginners-guide-to-seo/how-search-engines-operate
- [14] Premiers pas avec Apache Solr, https://sematext.com/guides/solr/#:~:text=Solr%20works%20by%20gathering%2C%20storing,with%20huge%20volumes%20of%20data


