Qu'est-ce qu'Apache Solr
Apache Solr est l'une des bases de données NoSQL les plus populaires qui peut être utilisée pour stocker des données et les interroger en temps quasi réel. Il est basé sur Apache Lucene et est écrit en Java. Tout comme Elasticsearch, il prend en charge les requêtes de base de données via les API REST. Cela signifie que nous pouvons utiliser de simples appels HTTP et utiliser des méthodes HTTP telles que GET, POST, PUT, DELETE, etc. accéder aux données. Il fournit également une option pour obtenir des données sous forme de XML ou JSON via les API REST.
Architecture : Apache Solr
Avant de pouvoir commencer à travailler avec Apache Solr, nous devons comprendre les composants qui constituent Apache Solr. Jetons un coup d'œil à certains composants qu'il possède :
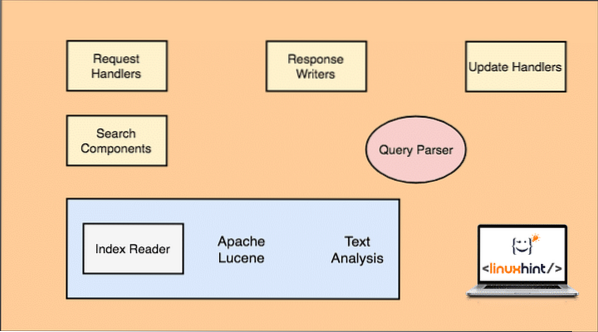
Architecture d'Apache Solr
Notez que seuls les principaux composants de Solr sont illustrés dans la figure ci-dessus. Comprenons également leur fonctionnalité ici :
- Gestionnaires de demandes: Les requêtes qu'un client fait à Solr sont gérées par un gestionnaire de requêtes. La demande peut aller de l'ajout d'un nouvel enregistrement à la mise à jour d'un index dans Solr. Les gestionnaires identifient le type de requête à partir de la méthode HTTP utilisée avec le mappage de requête.
- Composant de recherche: C'est l'un des composants les plus importants pour lesquels Solr est connu. Le composant de recherche s'occupe d'effectuer des opérations liées à la recherche telles que le flou, les vérifications orthographiques, les requêtes de termes, etc.
- Analyseur de requête: c'est le composant qui analyse réellement la requête qu'un client passe au gestionnaire de requêtes et divise une requête en plusieurs parties qui peuvent être comprises par le moteur sous-jacent
- Rédacteur de réponse: Ce composant est chargé de gérer le format de sortie des requêtes passées au moteur. Response Writer nous permet de fournir une sortie dans divers formats tels que XML, JSON, etc.
- Analyseur/Tokenizer: Lucene Engine comprend les requêtes sous la forme de plusieurs jetons. Solr analyse la requête, la divise en plusieurs jetons et la transmet au moteur Lucene.
- Processeur de demande de mise à jour: lorsqu'une requête est exécutée et qu'elle effectue des opérations telles que la mise à jour d'un index et des données qui lui sont associées, le composant Update Request Processor est chargé de gérer les données de l'index et de les modifier.
Premiers pas avec Apache Solr
Pour commencer à utiliser Apache Solr, il doit être installé sur la machine. Pour ce faire, lisez Installer Apache Solr sur Ubuntu.
Assurez-vous d'avoir une installation Solr active si vous voulez essayer des exemples que nous présenterons plus tard dans la leçon et la page d'administration est accessible sur localhost :
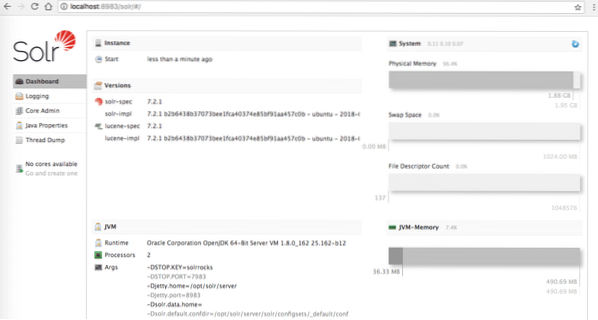
Page d'accueil d'Apache Solr
Insertion de données
Pour commencer, considérons une Collection dans Solr que nous appelons linux_hint_collection. Il n'est pas nécessaire de définir explicitement cette collection car lorsque nous insérons le premier objet, la collection sera faite automatiquement. Essayons notre premier appel d'API REST pour insérer un nouvel objet dans la collection nommée linux_hint_collection.
Insertion de données
curl -X POST -H 'Type de contenu : application/json''http://localhost:8983/solr/linux_hint_collection/update/json/docs' --data-binary '
"id": "iduye",
"nom": "Shubham"
'
Voici ce que nous obtenons avec cette commande :

Commande pour insérer des données dans Solr
Les données peuvent également être insérées à l'aide de la page d'accueil Solr que nous avons examinée plus tôt. Essayons ceci ici pour que les choses soient claires :
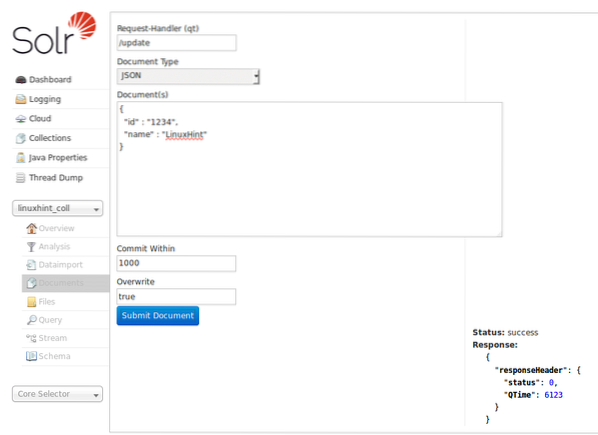
Insérer des données via la page d'accueil Solr
Comme Solr a un excellent moyen d'interaction avec les API HTTP RESTful, nous allons désormais démontrer l'interaction de la base de données en utilisant les mêmes API et ne nous concentrerons pas beaucoup sur l'insertion de données via la page Web Solr.
Lister toutes les collections
Nous pouvons également répertorier toutes les collections dans Apache Solr à l'aide d'une API REST. Voici la commande que nous pouvons utiliser :
Lister toutes les collections
curl http://localhost:8983/solr/admin/collections?actions=LIST&wt=jsonVoyons le résultat de cette commande :
Nous voyons ici deux collections qui existent dans notre installation Solr.
Obtenir l'objet par ID
Voyons maintenant comment OBTENIR des données de la collection Solr avec un identifiant spécifique. Voici la commande API REST :
Obtenir l'objet par ID
curl http://localhost:8983/solr/linux_hint_collection/get?id=iduyeVoici ce que nous obtenons avec cette commande :
Obtenir toutes les données
Dans notre dernière API REST, nous avons interrogé des données à l'aide d'un identifiant spécifique. Cette fois, nous obtiendrons toutes les données présentes dans notre collection Solr.
Obtenir l'objet par ID
curl http://localhost:8983/solr/linux_hint_collection/select?q=*:*Voici ce que nous obtenons avec cette commande :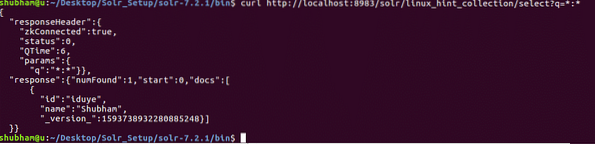
Notez que nous avons utilisé '*:*' dans le paramètre de requête. Ceci spécifie que Solr doit retourner toutes les données présentes dans la collection. Même si nous avons spécifié que toutes les données doivent être renvoyées, Solr comprend que la collection peut contenir une grande quantité de données et donc, il ne retournera que les 10 premiers documents.
Suppression de toutes les données
Jusqu'à présent, toutes les API que nous avons essayées utilisaient un format JSON. Cette fois, nous allons essayer le format de requête XML. L'utilisation du format XML est extrêmement similaire à JSON car XML est également autodescriptif.
Essayons une commande pour supprimer toutes les données que nous avons dans notre collection.
Suppression de toutes les données
curl "http://localhost:8983/solr/linux_hint_collection/update?commit=true" -H "Type de contenu : text/xml" --data-binary "*:*"Voici ce que nous obtenons avec cette commande :

Supprimer toutes les données à l'aide d'une requête XML
Maintenant, si nous essayons à nouveau d'obtenir toutes les données, nous verrons qu'aucune donnée n'est disponible maintenant :

Obtenir toutes les données
Nombre total d'objets
Pour une commande CURL finale, voyons une commande avec laquelle on peut trouver le nombre d'objets qui sont présents dans un index. Voici la commande pour le même :
Nombre total d'objets
curl http://localhost:8983/solr/linux_hint_collection/query?debug=query&q=*:*Voici ce que nous obtenons avec cette commande :
Compter le nombre d'objets
Conclusion
Dans cette leçon, nous avons examiné comment utiliser Apache Solr et transmettre des requêtes à l'aide de curl aux formats JSON et XML. Nous avons également vu que le panneau d'administration de Solr est utile de la même manière que toutes les commandes curl que nous avons étudiées.


