TensorFlow a trouvé une immense utilisation dans le domaine de l'apprentissage automatique, précisément parce que l'apprentissage automatique implique beaucoup de calculs et est utilisé comme technique de résolution de problèmes généralisée. Et bien que nous interagissions avec lui en utilisant Python, il a des interfaces pour d'autres langages comme Go, Node.js et même C#.
Tensorflow est comme une boîte noire qui cache toutes les subtilités mathématiques à l'intérieur et le développeur appelle simplement les bonnes fonctions pour résoudre un problème. Mais quel problème?
Apprentissage automatique (ML)
Supposons que vous concevez un bot pour jouer aux échecs. En raison de la façon dont les échecs sont conçus, de la façon dont les pièces se déplacent et de l'objectif bien défini du jeu, il est tout à fait possible d'écrire un programme qui jouerait extrêmement bien au jeu. En fait, il déjouerait toute la race humaine aux échecs. Il saurait exactement quel mouvement il doit effectuer étant donné l'état de toutes les pièces sur le plateau.
Cependant, un tel programme ne peut jouer aux échecs que. Les règles du jeu sont intégrées dans la logique du code et tout ce que fait le programme est d'exécuter cette logique de manière rigoureuse et plus précise que n'importe quel humain pourrait le faire. Ce n'est pas un algorithme à usage général que vous pouvez utiliser pour concevoir n'importe quel bot de jeu.
Avec le machine learning, le paradigme change et les algorithmes deviennent de plus en plus polyvalents.
L'idée est simple, elle commence par définir un problème de classification. Par exemple, vous souhaitez automatiser le processus d'identification des espèces d'araignées. Les espèces que vous connaissez sont les différentes classes (à ne pas confondre avec les classes taxonomiques) et le but de l'algorithme est de trier une nouvelle image inconnue dans l'une de ces classes.
Ici, la première étape pour l'humain serait de déterminer les caractéristiques de diverses araignées individuelles. Nous fournirions des données sur la longueur, la largeur, la masse corporelle et la couleur des araignées individuelles ainsi que les espèces auxquelles elles appartiennent :
| Longueur | Largeur | Masse | Couleur | Texture | Espèce |
| 5 | 3 | 12 | marron | lisse | Papa longues jambes |
| dix | 8 | 28 | Marron noir | poilu | Tarentule |
Le fait de disposer d'une vaste collection de ces données d'araignée individuelles sera utilisé pour « entraîner » l'algorithme et un autre ensemble de données similaire sera utilisé pour tester l'algorithme afin de voir dans quelle mesure il se comporte par rapport à de nouvelles informations qu'il n'a jamais rencontrées auparavant, mais dont nous connaissons déjà le Réponds à.
L'algorithme démarrera de manière aléatoire. C'est-à-dire que chaque araignée, quelles que soient ses caractéristiques, serait classée comme n'importe quelle espèce. S'il y a 10 espèces différentes dans notre ensemble de données, alors cet algorithme naïf recevrait la classification correcte environ 1/10ème du temps à cause de la pure chance.
Mais alors l'aspect de l'apprentissage automatique commencerait à prendre le dessus. Cela commencerait à associer certaines caractéristiques à certains résultats. Par exemple, les araignées velues sont probablement des tarentules, de même que les plus grosses araignées. Ainsi, chaque fois qu'une nouvelle araignée grande et velue apparaît, une probabilité plus élevée d'être une tarentule lui sera attribuée. Remarquez que nous travaillons toujours avec des probabilités, c'est parce que nous travaillons intrinsèquement avec un algorithme probabiliste.
La partie apprentissage fonctionne en modifiant les probabilités. Initialement, l'algorithme commence par attribuer au hasard des étiquettes d'« espèce » à des individus en faisant des corrélations aléatoires comme, être « poilu » et être « papa longues jambes ». Lorsqu'il établit une telle corrélation et que l'ensemble de données d'apprentissage ne semble pas être d'accord avec elle, cette hypothèse est abandonnée.
De même, lorsqu'une corrélation fonctionne bien à travers plusieurs exemples, elle se renforce à chaque fois. Cette méthode de trébucher vers la vérité est remarquablement efficace, grâce à beaucoup de subtilités mathématiques dont, en tant que débutant, vous ne voudriez pas vous soucier.
TensorFlow et formation de votre propre classificateur de fleurs
TensorFlow va encore plus loin dans l'idée de l'apprentissage automatique. Dans l'exemple ci-dessus, vous étiez chargé de déterminer les caractéristiques qui distinguent une espèce d'araignée d'une autre. Nous avons dû mesurer minutieusement les araignées individuelles et créer des centaines de tels enregistrements.
Mais nous pouvons faire mieux, en fournissant simplement des données d'image brutes à l'algorithme, nous pouvons laisser l'algorithme trouver des motifs et comprendre diverses choses à propos de l'image, comme reconnaître les formes de l'image, puis comprendre quelle est la texture des différentes surfaces, la couleur , etc., etc. C'est la notion de départ de la vision par ordinateur et vous pouvez également l'utiliser pour d'autres types d'entrées, comme les signaux audio et la formation de votre algorithme pour la reconnaissance vocale. Tout cela relève du terme générique de « Deep Learning » où l'apprentissage automatique est poussé à son extrême logique.
Cet ensemble généralisé de notions peut ensuite être spécialisé lorsqu'il s'agit de traiter de nombreuses images de fleurs et de les catégoriser.
Dans l'exemple ci-dessous, nous utiliserons un Python2.7 front-end pour s'interfacer avec TensorFlow et nous utiliserons pip (pas pip3) pour installer TensorFlow. Le support de Python 3 est encore un peu buggé.
Pour créer votre propre classificateur d'images, à l'aide de TensorFlow, installons-le d'abord en utilisant pépin:
$pip installer tensorflowEnsuite, nous devons cloner le tensorflow-for-poets-2 référentiel git. C'est un très bon point de départ pour deux raisons :
- C'est simple et facile à utiliser
- Il est pré-formé dans une certaine mesure. Par exemple, le classificateur de fleurs est déjà formé pour comprendre quelle texture il regarde et quelles formes il regarde donc il est moins gourmand en calculs.
Récupérons le référentiel :
$git clone https://github.com/googlecodelabs/tensorflow-for-poets-2$cd tensorflow-for-poets-2
Cela va être notre répertoire de travail, donc toutes les commandes doivent être émises à partir de celui-ci, à partir de maintenant.
Nous devons encore entraîner l'algorithme pour le problème spécifique de la reconnaissance des fleurs, pour cela nous avons besoin de données d'entraînement, alors voyons ça :
$curl http://télécharger.tensorflow.org/example_images/flower_photos.tgz| tar xz -C tf_files
Le répertoire… ./tensorflow-for-poets-2/tf_files contient une tonne de ces images correctement étiquetées et prêtes à être utilisées. Les images serviront à deux fins différentes :
- Formation au programme ML
- Tester le programme ML
Vous pouvez vérifier le contenu du dossier fichiers_tf et ici vous constaterez que nous nous limitons à seulement 5 catégories de fleurs, à savoir les marguerites, les tulipes, les tournesols, les pissenlits et les roses.
Entraîner le modèle
Vous pouvez commencer le processus d'apprentissage en définissant d'abord les constantes suivantes pour redimensionner toutes les images d'entrée dans une taille standard et en utilisant une architecture mobilenet légère :
$IMAGE_SIZE=224$ARCHITECTURE="mobilenet_0.50_$IMAGE_SIZE"
Appelez ensuite le script python en exécutant la commande :
$python -m scripts.recycler \--bottleneck_dir=tf_files/bottlenecks \
--how_many_training_steps=500 \
--model_dir=tf_files/models/ \
--summaries_dir=tf_files/training_summaries/"$ARCHITECTURE" \
--output_graph=tf_files/retrained_graph.pb \
--output_labels=tf_files/retrained_labels.SMS \
--architecture="$ARCHITECTURE" \
--image_dir=tf_files/flower_photos
Bien qu'il y ait beaucoup d'options spécifiées ici, la plupart d'entre elles spécifient vos répertoires de données d'entrée et le nombre d'itérations, ainsi que les fichiers de sortie où les informations sur le nouveau modèle seraient stockées. Cela ne devrait pas prendre plus de 20 minutes pour s'exécuter sur un ordinateur portable médiocre.
Une fois que le script a terminé l'entraînement et les tests, il vous donnera une estimation de la précision du modèle entraîné, qui dans notre cas était légèrement supérieure à 90 %.
Utilisation du modèle entraîné
Vous êtes maintenant prêt à utiliser ce modèle pour la reconnaissance d'image de toute nouvelle image d'une fleur. Nous utiliserons cette image :

Le visage du tournesol est à peine visible et c'est un grand défi pour notre modèle :
Pour obtenir cette image à partir de Wikimedia Commons, utilisez wget :
$wget https://upload.wikimédia.org/wikipedia/commons/2/28/Sunflower_head_2011_G1.jpg$mv Tournesol_head_2011_G1.jpg tf_files/inconnu.jpg
Il est enregistré sous inconnu.jpg sous le fichiers_tf sous-répertoire.
Maintenant, pour le moment de vérité, nous allons voir ce que notre modèle a à dire sur cette image.Pour ce faire, nous invoquons le label_image scénario:
$python -m scripts.label_image --graph=tf_files/retrained_graph.pb --image=fichiers_tf/inconnu.jpg
Vous obtiendrez une sortie similaire à celle-ci :
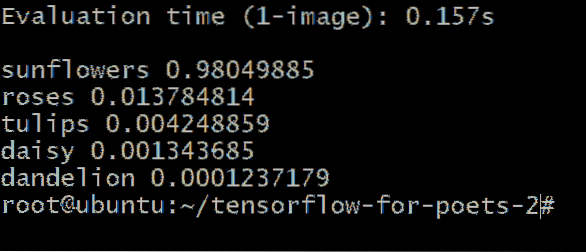
Les nombres à côté du type de fleur représentent la probabilité que notre image inconnue appartienne à cette catégorie. Par exemple, c'est 98.04% certain que l'image est d'un tournesol et il n'y en a que 1.37% de chance que ce soit une rose.
Conclusion
Même avec des ressources de calcul très médiocres, nous constatons une précision stupéfiante dans l'identification des images. Cela démontre clairement la puissance et la flexibilité de TensorFlow.
À partir de là, vous pouvez commencer à expérimenter divers autres types d'entrées ou essayer de commencer à écrire votre propre application différente en utilisant Python et TensorFlow. Si vous voulez connaître un peu mieux le fonctionnement interne de l'apprentissage automatique, voici une façon interactive de le faire.

