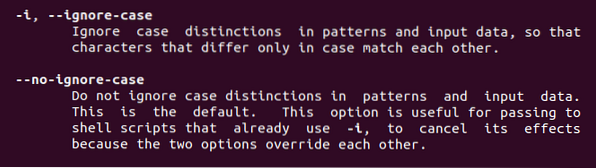
A partir de cette commande, nous allons trouver deux fonctionnalités décrites ci-dessus. -Je veux dire ignorer la casse, partout où ce mot-clé est utilisé, l'affection de la casse est supprimée.
Prérequis
Pour remplir la fonction de cette fonctionnalité dans le système d'exploitation Linux, nous devons avoir un système d'exploitation Linux installé. Après la configuration, vous fournirez les informations utilisateur requises, à l'aide desquelles l'utilisateur sera connecté. De plus, lorsque le nom d'utilisateur et le mot de passe sont fournis, l'utilisateur pourra accéder à toutes les fonctionnalités intégrées du système d'exploitation. Enfin, une fois le bureau accédé, vous devez accéder au terminal, car des commandes doivent y être exécutées.
Exemple 1:
Dans cet exemple, nous verrons comment grep aide à éviter la sensibilité à la casse. Considérons un fichier nommé files11.SMS. Le fichier contient les données suivantes : comme vous pouvez le voir, le mot mangue s'écrit de différentes manières, certains mots sont en majuscules et d'autres en minuscules. En utilisant la commande cat nous afficherons les données du fichier.
$ cat files11.SMS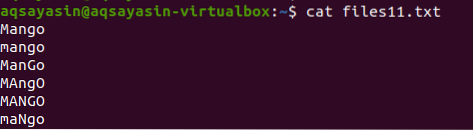
Une fois la commande utilisée pour afficher les données, on peut observer que le seul mot qui correspond à la casse de la lettre présente dans la commande est affiché. Toutes les lettres sont en minuscules.
$ grep fichiers de mangue11.SMS
Maintenant, pour comprendre le concept d'insensibilité à la casse, nous utiliserons "-I" dans la commande pour gérer la sensibilité à la casse en fournissant toutes les données présentes dans le fichier, les correspondances avec la chaîne présente à l'intérieur de la commande.
$ grep -I fichiers de mangue11.SMS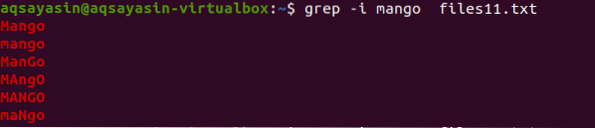
À partir de la sortie, vous saurez que toutes les données qui correspondent au mot "mangue" sont affichées soit avec des mots écrits en majuscules et d'autres en minuscules.
Exemple 2
Cet exemple ressemble au premier, la différence est qu'un seul mot est obtenu. Cette commande aide à obtenir la chaîne entière en la faisant correspondre avec le mot fourni dans la commande. Ayons un fichier filea.SMS. par exemple, nous voulons récupérer un enregistrement en fonction de la correspondance donnée.
$ chat fichiera.SMS
Appliquez maintenant la même commande pour ignorer la casse et décrire la sortie. Le mot technique est affiché en excluant la casse pour le rendre sensible à la casse.

Exemple 3
Une autre méthode d'utilisation de grep pour ignorer la casse consiste à introduire d'abord un nom de fichier, puis à appliquer la commande -I avec grep après « | » opérateur. Cat est utilisé en conjonction avec « | ». Ayons un fichier nommé file24.SMS. par exemple.
$ Fichier de chat24.txt | grep -I "Aqsa"Cette commande récupère le mot « Aqsa » en majuscule et en minuscule.

Exemple 4
Vers un autre exemple. Ici, nous allons afficher les données du fichier contenant le mot "mon". Ici la recherche se fait en introduisant un répertoire donc la commande va trier le mot dans tous les fichiers ayant l'extension .txt dans le système.
$ grep -I mon /home/aqsayasin/*.SMS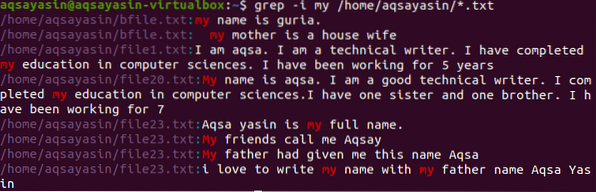
L'image ci-dessus montre la sortie obtenue à partir de la commande. « mon » mot est surligné, c'est-à-dire dans les deux cas. Certains fichiers le contiennent en minuscules tandis que d'autres l'ont en majuscules. L'adresse des fichiers et les noms de fichiers sont également affichés.
Exemple 5
Cet exemple peut être appliqué au répertoire contenant tous les fichiers présents. Des limitations seront appliquées pour afficher le résultat spécifique qui correspond au mot que nous avons défini dans la commande. Le mot "est" est utilisé pour la recherche dans tous les fichiers présents dans le système.
$ grep -I est /home/aqsayasin/file*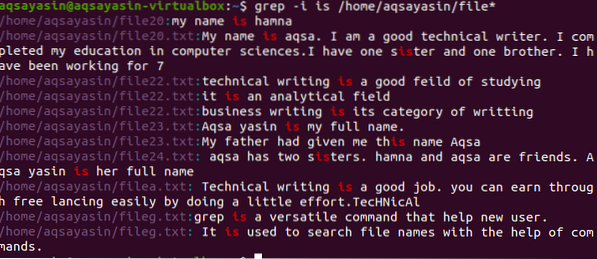
La sortie affiche des chaînes entières contenant le mot correspondant. Comme "est" est écrit séparément ou combiné dans un autre mot i.e. sœur.
Exemple 6
La commande suivante montre comment -iw fonctionne ensemble dans la commande. D'ailleurs ici, la recherche se fait à travers deux mots dans un seul fichier. La barre oblique inverse et « | » sont utilisés pour décrire deux mots dans un fichier tandis que -w est utilisé pour la correspondance exacte du mot respectif dans le fichier.
$ grep -iw 'hamna\|maison' fichier21.SMS$ grep 'hamn\|house' file21.SMS

-Je vais ignorer la sensibilité à la casse. Dans l'exemple ci-dessus, nous pouvons voir que la présence de -w avec -I, permet à une maison dans la première commande de ne pas être considérée car -w permet la correspondance exacte. Dans la deuxième commande, nous avons supprimé les deux -iw, donc les deux mots sont affichés après la correspondance dans la chaîne.
Exemple 7
Plus d'un mot est recherché en appliquant une méthode différente. Les deux mots sont recherchés dans le même fichier, ces mots sont « job » et « gagner ». Earn est extrait du mot learning, notez également que chaque mot est séparé du mot clé -e.
$ grep -I -e job -e gagner filea.SMS
L'image ci-dessus montre les chaînes entières dans un paragraphe concernant les mots présents dans la commande. Comme les exemples ci-dessus, -J'ai ignoré toute discrimination de cas des mots emploi et gagne.
Exemple 8
Dans cet exemple, la recherche de deux mots présents dans tous les fichiers du .extension txt. Ces deux mots sont séparés par -e, car -e est la bonne façon de séparer deux mots. La sortie obtenue aura les deux mots affichés dans tous les fichiers d'extension de texte. L'adresse complète du fichier est obtenue et s'affiche. -J'ignorerai la sensibilité à la casse et afficherai les deux mots présents dans tous les fichiers.
$ grep -I -e job -e gagne /home/aqsayasin/*.SMS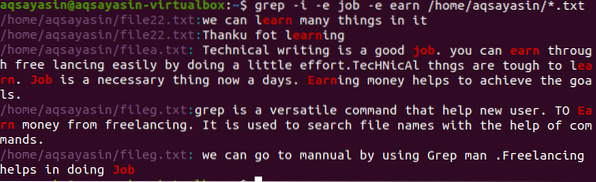
Conclusion
Dans ce guide, nous avons utilisé l'exemple le plus simple pour développer le concept de sensibilité à la casse. Nous avons fait de notre mieux pour passer en revue chaque aspect afin d'améliorer les connaissances concernant grep.


