Cet article vous montre comment trouver des doublons dans les données et supprimer les doublons à l'aide des fonctions Python de Pandas.
Dans cet article, nous avons pris un ensemble de données de la population de différents États des États-Unis, qui est disponible dans un .format de fichier csv. Nous allons lire le .csv pour afficher le contenu original de ce fichier, comme suit :
importer des pandas au format pddf_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
imprimer (état_df)
Dans la capture d'écran suivante, vous pouvez voir le contenu en double de ce fichier :
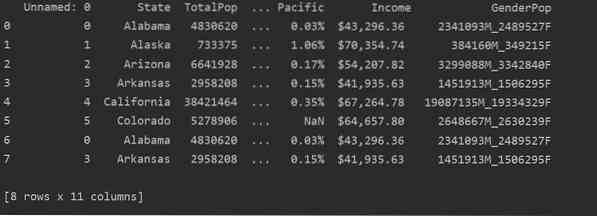
Identification des doublons dans Pandas Python
Il est nécessaire de déterminer si les données que vous utilisez ont des lignes dupliquées. Pour vérifier la duplication des données, vous pouvez utiliser l'une des méthodes décrites dans les sections suivantes.
Méthode 1 :
Lisez le fichier csv et transmettez-le dans le bloc de données. Ensuite, identifiez les lignes en double à l'aide de la dupliqué() une fonction. Enfin, utilisez l'instruction print pour afficher les lignes en double.
importer des pandas au format pddf_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.dupliqué()]
print("\n\nLignes en double : \n ".format(Dup_Rows))
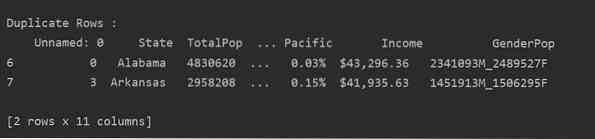
Méthode 2 :
En utilisant cette méthode, le est_dupliqué colonne sera ajoutée à la fin du tableau et marquée comme « True » dans le cas de lignes dupliquées.
importer des pandas au format pddf_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
df_state["is_duplicate"]= df_state.dupliqué()
print("\n ".format(df_state))
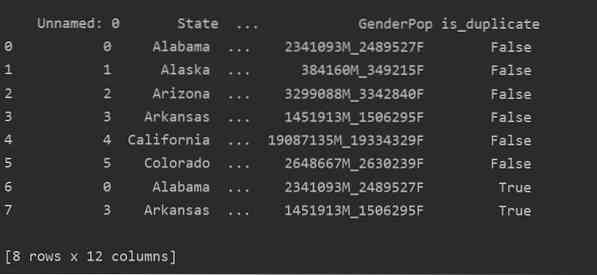
Suppression des doublons dans Pandas Python
Les lignes dupliquées peuvent être supprimées de votre bloc de données à l'aide de la syntaxe suivante :
drop_duplicates(subset=", keep=", inplace=False)
Les trois paramètres ci-dessus sont facultatifs et sont expliqués plus en détail ci-dessous :
garder: ce paramètre a trois valeurs différentes : First, Last et False. La valeur First conserve la première occurrence et supprime les doublons suivants, la valeur Last ne conserve que la dernière occurrence et supprime tous les doublons précédents, et la valeur False supprime toutes les lignes dupliquées.
sous-ensemble : étiquette utilisée pour identifier les lignes dupliquées
en place: contient deux conditions : Vrai et Faux. Ce paramètre supprimera les lignes dupliquées s'il est défini sur True.
Supprimer les doublons en ne conservant que la première occurrence
Lorsque vous utilisez "keep=first", seule la première occurrence de ligne sera conservée et tous les autres doublons seront supprimés.
Exemple
Dans cet exemple, seule la première ligne sera conservée et les doublons restants seront supprimés :
importer des pandas au format pddf_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.dupliqué()]
print("\n\nLignes en double : \n ".format(Dup_Rows))
DF_RM_DUP = df_état.drop_duplicates(keep='first')
print('\n\nResult DataFrame après suppression des doublons :\n', DF_RM_DUP.tête (n=5))
Dans la capture d'écran suivante, l'occurrence de première ligne conservée est surlignée en rouge et les duplications restantes sont supprimées :
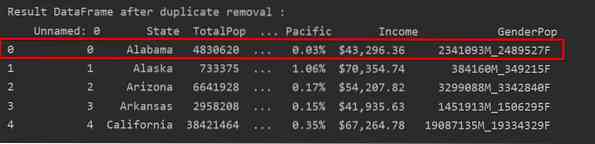
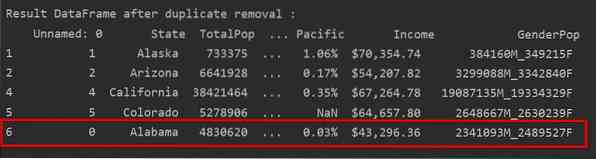
Supprimer les doublons en ne conservant que la dernière occurrence
Lorsque vous utilisez « keep=last », toutes les lignes en double, à l'exception de la dernière occurrence, seront supprimées.
Exemple
Dans l'exemple suivant, toutes les lignes dupliquées sont supprimées, à l'exception de la dernière occurrence.
importer des pandas au format pddf_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.dupliqué()]
print("\n\nLignes en double : \n ".format(Dup_Rows))
DF_RM_DUP = df_état.drop_duplicates(keep='last')
print('\n\nResult DataFrame après suppression des doublons :\n', DF_RM_DUP.tête (n=5))
Dans l'image suivante, les doublons sont supprimés et seule la dernière occurrence de ligne est conservée :
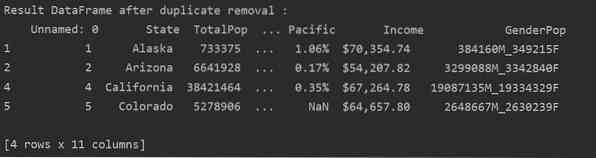
Supprimer toutes les lignes en double
Pour supprimer toutes les lignes en double d'une table, définissez « keep=False », comme suit :
importer des pandas au format pddf_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.dupliqué()]
print("\n\nLignes en double : \n ".format(Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates(keep=False)
print('\n\nResult DataFrame après suppression des doublons :\n', DF_RM_DUP.tête (n=5))
Comme vous pouvez le voir dans l'image suivante, tous les doublons sont supprimés du bloc de données :
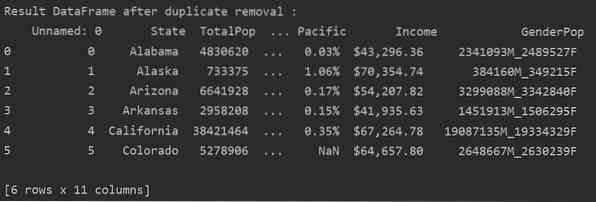
Supprimer les doublons associés d'une colonne spécifiée
Par défaut, la fonction vérifie toutes les lignes dupliquées de toutes les colonnes dans le bloc de données donné. Mais, vous pouvez également spécifier le nom de la colonne en utilisant le paramètre de sous-ensemble.
Exemple
Dans l'exemple suivant, tous les doublons associés sont supprimés de la colonne « États ».
importer des pandas au format pddf_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.dupliqué()]
print("\n\nLignes en double : \n ".format(Dup_Rows))
DF_RM_DUP = df_état.drop_duplicates(sous-ensemble='État')
print('\n\nResult DataFrame après suppression des doublons :\n', DF_RM_DUP.tête (n=6))
Conclusion
Cet article vous a montré comment supprimer les lignes dupliquées d'un bloc de données à l'aide du drop_duplicates() fonction dans Pandas Python. Vous pouvez également effacer vos données de duplication ou de redondance en utilisant cette fonction. L'article vous a également montré comment identifier les doublons dans votre bloc de données.


