Dans cet article, nous allons explorer diverses méthodes de traçage de données en utilisant le python Pandas. Nous avons exécuté tous les exemples sur l'éditeur de code source pycharm en utilisant le matplotlib.paquet pyplot.
Tracer dans Pandas Python
Chez les pandas, le .plot() a plusieurs paramètres que vous pouvez utiliser en fonction de vos besoins. La plupart du temps, en utilisant le paramètre 'kind', vous pouvez définir le type de tracé que vous allez créer.
La syntaxe pour tracer des données à l'aide de Pandas Python
La syntaxe suivante est utilisée pour tracer un DataFrame dans Pandas Python :
# importer des pandas et matplotlib.Forfaits pyplotimporter des pandas au format pd
importer matplotlib.pyplot en tant que plt
# Préparer les données pour créer DataFrame
data_frame =
'Column1' : ['field1', 'field2', 'field3', 'field4',… ],
'Column2' : ['field1', 'field2', 'field3', 'field4',… ]
var_df= pd.DataFrame(data_frame, colonnes=['Column1', 'Column2])
imprimer (variable)
# tracer un graphique à barres
var_df.parcelle.barre(x='Colonne1', y='Colonne2')
plt.spectacle()
Vous pouvez également définir le type de tracé en utilisant le paramètre kind comme suit :
var_df.plot(x='Column1', y='Column2', kind='bar')Les objets Pandas DataFrames ont les méthodes de tracé suivantes pour le traçage :
- Nuage de points : parcelle.dispersion()
- Tracé à barres : parcelle.barre() , tracer.barh() où h représente le tracé des barres horizontales.
- Tracé de ligne : parcelle.ligne()
- Tarte à tarte : parcelle.tarte()
Si un utilisateur n'utilise que la méthode plot() sans utiliser de paramètre, il crée le graphique linéaire par défaut.
Nous allons maintenant détailler quelques grands types de tracés à l'aide de quelques exemples.
Nuage de points dans les pandas
Dans ce type de tracé, nous avons représenté la relation entre deux variables. Prenons un exemple.
Exemple
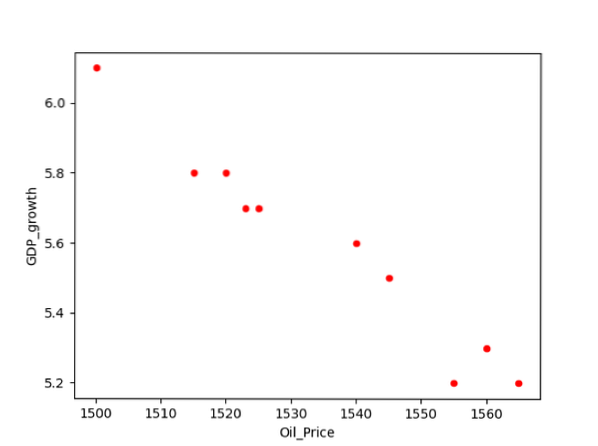
Par exemple, nous avons des données de corrélation entre deux variables GDP_growth et Oil_price. Pour tracer la relation entre deux variables, nous avons exécuté le morceau de code suivant sur notre éditeur de code source :
importer matplotlib.pyplot en tant que pltimporter des pandas au format pd
gdp_cal= pd.Trame de données(
'GDP_growth' : [6.1, 5.8, 5.7, 5.7, 5.8, 5.6, 5.5, 5.3, 5.2, 5.2],
« Prix_du_pétrole » : [1500, 1520, 1525, 1523, 1515, 1540, 1545, 1560, 1555, 1565]
)
df = pd.DataFrame(gdp_cal, colonnes=['Oil_Price', 'GDP_growth'])
imprimer (df)
df.plot(x='Oil_Price', y='GDP_growth', kind = 'scatter', color= 'red')
plt.spectacle()
Tracer des graphiques en courbes dans Pandas
Le graphique en courbes est un type de tracé de base dans lequel des informations données s'affichent dans une série de points de données qui sont en outre reliés par des segments de lignes droites. À l'aide des graphiques en courbes, vous pouvez également afficher les tendances des informations au fil du temps.
Exemple
Dans l'exemple ci-dessous, nous avons pris les données sur le taux d'inflation de l'année dernière. Tout d'abord, préparez les données, puis créez DataFrame. Le code source suivant trace le graphique linéaire des données disponibles :
importer des pandas au format pdimporter matplotlib.pyplot en tant que plt
infl_cal = 'Année' : [2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011],
'Infl_Taux' : [5.8, 10, 7, 6.7, 6.8, 6, 5.5, 8.2, 8.5, 9, 10]
data_frame = pd.DataFrame(infl_cal, colonnes=['Année', 'Infl_Rate'])
trame de données.plot(x='Year', y='Infl_Rate', kind='line')
plt.spectacle()
Dans l'exemple ci-dessus, vous devez définir le kind= 'line' pour le traçage du graphique en courbes.
Méthode 2 # Utilisation du tracé.méthode line()
L'exemple ci-dessus, vous pouvez également implémenter en utilisant la méthode suivante :
importer des pandas au format pdimporter matplotlib.pyplot en tant que plt
inf_cal = 'Année' : [2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011],
« Taux_d'inflation » : [5.8, 10, 7, 6.7, 6.8, 6, 5.5, 8.2, 8.5, 9, 10]
data_frame = pd.DataFrame(inf_cal, colonnes=['Inflation_Rate'], index=[2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011])
trame de données.parcelle.ligne()
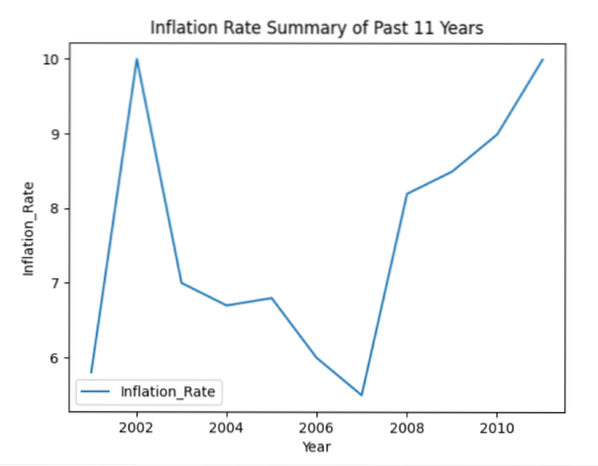
plt.title('Résumé du taux d'inflation des 11 dernières années')
plt.ylabel('Inflation_Taux')
plt.xlabel('Année')
plt.spectacle()
Le graphique linéaire suivant s'affichera après l'exécution du code ci-dessus :
Tracé de graphique à barres dans Pandas
Le tracé du graphique à barres est utilisé pour représenter les données catégorielles. Dans ce type de tracé, les barres rectangulaires de différentes hauteurs sont tracées en fonction des informations fournies. Le graphique à barres peut être tracé dans deux directions horizontales ou verticales différentes.
Exemple
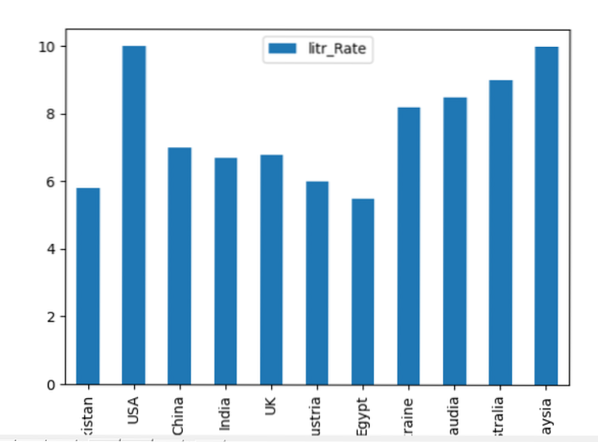
Nous avons pris le taux d'alphabétisation de plusieurs pays dans l'exemple suivant. Les DataFrames sont créés dans lesquels 'Country_Names' et 'literacy_Rate' sont les deux colonnes d'un DataFrame. À l'aide de Pandas, vous pouvez tracer les informations sous la forme d'un graphique à barres comme suit :
importer des pandas au format pdimporter matplotlib.pyplot en tant que plt
lit_cal =
'Country_Names' : ['Pakistan', 'USA', 'Chine', 'Inde', 'Royaume-Uni', 'Autriche', 'Egypte', 'Ukraine', 'Arabie', 'Australie',
'Malaisie'],
'litr_Rate' : [5.8, 10, 7, 6.7, 6.8, 6, 5.5, 8.2, 8.5, 9, 10]
data_frame = pd.DataFrame(lit_cal, colonnes=['Country_Names', 'litr_Rate'])
print(data_frame)
trame de données.parcelle.bar(x='Country_Names', y='litr_Rate')
plt.spectacle()
Vous pouvez également implémenter l'exemple ci-dessus en utilisant la méthode suivante. Définissez le kind="bar" pour le tracé du graphique à barres sur cette ligne :
trame de données.plot(x='Country_Names', y='litr_Rate', kind='bar')plt.spectacle()
Tracé de graphique à barres horizontales
Vous pouvez également tracer les données sur des barres horizontales en exécutant le code suivant :
importer matplotlib.pyplot en tant que pltimporter des pandas au format pd
data_chart = 'litr_Rate' : [5.8, 10, 7, 6.7, 6.8, 6, 5.5, 8.2, 8.5, 9, 10]
df = pd.DataFrame(data_chart, colonnes=['litr_Rate'], index=['Pakistan', 'USA', 'Chine', 'Inde', 'Royaume-Uni', 'Autriche', 'Egypte', 'Ukraine', 'Arabie' , 'Australie',
'Malaisie'])
df.parcelle.barh()
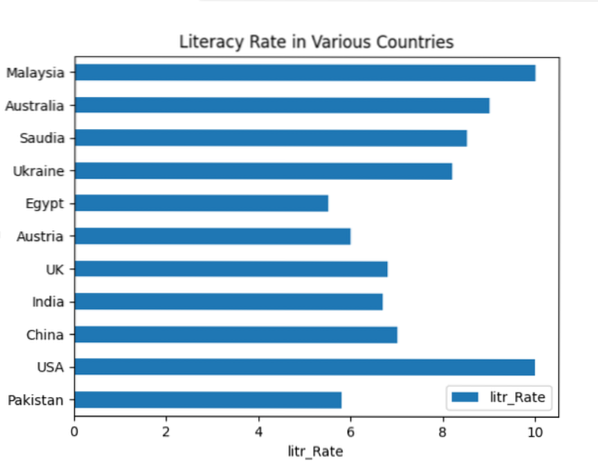
plt.title('Taux d'alphabétisation dans divers pays')
plt.ylabel('Country_Names')
plt.xlabel('litr_Taux')
plt.spectacle()
En df.parcelle.barh(), le barh est utilisé pour le traçage horizontal. Après avoir exécuté le code ci-dessus, le graphique à barres suivant s'affiche dans la fenêtre :
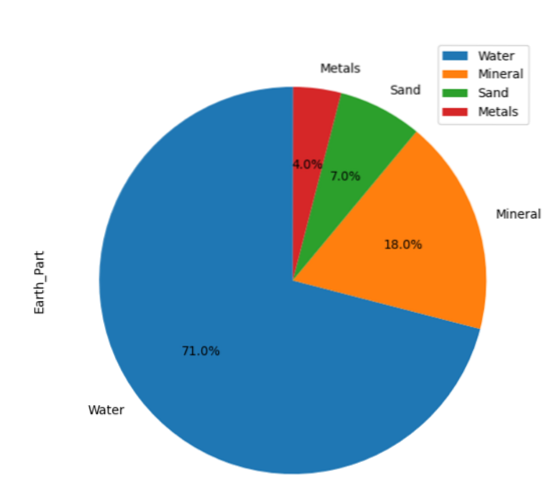
Tracer un graphique à secteurs dans les pandas
Un graphique à secteurs représente les données dans une forme graphique circulaire dans laquelle les données s'affichent en tranches en fonction de la quantité donnée.
Exemple
Dans l'exemple suivant, nous avons affiché les informations sur 'Earth_material' dans différentes tranches du graphique à secteurs. Tout d'abord, créez le DataFrame, puis, en utilisant les pandas, affichez tous les détails sur le graphique.
importer des pandas au format pdimporter matplotlib.pyplot en tant que plt
material_per = 'Earth_Part': [71,18,7,4]
cadre de données = pd.DataFrame(material_per,columns=['Earth_Part'],index = ['Water','Mineral','Sand','Metals'])
trame de données.parcelle.pie(y='Earth_Part',figsize=(7, 7),autopct='%1.1f%%', angle de départ=90)
plt.spectacle()
Le code source ci-dessus trace le graphique à secteurs des données disponibles :
Conclusion
Dans cet article, vous avez vu comment tracer des DataFrames dans Pandas python. Différents types de traçage sont effectués dans l'article ci-dessus. Pour tracer plus de types tels que box, hexbin, hist, kde, densité, zone, etc., vous pouvez utiliser le même code source simplement en changeant le type de tracé.


