Prérequis
Vous devez installer la bibliothèque python nécessaire pour lire les données de Kafka. Python3 est utilisé dans ce tutoriel pour écrire le script du consommateur et du producteur. Si le package pip n'est pas installé auparavant dans votre système d'exploitation Linux, vous devez installer pip avant d'installer la bibliothèque Kafka pour python. python3-kafka est utilisé dans ce tutoriel pour lire les données de Kafka. Exécutez la commande suivante pour installer la bibliothèque.
$ pip installer python3-kafkaLecture de données de texte simples à partir de Kafka
Différents types de données peuvent être envoyés par le producteur sur un sujet particulier qui peut être lu par le consommateur. Comment des données textuelles simples peuvent être envoyées et reçues de Kafka en utilisant le producteur et le consommateur est montré dans cette partie de ce didacticiel.
Créer un fichier nommé producteur1.py avec le script python suivant. KafkaProducteur le module est importé de la bibliothèque Kafka. La liste des courtiers doit être définie au moment de l'initialisation de l'objet producteur pour se connecter au serveur Kafka. Le port par défaut de Kafka est '9092'. L'argument bootstrap_servers est utilisé pour définir le nom d'hôte avec le port. 'Premier_sujet' est défini comme un nom de sujet par lequel le message texte sera envoyé par le producteur. Ensuite, un simple SMS, 'Bonjour de Kafka' est envoyé en utilisant envoyer() méthode de KafkaProducteur au sujet, 'Premier_sujet'.
producteur1.py :
# Importer KafkaProducer depuis la bibliothèque Kafkade kafka import KafkaProducteur
# Définir le serveur avec le port
bootstrap_servers = ['localhost:9092']
# Définir le nom du sujet où le message sera publié
topicName = 'First_Topic'
# Initialiser la variable producteur
producteur = KafkaProducer(bootstrap_servers = bootstrap_servers)
# Publier le texte dans le sujet défini
producteur.send(topicName, b'Hello de kafka… ')
# Imprimer le message
print("Message envoyé")
Créer un fichier nommé consommateur1.py avec le script python suivant. KafkaConsommateur le module est importé de la bibliothèque Kafka pour lire les données de Kafka. système module est utilisé ici pour terminer le script. Le même nom d'hôte et le même numéro de port du producteur sont utilisés dans le script du consommateur pour lire les données de Kafka. Le nom du sujet du consommateur et du producteur doit être le même que 'Premier_sujet'. Ensuite, l'objet consommateur est initialisé avec les trois arguments. Nom du sujet, identifiant de groupe et informations sur le serveur. pour la boucle est utilisée ici pour lire le texte envoyé par le producteur Kafka.
consommateur1.py :
# Importer KafkaConsumer depuis la bibliothèque Kafkade kafka import KafkaConsumer
# Importer le module sys
importer le système
# Définir le serveur avec le port
bootstrap_servers = ['localhost:9092']
# Définir le nom du sujet d'où le message sera reçu
topicName = 'First_Topic'
# Initialiser la variable consommateur
consumer = KafkaConsumer (topicName, group_id ='group1',bootstrap_servers =
serveurs_d'amorçage)
# Lire et imprimer le message du consommateur
pour msg en consommateur :
print("Nom du sujet=%s,Message=%s"%(msg.sujet, message.valeur))
# Terminer le script
système.sortir()
Production:
Exécutez la commande suivante à partir d'un terminal pour exécuter le script producteur.
$ python3 producteur1.pyLa sortie suivante apparaîtra après l'envoi du message.

Exécutez la commande suivante à partir d'un autre terminal pour exécuter le script consommateur.
$ python3 consommateur1.pyLa sortie affiche le nom du sujet et le message texte envoyé par le producteur.

Lecture de données au format JSON depuis Kafka
Les données au format JSON peuvent être envoyées par le producteur Kafka et lues par le consommateur Kafka en utilisant le json module de python. Comment les données JSON peuvent être sérialisées et désérialisées avant d'envoyer et de recevoir les données à l'aide du module python-kafka est montré dans cette partie de ce tutoriel.
Créez un script python nommé producteur2.py avec le script suivant. Un autre module nommé JSON est importé avec KafkaProducteur module ici. value_serializer l'argument est utilisé avec serveurs_d'amorçage argument ici pour initialiser l'objet du producteur Kafka. Cet argument indique que les données JSON seront encodées à l'aide de 'utf-8' jeu de caractères au moment de l'envoi. Ensuite, les données au format JSON sont envoyées au sujet nommé JSONsujet.
producteur2.py :
# Importer KafkaProducer depuis la bibliothèque Kafkade kafka import KafkaProducteur
# Importer le module JSON pour sérialiser les données
importer json
# Initialiser la variable producteur et définir le paramètre pour l'encodage JSON
producteur = KafkaProducer(bootstrap_servers =
['localhost:9092'],value_serializer=lambda v: json.décharges(v).encoder('utf-8'))
# Envoyer des données au format JSON
producteur.send('JSONtopic', 'name': 'fahmida','email':'[email protected]')
# Imprimer le message
print("Message envoyé à JSONtopic")
Créez un script python nommé consommateur2.py avec le script suivant. KafkaConsommateur, système et les modules JSON sont importés dans ce script. KafkaConsommateur module est utilisé pour lire les données au format JSON à partir du Kafka. Le module JSON est utilisé pour décoder les données JSON encodées envoyées par le producteur Kafka. Sys module est utilisé pour terminer le script. value_deserializer l'argument est utilisé avec serveurs_d'amorçage pour définir comment les données JSON seront décodées. Suivant, pour la boucle est utilisée pour imprimer tous les enregistrements des consommateurs et les données JSON récupérées de Kafka.
consommateur2.py :
# Importer KafkaConsumer depuis la bibliothèque Kafkade kafka import KafkaConsumer
# Importer le module sys
importer le système
# Importer le module json pour sérialiser les données
importer json
# Initialiser la variable consommateur et définir la propriété pour le décodage JSON
consommateur = KafkaConsumer ('JSONtopic',bootstrap_servers = ['localhost:9092'],
value_deserializer=lambda m: json.charges (m.décoder('utf-8')))
# Lire les données de kafka
pour le message dans le consommateur :
print("Enregistrements des consommateurs :\n")
imprimer (message)
print("\nLecture à partir de données JSON\n")
print("Nom :",message[6]['nom'])
print("Email :",message[6]['email'])
# Terminer le script
système.sortir()
Production:
Exécutez la commande suivante à partir d'un terminal pour exécuter le script producteur.
$ python3 producteur2.pyLe script imprimera le message suivant après l'envoi des données JSON.

Exécutez la commande suivante à partir d'un autre terminal pour exécuter le script consommateur.
$ python3 consommateur2.pyLa sortie suivante apparaîtra après l'exécution du script.
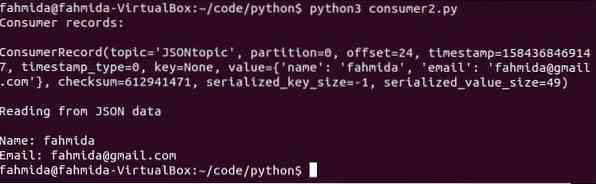
Conclusion:
Les données peuvent être envoyées et reçues dans différents formats depuis Kafka en utilisant python. Les données peuvent également être stockées dans la base de données et extraites de la base de données à l'aide de Kafka et de python. Je suis chez moi, ce tutoriel aidera l'utilisateur de python à commencer à travailler avec Kafka.


