Apache Hadoop est une solution Big Data pour le stockage et l'analyse de grandes quantités de données. Dans cet article, nous détaillerons les étapes de configuration complexes d'Apache Hadoop pour vous permettre de démarrer avec Ubuntu le plus rapidement possible. Dans cet article, nous allons installer Apache Hadoop sur un Ubuntu 17.10 machines.
Version Ubuntu
Pour ce guide, nous utiliserons Ubuntu version 17.10 (GNU/Linux 4.13.0-38-générique x86_64).
Mise à jour des packages existants
Pour démarrer l'installation d'Hadoop, il est nécessaire que nous mettions à jour notre machine avec les derniers packages logiciels disponibles. Nous pouvons le faire avec :
sudo apt-get update && sudo apt-get -y dist-upgradeComme Hadoop est basé sur Java, nous devons l'installer sur notre machine. Nous pouvons utiliser n'importe quelle version de Java au-dessus de Java 6. Ici, nous utiliserons Java 8 :
sudo apt-get -y install openjdk-8-jdk-headlessTéléchargement de fichiers Hadoop
Tous les packages nécessaires existent désormais sur notre machine. Nous sommes prêts à télécharger les fichiers Hadoop TAR requis afin que nous puissions commencer à les configurer et exécuter également un exemple de programme avec Hadoop.
Dans ce guide, nous allons installer Hadoop v3.0.1. Téléchargez les fichiers correspondants avec cette commande :
wget http://miroir.cc.la colombie.edu/pub/software/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.le goudron.gzSelon la vitesse du réseau, cela peut prendre jusqu'à quelques minutes car le fichier est volumineux :
Téléchargement d'Hadoop
Trouvez les derniers binaires Hadoop ici. Maintenant que nous avons téléchargé le fichier TAR, nous pouvons l'extraire dans le répertoire courant :
goudron xvzf hadoop-3.0.1.le goudron.gzCela prendra quelques secondes en raison de la grande taille du fichier de l'archive :
Hadoop désarchivé
Ajout d'un nouveau groupe d'utilisateurs Hadoop
Comme Hadoop fonctionne sur HDFS, un nouveau système de fichiers peut également perturber notre propre système de fichiers sur la machine Ubuntu. Pour éviter cette collision, nous allons créer un groupe d'utilisateurs complètement séparé et l'attribuer à Hadoop afin qu'il contienne ses propres autorisations. Nous pouvons ajouter un nouveau groupe d'utilisateurs avec cette commande :
addgroup hadoopNous verrons quelque chose comme :
Ajout d'un groupe d'utilisateurs Hadoop
Nous sommes prêts à ajouter un nouvel utilisateur à ce groupe :
useradd -G hadoop hadoopuserVeuillez noter que toutes les commandes que nous exécutons sont en tant qu'utilisateur root lui-même. Avec la commande aove, nous avons pu ajouter un nouvel utilisateur au groupe que nous avons créé.
Pour permettre à l'utilisateur Hadoop d'effectuer des opérations, nous devons également lui fournir un accès root. Ouvrez le /etc/sudoers fichier avec cette commande :
sudo visudoAvant d'ajouter quoi que ce soit, le fichier ressemblera à :
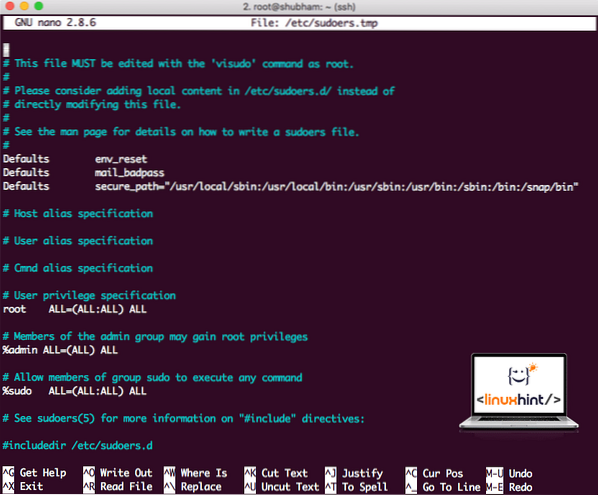
fichier Sudoers avant d'ajouter quoi que ce soit
Ajoutez la ligne suivante à la fin du fichier :
hadoopuser TOUS=(TOUS) TOUSMaintenant, le fichier ressemblera à :
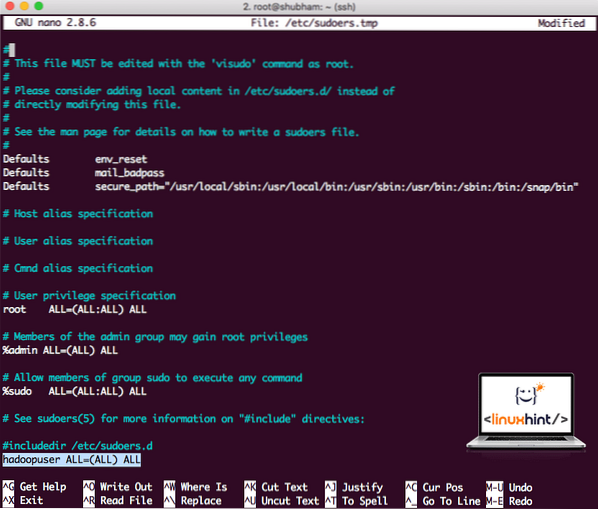
Fichier Sudoers après l'ajout de l'utilisateur Hadoop
C'était la configuration principale pour fournir à Hadoop une plate-forme pour effectuer des actions. Nous sommes prêts à configurer un cluster Hadoop à nœud unique maintenant.
Configuration d'un seul nœud Hadoop : mode autonome
En ce qui concerne la puissance réelle d'Hadoop, il est généralement configuré sur plusieurs serveurs afin qu'il puisse s'adapter à une grande quantité d'ensembles de données présents dans Système de fichiers distribué Hadoop (HDFS). Cela convient généralement aux environnements de débogage et n'est pas utilisé pour une utilisation en production. Pour garder le processus simple, nous expliquerons comment nous pouvons faire une configuration de nœud unique pour Hadoop ici.
Une fois que nous aurons terminé d'installer Hadoop, nous exécuterons également un exemple d'application sur Hadoop. A partir de maintenant, le fichier Hadoop est nommé hadoop-3.0.1. Renommez-le en hadoop pour une utilisation plus simple :
mv hadoop-3.0.1 hadoopLe fichier ressemble maintenant à :
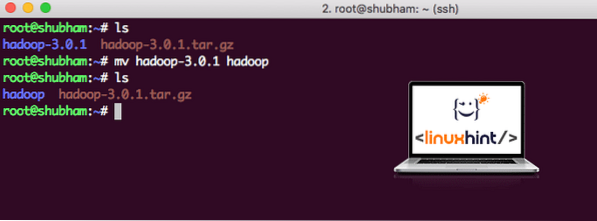
Déplacer Hadoop
Il est temps d'utiliser l'utilisateur hadoop que nous avons créé plus tôt et d'attribuer la propriété de ce fichier à cet utilisateur :
chown -R hadoopuser:hadoop /root/hadoopUn meilleur emplacement pour Hadoop sera le répertoire /usr/local/, alors déplaçons-le là :
mv hadoop /usr/local/cd /usr/local/
Ajouter Hadoop à Path
Pour exécuter des scripts Hadoop, nous allons l'ajouter au chemin maintenant. Pour ce faire, ouvrez le fichier bashrc :
vi ~/.bashrcAjoutez ces lignes à la fin du .bashrc afin que ce chemin puisse contenir le chemin du fichier exécutable Hadoop :
# Configurer Hadoop et Java Homeexport HADOOP_HOME=/usr/local/hadoop
exporter JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export CHEMIN=$CHEMIN:$HADOOP_HOME/bin
Le fichier ressemble à :
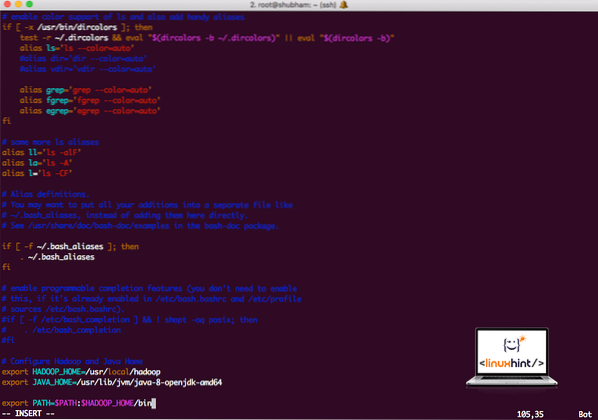
Ajouter Hadoop à Path
Comme Hadoop utilise Java, nous devons indiquer au fichier d'environnement Hadoop hadoop-env.sh où il se trouve. L'emplacement de ce fichier peut varier en fonction des versions Hadoop. Pour trouver facilement où se trouve ce fichier, exécutez la commande suivante juste en dehors du répertoire Hadoop :
trouver hadoop/ -name hadoop-env.shNous obtiendrons la sortie pour l'emplacement du fichier :
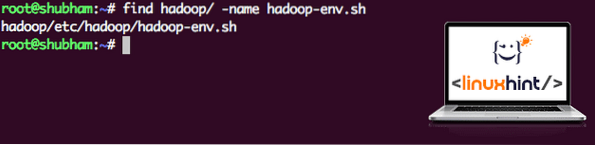
Emplacement du fichier d'environnement
Modifions ce fichier pour informer Hadoop de l'emplacement du JDK Java et insérons-le sur la dernière ligne du fichier et enregistrez-le :
exporter JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64L'installation et la configuration d'Hadoop sont maintenant terminées. Nous sommes prêts à exécuter notre exemple d'application maintenant. Mais attendez, nous n'avons jamais fait d'exemple d'application!
Exécuter un exemple d'application avec Hadoop
En fait, l'installation d'Hadoop est livrée avec un exemple d'application intégré qui est prêt à être exécuté une fois l'installation d'Hadoop terminée. Ça sonne bien, n'est-ce pas?
Exécutez la commande suivante pour exécuter l'exemple JAR :
Hadoop jar /root/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.1.jar wordcount /root/hadoop/README.txt /root/SortieHadoop montrera combien de traitement il a effectué au niveau du nœud :
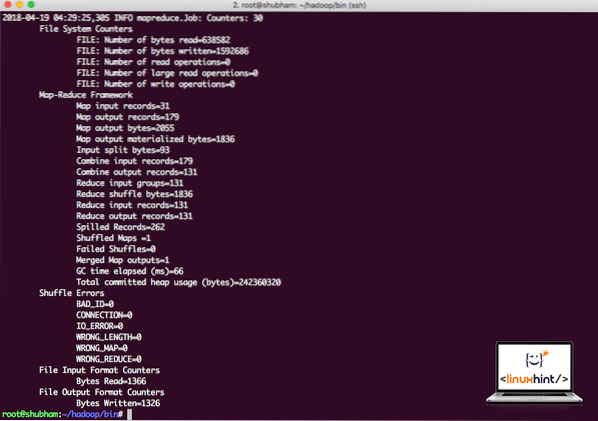
Statistiques de traitement Hadoop
Une fois que vous exécutez la commande suivante, nous voyons le fichier part-r-00000 en sortie. Allez-y et regardez le contenu de la sortie :
chat partie-r-00000Vous obtiendrez quelque chose comme :
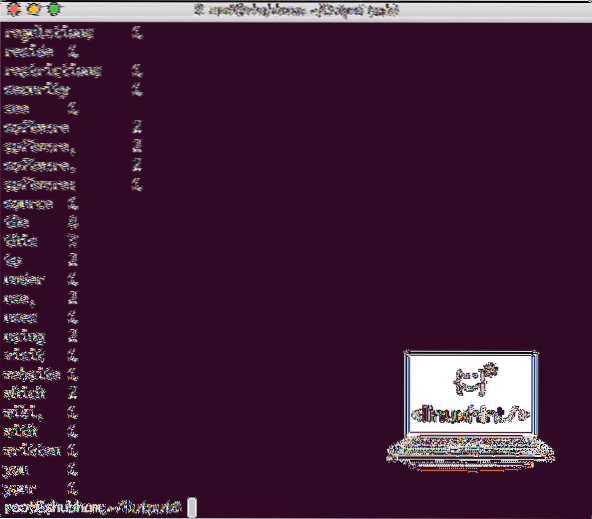
Nombre de mots généré par Hadoop
Conclusion
Dans cette leçon, nous avons vu comment installer et commencer à utiliser Apache Hadoop sur Ubuntu 17.10 machines. Hadoop est idéal pour stocker et analyser une grande quantité de données et j'espère que cet article vous aidera à commencer à l'utiliser rapidement sur Ubuntu.


