Pourquoi Lucene est-il nécessaire?
La recherche est l'une des opérations les plus courantes que nous effectuons plusieurs fois par jour. Cette recherche peut porter sur plusieurs pages Web qui existent sur le Web ou une application musicale ou un référentiel de code ou une combinaison de tous ces éléments. On pourrait penser qu'une simple base de données relationnelle peut aussi prendre en charge la recherche. C'est correct. Les bases de données comme MySQL prennent en charge la recherche en texte intégral. Mais qu'en est-il du Web ou d'une application musicale ou d'un référentiel de code ou d'une combinaison de tout cela? La base de données ne peut pas stocker ces données dans ses colonnes. Même si c'était le cas, il faudra un temps inacceptable pour lancer une recherche aussi importante.
Un moteur de recherche en texte intégral est capable d'exécuter une requête de recherche sur des millions de fichiers à la fois. La vitesse à laquelle les données sont stockées dans une application aujourd'hui est énorme. Exécuter la recherche en texte intégral sur ce type de volume de données est une tâche difficile. En effet, les informations dont nous avons besoin peuvent exister dans un seul fichier parmi des milliards de fichiers conservés sur le Web.
Comment fonctionne Lucène?
La question évidente qui devrait vous venir à l'esprit est de savoir comment Lucene est-il si rapide à exécuter des requêtes de recherche en texte intégral? La réponse à cela, bien sûr, est à l'aide d'indices qu'il crée. Mais au lieu de créer un index classique, Lucene utilise Indices inversés.
Dans un index classique, pour chaque document, nous collectons la liste complète des mots ou termes contenus dans le document. Dans un index inversé, pour chaque mot dans tous les documents, nous stockons quel document et positionnons ce mot/terme à. Il s'agit d'un algorithme de haut niveau qui rend la recherche très facile. Prenons l'exemple suivant de création d'un index classique :
Doc1 -> "Ceci", "est", "simple", "Lucene", "échantillon", "classique", "inversé", "index"Doc2 -> "En cours d'exécution", "Elasticsearch", "Ubuntu", "Mise à jour"
Doc3 -> "RabbitMQ", "Lucene", "Kafka", "", "Printemps", "Boot"
Si nous utilisons l'index inversé, nous aurons des index comme :
Ceci -> (2, 71)Lucène -> (1, 9), (12,87)
Apache -> (12, 91)
Cadre -> (32, 11)
Les indices inversés sont beaucoup plus faciles à maintenir. Supposons que si nous voulons trouver Apache dans mes termes, j'aurai des réponses immédiates avec des indices inversés alors qu'avec la recherche classique, je fonctionnerai sur des documents complets qui n'auraient peut-être pas été possibles dans des scénarios en temps réel.
Flux de travail Lucene
Avant que Lucene puisse réellement rechercher les données, il doit effectuer des étapes. Visualisons ces étapes pour une meilleure compréhension :
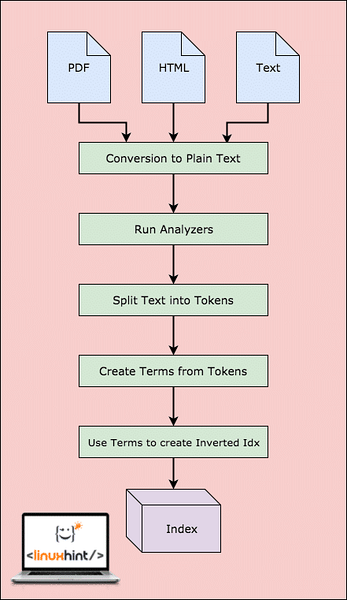
Flux de travail Lucene
Comme le montre le schéma, voici ce qui se passe dans Lucene :
- Lucene se nourrit des documents et autres sources de données
- Pour chaque document, Lucene convertit d'abord ces données en texte brut, puis les analyseurs convertissent cette source en texte brut
- Pour chaque terme du texte brut, les indices inversés sont créés
- Les index sont prêts à être recherchés
Avec ce workflow, Lucene est un moteur de recherche plein texte très puissant. Mais c'est la seule partie que Lucene remplit. Nous devons effectuer le travail nous-mêmes. Regardons les composants de l'indexation nécessaires.
Composants de Lucène
Dans cette section, nous décrirons les composants de base et les classes Lucene de base utilisées pour créer des index :
- Annuaires: Un index Lucene stocke les données dans les répertoires normaux du système de fichiers ou en mémoire si vous avez besoin de plus de performances. C'est complètement le choix des applications pour stocker des données où il veut, une base de données, la RAM ou le disque.
- Documents: Les données que nous transmettons au moteur Lucene doivent être converties en texte brut. Pour ce faire, nous créons un objet Document qui représente cette source de données. Plus tard, lorsque nous exécutons une requête de recherche, nous obtiendrons une liste d'objets Document qui satisfont à la requête que nous avons passée.
- Des champs: les documents sont remplis avec une collection de champs. Un champ est simplement une paire de (nom, valeur) éléments. Ainsi, lors de la création d'un nouvel objet Document, nous devons le remplir avec ce type de données appariées. Lorsqu'un champ est indexé de manière inverse, la valeur du champ est tokenisée et est disponible pour la recherche. Maintenant, pendant que nous utilisons des champs, il n'est pas important de stocker la paire réelle mais uniquement l'indexé inversé. De cette façon, nous pouvons décider quelles données sont consultables uniquement et qu'il n'est pas important de les sauvegarder. Regardons un exemple ici :

Indexation des champs
Dans le tableau ci-dessus, nous avons décidé de stocker certains champs et d'autres ne sont pas stockés. Le champ body n'est pas stocké mais indexé. Cela signifie que l'e-mail sera renvoyé en conséquence lorsque la requête pour l'une des conditions pour le contenu du corps est exécutée.
- termes: Les termes représentent un mot du texte. Les termes sont extraits de l'analyse et de la tokenisation des valeurs des champs, ainsi Le terme est la plus petite unité sur laquelle la recherche est exécutée.
- Analyseurs: Un analyseur est la partie la plus cruciale du processus d'indexation et de recherche. C'est l'analyseur qui convertit le texte brut en jetons et termes afin qu'ils puissent être recherchés. Eh bien, ce n'est pas la seule responsabilité d'un analyseur. Un analyseur utilise un Tokenizer pour créer des Tokens. Un analyseur effectue également les tâches suivantes :
- Stemming : un analyseur convertit le mot en Stem. Cela signifie que « fleurs » est converti en le mot racine « fleur ». Ainsi, lorsqu'une recherche de 'fleur' est exécutée, le document sera renvoyé.
- Filtrage : un analyseur filtre également les mots vides comme « Le », « est », etc. car ces mots n'attirent aucune requête à exécuter et ne sont pas productifs.
- Normalisation : ce processus supprime les accents et autres marques de caractères.
C'est juste la responsabilité normale de StandardAnalyzer.
Exemple d'application
Nous utiliserons l'un des nombreux archétypes Maven pour créer un exemple de projet pour notre exemple. Pour créer le projet, exécutez la commande suivante dans un répertoire que vous utiliserez comme espace de travail :
archétype mvn:generate -DgroupId=com.astuce linux.exemple -DartifactId=LH-LuceneExample -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=falseSi vous exécutez maven pour la première fois, il faudra quelques secondes pour accomplir la commande de génération car maven doit télécharger tous les plugins et artefacts requis afin de faire la tâche de génération. Voici à quoi ressemble la sortie du projet :
Configuration du projet
Une fois que vous avez créé le projet, n'hésitez pas à l'ouvrir dans votre IDE préféré. L'étape suivante consiste à ajouter les dépendances Maven appropriées au projet. Voici le pompon.xml avec les dépendances appropriées :
Enfin, pour comprendre tous les JAR qui sont ajoutés au projet lorsque nous avons ajouté cette dépendance, nous pouvons exécuter une simple commande Maven qui nous permet de voir un arbre de dépendances complet pour un projet lorsque nous y ajoutons des dépendances. Voici une commande que nous pouvons utiliser :
dépendance mvn:arborescenceLorsque nous exécutons cette commande, elle nous montrera l'arbre de dépendances suivant :
Enfin, nous créons une classe SimpleIndexer qui exécute
importer java.io.Déposer;
importer java.io.Lecteur de fichiers ;
importer java.io.IOException ;
importer l'organisation.apache.lucène.Analyse.Analyseur ;
importer l'organisation.apache.lucène.Analyse.la norme.Analyseur standard ;
importer l'organisation.apache.lucène.document.Document;
importer l'organisation.apache.lucène.document.Champ Stocké ;
importer l'organisation.apache.lucène.document.Champ de texte;
importer l'organisation.apache.lucène.indice.IndexWriter;
importer l'organisation.apache.lucène.indice.IndexWriterConfig;
importer l'organisation.apache.lucène.boutique.FSDirectory ;
importer l'organisation.apache.lucène.util.Version;
classe publique SimpleIndexer
private static final String indexDirectory = "/Users/shubham/somewhere/LH-LuceneExample/Index" ;
Private static final String dirToBeIndexed = "/Users/shubham/somewhere/LH-LuceneExample/src/main/java/com/linuxhint/example" ;
public static void main(String[] args) lève une exception
Fichier indexDir = new File(indexDirectory);
Fichier dataDir = new File(dirToBeIndexed);
Indexeur SimpleIndexer = new SimpleIndexer();
int numIndexed = indexeur.index(indexDir, dataDir);
Système.en dehors.println("Total des fichiers indexés " + numIndexed);
private int index (File indexDir, File dataDir) lève IOException
Analyseur analyseur = nouveau StandardAnalyzer(Version.LUCÈNE_46);
IndexWriterConfig config = new IndexWriterConfig(Version.LUCÈNE_46,
analyseur);
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(indexDir),
configuration);
File[] files = dataDir.listeFichiers();
pour (Fichier f : fichiers)
Système.en dehors.println("Fichier d'indexation " + f.getCanonicalPath());
Document doc = nouveau Document();
doc.add(new TextField("content", new FileReader(f)));
doc.add(new StoredField("fileName", f.getCanonicalPath()));
indexWriter.addDocument(doc);
int numIndexed = indexWriter.maxDoc();
indexWriter.Fermer();
return numIndexed;
Dans ce code, nous venons de créer une instance de document et d'ajouter un nouveau champ qui représente le contenu du fichier. Voici la sortie que nous obtenons lorsque nous exécutons ce fichier :
Fichier d'indexation /Users/shubham/somewhere/LH-LuceneExample/src/main/java/com/linuxhint/example/SimpleIndexer.JavaNombre total de fichiers indexés 1
De plus, un nouveau répertoire est créé dans le projet avec le contenu suivant :
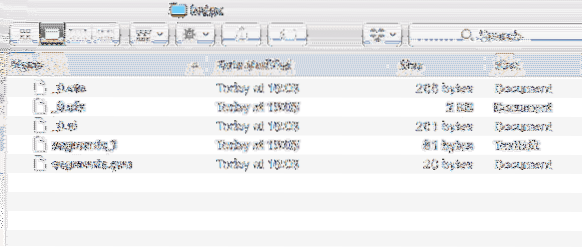
Indexer les données
Nous analyserons ce que tous les fichiers sont créés dans ces index dans d'autres leçons à venir sur Lucene.
Conclusion
Dans cette leçon, nous avons examiné le fonctionnement d'Apache Lucene et nous avons également créé un exemple d'application simple basé sur Maven et Java.


