Les didacticiels de grattage Web ont été couverts dans le passé, donc ce didacticiel ne couvre que l'aspect de l'accès aux sites Web en se connectant avec du code au lieu de le faire manuellement en utilisant le navigateur.
Pour comprendre ce tutoriel et être capable d'écrire des scripts pour se connecter à des sites Web, vous auriez besoin d'une certaine compréhension du HTML. Peut-être pas assez pour créer des sites Web impressionnants, mais assez pour comprendre la structure d'une page Web de base.
Installation
Cela se ferait avec les bibliothèques Requests et BeautifulSoup Python. Outre ces bibliothèques Python, vous auriez besoin d'un bon navigateur tel que Google Chrome ou Mozilla Firefox car ils seraient importants pour l'analyse initiale avant d'écrire du code.
Les bibliothèques Requests et BeautifulSoup peuvent être installées avec la commande pip depuis le terminal comme indiqué ci-dessous :
demandes d'installation de pippip installer BeautifulSoup4
Pour confirmer le succès de l'installation, activez le shell interactif de Python qui se fait en tapant python dans le terminal.
Importez ensuite les deux bibliothèques :
demandes d'importationde l'importation bs4 BeautifulSoup
L'importation est réussie s'il n'y a pas d'erreurs.
Le processus
Se connecter à un site Web avec des scripts nécessite une connaissance du HTML et une idée du fonctionnement du Web. Examinons brièvement le fonctionnement du Web.
Les sites Web sont constitués de deux parties principales, le côté client et le côté serveur. Le côté client est la partie d'un site Web avec laquelle l'utilisateur interagit, tandis que le côté serveur est la partie du site Web où la logique métier et d'autres opérations de serveur telles que l'accès à la base de données sont exécutées.
Lorsque vous essayez d'ouvrir un site Web via son lien, vous faites une demande au côté serveur pour récupérer les fichiers HTML et autres fichiers statiques tels que CSS et JavaScript. Cette requête est connue sous le nom de requête GET. Cependant, lorsque vous remplissez un formulaire, téléchargez un fichier multimédia ou un document, créez un article et cliquez, disons sur un bouton d'envoi, vous envoyez des informations au côté serveur. Cette requête est connue sous le nom de requête POST.
Une compréhension de ces deux concepts serait importante lors de l'écriture de notre script.
Inspection du site Web
Pour mettre en pratique les concepts de cet article, nous utiliserions le site Web Quotes To Scrape.
La connexion aux sites Web nécessite des informations telles que le nom d'utilisateur et un mot de passe.
Cependant, comme ce site Web n'est utilisé que comme une preuve de concept, tout est permis. Par conséquent, nous utiliserions administrateur comme nom d'utilisateur et 12345 comme mot de passe.
Tout d'abord, il est important de visualiser la source de la page car cela donnerait un aperçu de la structure de la page Web. Cela peut être fait en cliquant avec le bouton droit sur la page Web et en cliquant sur "Afficher la source de la page". Ensuite, vous inspectez le formulaire de connexion. Pour ce faire, faites un clic droit sur l'une des cases de connexion et cliquez sur inspecter l'élément. En inspectant l'élément, vous devriez voir contribution balises puis un parent forme tag quelque part au-dessus. Cela montre que les connexions sont essentiellement des formulaires PUBLIERvers le côté serveur du site Web.
Maintenant, notez le Nom attribut des balises d'entrée pour les champs nom d'utilisateur et mot de passe, ils seraient nécessaires lors de l'écriture du code. Pour ce site Web, le Nom attribut pour le nom d'utilisateur et le mot de passe sont Nom d'utilisateur et le mot de passe respectivement.
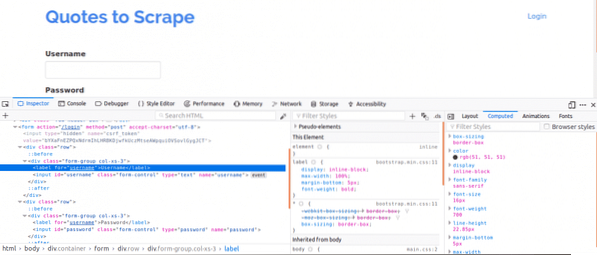
Ensuite, nous devons savoir s'il existe d'autres paramètres qui seraient importants pour la connexion. Expliquons rapidement cela. Pour augmenter la sécurité des sites Web, des jetons sont généralement générés pour empêcher les attaques de contrefaçon de sites.
Par conséquent, si ces jetons ne sont pas ajoutés à la requête POST, la connexion échouera. Alors, comment savons-nous de tels paramètres?
Nous aurions besoin d'utiliser l'onglet Réseau. Pour obtenir cet onglet sur Google Chrome ou Mozilla Firefox, ouvrez les outils de développement et cliquez sur l'onglet Réseau.
Une fois que vous êtes dans l'onglet réseau, essayez d'actualiser la page actuelle et vous remarquerez que des demandes arrivent. Vous devriez essayer de faire attention aux demandes POST envoyées lorsque nous essayons de nous connecter.
Voici ce que nous ferions ensuite, tout en ayant l'onglet Réseau ouvert. Entrez les informations de connexion et essayez de vous connecter, la première demande que vous verriez devrait être la demande POST.
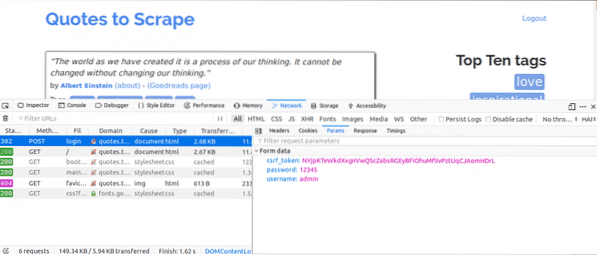
Cliquez sur la requête POST et visualisez les paramètres du formulaire. Vous remarquerez que le site Web a un csrf_token paramètre avec une valeur. Cette valeur est une valeur dynamique, nous aurions donc besoin de capturer de telles valeurs en utilisant le OBTENIR demande avant d'utiliser le PUBLIER demander.
Pour les autres sites Web sur lesquels vous travailleriez, vous ne verrez probablement pas le csrf_token mais il peut y avoir d'autres jetons qui sont générés dynamiquement. Au fil du temps, vous apprendrez à mieux connaître les paramètres qui comptent vraiment pour tenter de vous connecter.
Le code
Premièrement, nous devons utiliser Requests et BeautifulSoup pour accéder au contenu de la page de connexion.
à partir des demandes d'importation Sessionde bs4 importer BeautifulSoup en tant que bs
avec Session() comme s :
site = s.get("http://quotes.gratter.com/login")
imprimer(site.contenu)
Cela imprimerait le contenu de la page de connexion avant de nous connecter et si vous recherchez le mot-clé « Connexion ». Le mot-clé serait trouvé dans le contenu de la page indiquant que nous ne sommes pas encore connectés.
Ensuite, nous chercherions le csrf_token mot-clé qui a été trouvé comme l'un des paramètres lors de l'utilisation de l'onglet réseau plus tôt. Si le mot-clé présente une correspondance avec un contribution tag, la valeur peut être extraite à chaque fois que vous exécutez le script à l'aide de BeautifulSoup.
à partir des demandes d'importation Sessionde bs4 importer BeautifulSoup en tant que bs
avec Session() comme s :
site = s.get("http://quotes.gratter.com/login")
bs_content = bs(site.contenu, "html.parseur")
jeton = bs_content.find("input", "name":"csrf_token")["value"]
login_data = "username":"admin","password":"12345", "csrf_token":token
s.post("http://citations.gratter.com/login",login_data)
page_accueil = s.get("http://quotes.gratter.com")
imprimer(page_accueil.contenu)
Cela imprimerait le contenu de la page après la connexion, et si vous recherchez le mot-clé « Déconnexion ». Le mot-clé serait trouvé dans le contenu de la page montrant que nous avons pu nous connecter avec succès.
Jetons un coup d'œil à chaque ligne de code.
à partir des demandes d'importation Sessionde bs4 importer BeautifulSoup en tant que bs
Les lignes de code ci-dessus permettent d'importer l'objet Session de la bibliothèque des requêtes et l'objet BeautifulSoup de la bibliothèque bs4 en utilisant un alias de bs.
avec Session() comme s :La session de requêtes est utilisée lorsque vous avez l'intention de conserver le contexte d'une requête, de sorte que les cookies et toutes les informations de cette session de requête peuvent être stockés.
bs_content = bs(site.contenu, "html.parseur")jeton = bs_content.find("input", "name":"csrf_token")["value"]
Ce code utilise ici la bibliothèque BeautifulSoup afin que le csrf_token peut être extrait de la page Web, puis attribué à la variable jeton. Vous pouvez en savoir plus sur l'extraction de données à partir de nœuds à l'aide de BeautifulSoup.
login_data = "username":"admin","password":"12345", "csrf_token":tokens.post("http://citations.gratter.com/login", login_data)
Le code crée ici un dictionnaire des paramètres à utiliser pour la connexion. Les clés des dictionnaires sont les Nom attributs des balises d'entrée et les valeurs sont les valeur attributs des balises d'entrée.
le Publier méthode est utilisée pour envoyer une demande de publication avec les paramètres et nous connecter.
page_accueil = s.get("http://quotes.gratter.com")imprimer(page_accueil.contenu)
Après une connexion, ces lignes de code ci-dessus extraient simplement les informations de la page pour montrer que la connexion a réussi.
Conclusion
Le processus de connexion à des sites Web à l'aide de Python est assez simple, mais la configuration des sites Web n'est pas la même. Par conséquent, certains sites s'avéreraient plus difficiles à connecter que d'autres. Il y a plus à faire pour surmonter les défis de connexion que vous rencontrez.
La chose la plus importante dans tout cela est la connaissance du HTML, des requêtes, de BeautifulSoup et la capacité de comprendre les informations obtenues à partir de l'onglet Réseau des outils de développement de votre navigateur Web.


