Pandas .lire_csv
J'ai déjà discuté de l'histoire et des utilisations des pandas de la bibliothèque Python. pandas a été conçu pour répondre au besoin d'une bibliothèque efficace d'analyse et de manipulation de données financières pour Python. Afin de charger des données à des fins d'analyse et de manipulation, pandas propose deux méthodes, Lecteur de données et lire_csv. J'ai couvert le premier ici. Ce dernier est l'objet de ce tutoriel.
.lire_csv
Il existe un grand nombre de référentiels de données gratuits en ligne qui incluent des informations sur une variété de domaines. J'ai inclus certaines de ces ressources dans la section des références ci-dessous. Parce que j'ai démontré les API intégrées pour extraire efficacement des données financières ici, j'utiliserai une autre source de données dans ce didacticiel.
Données.gov propose une vaste sélection de données gratuites sur tout, du changement climatique à U.S. statistiques de fabrication. J'ai téléchargé deux ensembles de données à utiliser dans ce didacticiel. La première est la température maximale quotidienne moyenne pour le comté de Bay, en Floride. Ces données ont été téléchargées à partir de l'U.S. Boîte à outils sur la résilience climatique pour la période de 1950 à nos jours.
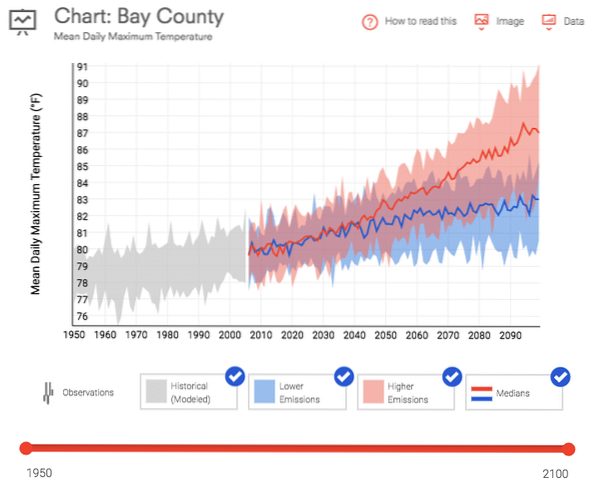
La seconde est la Commodity Flow Survey qui mesure le mode et le volume des importations dans le pays sur une période de 5 ans.

Les deux liens pour ces ensembles de données sont fournis dans la section des références ci-dessous. le .lire_csv La méthode, comme son nom l'indique, chargera ces informations à partir d'un fichier CSV et instanciera un Trame de données à partir de cet ensemble de données.
Usage
Chaque fois que vous utilisez une bibliothèque externe, vous devez dire à Python qu'elle doit être importée. Ci-dessous se trouve la ligne de code qui importe la bibliothèque pandas.
importer des pandas au format pdL'utilisation de base du .lire_csv la méthode est ci-dessous. Cela instancie et remplit un Trame de données df avec les informations dans le fichier CSV.
df = pd.read_csv('12005-annual-hist-obs-tasmax.csv')En ajoutant quelques lignes supplémentaires, nous pouvons inspecter les 5 premières et dernières lignes du DataFrame nouvellement créé.
df = pd.read_csv('12005-annual-hist-obs-tasmax.csv')imprimer (df.tête(5))
imprimer (df.queue (5))

Le code a chargé une colonne pour l'année, la température quotidienne moyenne en Celsius (tasmax), et a construit un schéma d'indexation basé sur 1 qui s'incrémente pour chaque ligne de données. Il est également important de noter que les en-têtes sont renseignés à partir du fichier. Avec l'utilisation basique de la méthode présentée ci-dessus, les en-têtes sont supposés être sur la première ligne du fichier CSV. Cela peut être modifié en passant un autre ensemble de paramètres à la méthode.
Paramètres
J'ai fourni le lien vers les pandas .lire_csv documentation dans les références ci-dessous. Plusieurs paramètres peuvent être utilisés pour modifier la façon dont les données sont lues et formatées dans le Trame de données.

Il y a un bon nombre de paramètres pour le .lire_csv méthode. La plupart ne sont pas nécessaires car la plupart des jeux de données que vous téléchargez auront un format standard. C'est des colonnes sur la première ligne et un délimiteur virgule.
Il y a quelques paramètres que je vais mettre en évidence dans le tutoriel car ils peuvent être utiles. Une enquête plus complète peut être prise à partir de la page de documentation.
index_col
index_col est un paramètre qui peut être utilisé pour indiquer la colonne qui contient l'index. Certains fichiers peuvent contenir un index et d'autres non. Dans notre premier ensemble de données, j'ai laissé python créer un index. C'est la norme .lire_csv comportement.
Dans notre deuxième ensemble de données, il y a un index inclus. Le code ci-dessous charge le Trame de données avec les données du fichier CSV, mais au lieu de créer un index incrémentiel basé sur un nombre entier, il utilise la colonne SHPMT_ID incluse dans l'ensemble de données.
df = pd.read_csv('cfs_2012_pumf_csv.txt', index_col = 'SHIPMT_ID')imprimer (df.tête(5))
imprimer (df.queue (5))
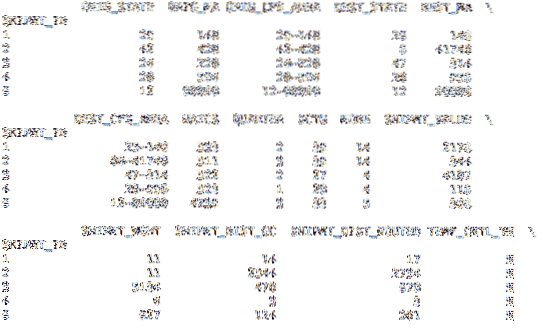
Bien que cet ensemble de données utilise le même schéma pour l'index, d'autres ensembles de données peuvent avoir un index plus utile.
nrows, skiprows, usecols
Avec de grands ensembles de données, vous souhaiterez peut-être charger uniquement des sections des données. le nrows, sauts, et usecols les paramètres vous permettront de découper les données incluses dans le fichier.
df = pd.read_csv('cfs_2012_pumf_csv.txt', index_col= 'SHIPMT_ID', nrows = 50)imprimer (df.tête(5))
imprimer (df.queue (5))
En ajoutant le nrows paramètre avec une valeur entière de 50, le .l'appel de queue renvoie maintenant des lignes jusqu'à 50. Le reste des données du fichier n'est pas importé.
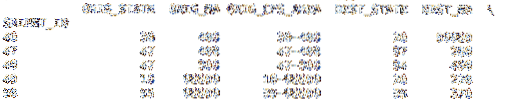
imprimer (df.tête(5))
imprimer (df.queue (5))
En ajoutant le sauts paramètre, notre .diriger col n'affiche pas un indice de début de 1001 dans les données. Parce que nous avons ignoré la ligne d'en-tête, les nouvelles données ont perdu leur en-tête et l'index basé sur les données du fichier. Dans certains cas, il peut être préférable de découper vos données dans un Trame de données plutôt qu'avant de charger les données.

le usecols est un paramètre utile qui vous permet d'importer uniquement un sous-ensemble des données par colonne. Il peut être passé un index zéro ou une liste de chaînes avec les noms de colonnes. J'ai utilisé le code ci-dessous pour importer les quatre premières colonnes dans notre nouveau Trame de données.
df = pd.read_csv('cfs_2012_pumf_csv.SMS',index_col = 'SHIPMT_ID',
nrows = 50, usecols = [0,1,2,3] )
imprimer (df.tête(5))
imprimer (df.queue (5))
De notre nouveau .diriger appel, notre Trame de données contient désormais uniquement les quatre premières colonnes de l'ensemble de données.
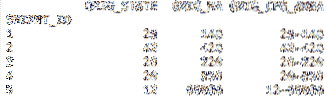
moteur
Un dernier paramètre qui, je pense, serait utile dans certains ensembles de données est le moteur paramètre. Vous pouvez utiliser le moteur basé sur C ou le code basé sur Python. Le moteur C sera naturellement plus rapide. Ceci est important si vous importez de grands ensembles de données. Les avantages de l'analyse Python sont un ensemble plus riche en fonctionnalités. Cet avantage peut signifier moins si vous chargez des données volumineuses en mémoire.
df = pd.read_csv('cfs_2012_pumf_csv.SMS',index_col = 'SHIPMT_ID', moteur = 'c' )
imprimer (df.tête(5))
imprimer (df.queue (5))
Suivre
Il existe plusieurs autres paramètres qui peuvent étendre le comportement par défaut du .lire_csv méthode. Ils peuvent être trouvés sur la page docs que j'ai référencée ci-dessous. .lire_csv est une méthode utile pour charger des ensembles de données dans les pandas pour l'analyse des données. Étant donné que de nombreux ensembles de données gratuits sur Internet n'ont pas d'API, cela s'avérera très utile pour les applications en dehors des données financières où des API robustes sont en place pour importer des données dans les pandas.
Les références
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.lire_csv.html
https://www.Les données.gouvernement/
https://boîte à outils.climat.gov/#climate-explorer
https://www.recensement.gov/econ/cfs/pums.html


