Tout au long du traitement et de l'analyse des données, les histogrammes vous aident à représenter la distribution des fréquences et à obtenir facilement des informations. Nous examinerons quelques méthodes différentes pour obtenir une distribution de fréquence dans PostgreSQL. Pour créer un histogramme dans PostgreSQL, vous pouvez utiliser diverses commandes PostgreSQL Histogram. Nous allons expliquer chacun séparément.
Au départ, assurez-vous que le shell de ligne de commande PostgreSQL et pgAdmin4 sont installés sur votre système informatique. Maintenant, ouvrez le shell de ligne de commande PostgreSQL pour commencer à travailler sur les histogrammes. Il vous demandera immédiatement d'entrer le nom du serveur sur lequel vous souhaitez travailler. Par défaut, le serveur 'localhost' a été sélectionné. Si vous n'en entrez pas en passant à l'option suivante, il continuera avec la valeur par défaut. Après cela, il vous demandera d'entrer le nom de la base de données, le numéro de port et le nom d'utilisateur sur lesquels travailler. Si vous n'en fournissez pas, il continuera avec celui par défaut. Comme vous pouvez le voir sur l'image jointe ci-dessous, nous allons travailler sur la base de données « test ». Enfin, entrez votre mot de passe pour l'utilisateur en particulier et préparez-vous.
Exemple 01 :
Nous devons avoir des tables et des données dans notre base de données pour travailler dessus. Nous avons donc créé une table 'produit' dans la base de données 'test' pour sauvegarder les enregistrements des différentes ventes de produits. Ce tableau occupe deux colonnes. L'un est 'order_date' pour enregistrer la date à laquelle la commande a été effectuée, et l'autre est 'p_sold' pour enregistrer le nombre total de ventes à une date particulière. Essayez la requête ci-dessous dans votre shell de commande pour créer cette table.
>> CREATE TABLE product( order_date DATE, p_sold INT);
Pour le moment, la table est vide, nous devons donc y ajouter des enregistrements. Alors, essayez la commande INSERT ci-dessous dans le shell pour le faire.
>> INSÉRER DANS LES VALEURS du produit ('2021-03-01',1250), ('2021-04-02',555), ('2021-06-03',500), ('2021-05-04' ,1000), ('2021-10-05',890), ('2021-12-10',1000), ('2021-01-06',345), ('2021-11-07',467 ), ('2021-02-08', 1250), ('2021-07-09', 789);
Vous pouvez maintenant vérifier que la table contient des données à l'aide de la commande SELECT comme cité ci-dessous.
>> SÉLECTIONNER * À PARTIR du produit ;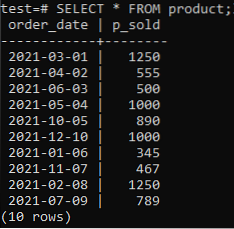
Utilisation du sol et du bac :
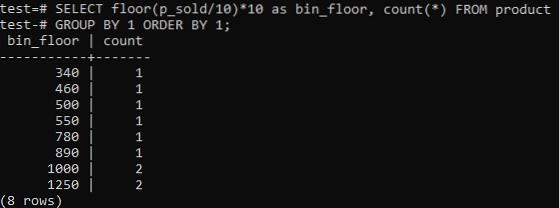
Si vous aimez que les bacs d'histogramme PostgreSQL fournissent des périodes similaires (10-20, 20-30, 30-40, etc.), exécutez la commande SQL ci-dessous. Nous estimons le nombre de bacs à partir de la déclaration ci-dessous en divisant la valeur de vente par une taille de bac d'histogramme, 10.
Cette approche a l'avantage de changer dynamiquement les bacs à mesure que des données sont ajoutées, supprimées ou modifiées. Il ajoute également des bacs supplémentaires pour les nouvelles données et/ou supprime des bacs si leur nombre atteint zéro. En conséquence, vous pouvez générer des histogrammes efficacement dans PostgreSQL.
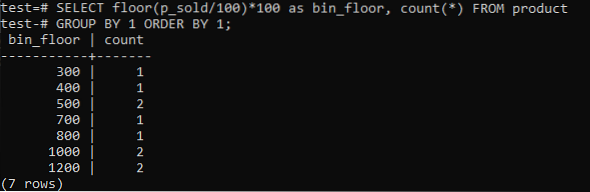
Étage de changement(p_sold/10)*10 avec étage(p_sold/100)*100 pour augmenter la taille du bac jusqu'à 100.
Utilisation de la clause WHERE :
Vous allez construire une distribution de fréquence en utilisant la déclaration CASE pendant que vous comprenez les bacs d'histogramme à générer ou comment les tailles de conteneur d'histogramme varient. Pour PostgreSQL, vous trouverez ci-dessous une autre instruction Histogram :
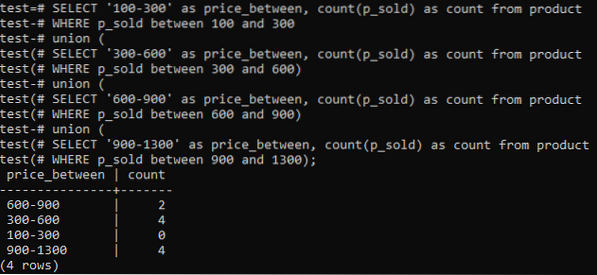
>> SÉLECTIONNER '100-300' AS price_between, COUNT(p_sold) COMME COUNT FROM product WHERE p_sold BETWEEN 100 AND 300 UNION (SELECT '300-600' AS price_between, COUNT(p_sold) AS COUNT FROM product WHERE p_sold BETWEEN 300 AND 600 ) UNION (SELECT '600-900' AS price_between, COUNT(p_sold) AS COUNT FROM product WHERE p_sold BETWEEN 600 AND 900) UNION (SELECT '900-1300' AS price_between, COUNT(p_sold) AS COUNT FROM product WHERE p_sold BETWEEN 900 ET 1300);Et la sortie montre la distribution de fréquence de l'histogramme pour les valeurs de plage totales de la colonne 'p_sold' et le nombre de comptage. Les prix vont de 300-600 et 900-1300 a un nombre total de 4 séparément. La gamme de vente de 600-900 a eu 2 comptes tandis que la gamme 100-300 a eu 0 compte de vente.
Exemple 02 :
Considérons un autre exemple pour illustrer des histogrammes dans PostgreSQL. Nous avons créé une table 'student' en utilisant la commande citée ci-dessous dans le shell. Cette table stockera les informations concernant les étudiants et le nombre de numéros d'échec qu'ils ont.
>> CREATE TABLE student(std_id INT, fail_count INT);
La table doit contenir des données. Nous avons donc exécuté la commande INSERT INTO pour ajouter des données dans la table 'student' comme :
>> INSÉRER DANS LES VALEURS DES ÉTUDIANTS (111, 30), (112, 60), (113, 90), (114, 3), (115, 120), (116, 150), (117, 180), (118 , 210), (119, 5), (120, 300), (121, 380), (122, 470), (123, 530), (124, 9), (125, 550), (126, 50 ), (127, 40), (128, 8);
Maintenant, le tableau a été rempli avec une énorme quantité de données selon la sortie affichée. Il a des valeurs aléatoires pour std_id et le fail_count des étudiants.
>> SÉLECTIONNER * DE L'étudiant;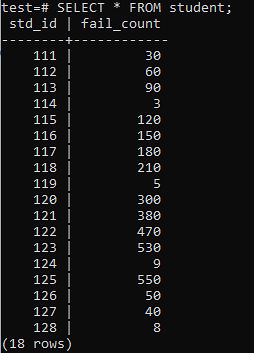
Lorsque vous essayez d'exécuter une requête simple pour collecter le nombre total d'échecs d'un étudiant, vous obtenez le résultat ci-dessous. La sortie n'affiche qu'une seule fois le nombre d'échecs de chaque élève à partir de la méthode 'count' utilisée dans la colonne 'std_id'. Cela n'a pas l'air très satisfaisant.
>> SELECT fail_count, COUNT(std_id) FROM student GROUP BY 1 ORDER BY 1 ;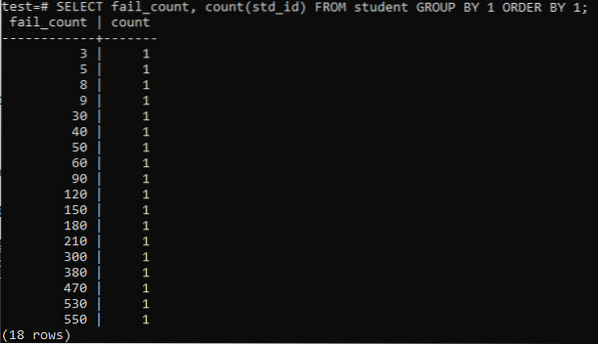
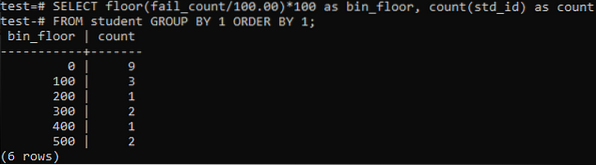
Nous utiliserons à nouveau la méthode du plancher dans ce cas pour des périodes ou des plages similaires. Alors, exécutez la requête ci-dessous dans le shell de commande. La requête divise le nombre d'élèves 'fail_count' par 100.00 puis applique la fonction floor pour créer un bac de taille 100. Ensuite, il résume le nombre total d'étudiants résidant dans cette plage particulière.
Conclusion:
Nous pouvons générer un histogramme avec PostgreSQL en utilisant l'une des techniques mentionnées précédemment, en fonction des exigences. Vous pouvez modifier les compartiments de l'histogramme pour chaque plage que vous souhaitez ; des intervalles uniformes ne sont pas nécessaires. Tout au long de ce tutoriel, nous avons essayé d'expliquer les meilleurs exemples pour clarifier votre concept concernant la création d'histogrammes dans PostgreSQL. J'espère qu'en suivant l'un de ces exemples, vous pourrez facilement créer un histogramme pour vos données dans PostgreSQL.


