La localisation et la sélection d'éléments de la page Web sont la clé du grattage Web avec Selenium. Pour localiser et sélectionner des éléments de la page Web, vous pouvez utiliser des sélecteurs XPath dans Selenium.
Dans cet article, je vais vous montrer comment localiser et sélectionner des éléments de pages Web à l'aide de sélecteurs XPath dans Selenium avec la bibliothèque python Selenium. Alors, commençons.
Conditions préalables:
Pour essayer les commandes et exemples de cet article, vous devez avoir,
- Une distribution Linux (de préférence Ubuntu) installée sur votre ordinateur.
- Python 3 installé sur votre ordinateur.
- PIP 3 installé sur votre ordinateur.
- Python virtualenv package installé sur votre ordinateur.
- Navigateurs Web Mozilla Firefox ou Google Chrome installés sur votre ordinateur.
- Doit savoir comment installer le pilote Firefox Gecko ou le pilote Web Chrome.
Pour remplir les conditions 4, 5 et 6, lisez mon article Introduction à Selenium en Python 3. Vous pouvez trouver de nombreux articles sur les autres sujets sur LinuxHint.com. N'oubliez pas de les consulter si vous avez besoin d'aide.
Configuration d'un répertoire de projet :
Pour que tout reste organisé, créez un nouveau répertoire de projet sélénium-xpath/ comme suit:
$ mkdir -pv sélénium-xpath/drivers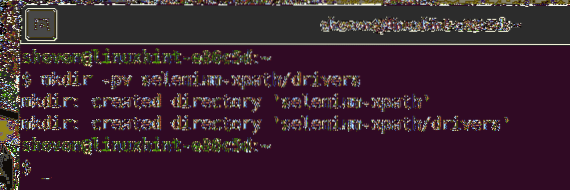
Naviguez vers le sélénium-xpath/ répertoire du projet comme suit :
$ cd sélénium-xpath/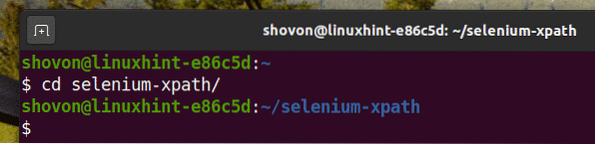
Créez un environnement virtuel Python dans le répertoire du projet comme suit :
$ virtualenv .venv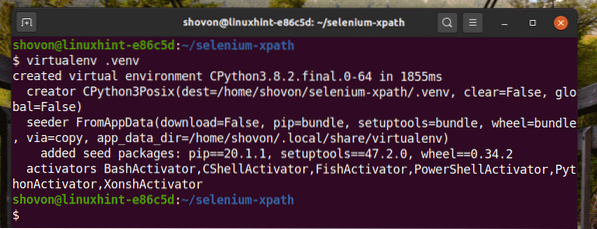
Activez l'environnement virtuel comme suit :
$ source .venv/bin/activer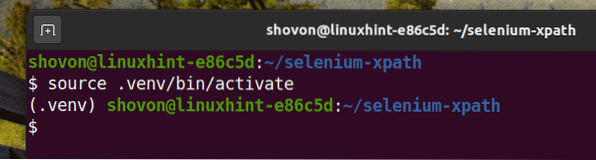
Installez la bibliothèque Selenium Python à l'aide de PIP3 comme suit :
$ pip3 installer le sélénium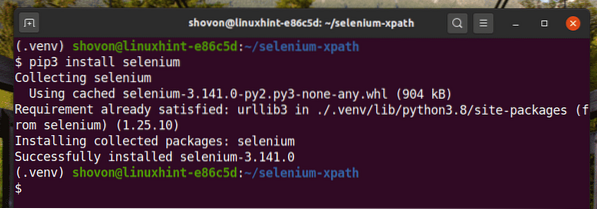
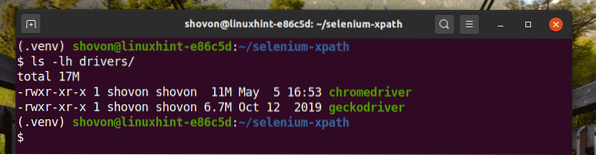
Téléchargez et installez tous les pilotes Web requis dans le Conducteurs/ répertoire du projet. J'ai expliqué le processus de téléchargement et d'installation des pilotes Web dans mon article Introduction à Selenium en Python 3.
Obtenez le sélecteur XPath à l'aide de l'outil de développement Chrome :
Dans cette section, je vais vous montrer comment trouver le sélecteur XPath de l'élément de page Web que vous souhaitez sélectionner avec Selenium à l'aide de l'outil de développement intégré du navigateur Web Google Chrome.
Pour obtenir le sélecteur XPath à l'aide du navigateur Web Google Chrome, ouvrez Google Chrome et visitez le site Web à partir duquel vous souhaitez extraire des données. Ensuite, appuyez sur le bouton droit de la souris (RMB) sur une zone vide de la page et cliquez sur Inspecter pour ouvrir le Outil de développement Chrome.
Vous pouvez également appuyer sur
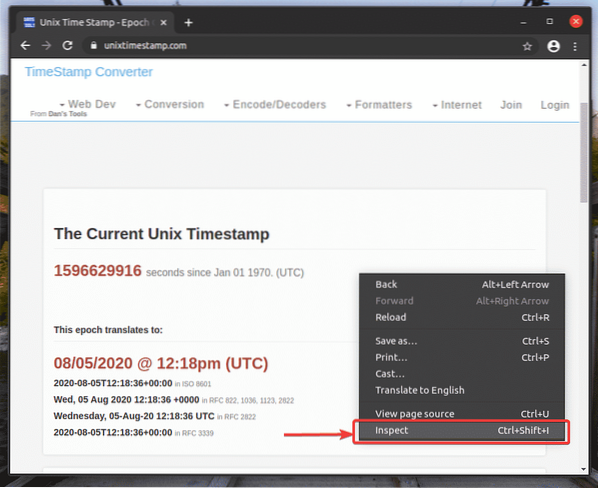
Outil de développement Chrome devrait être ouvert.
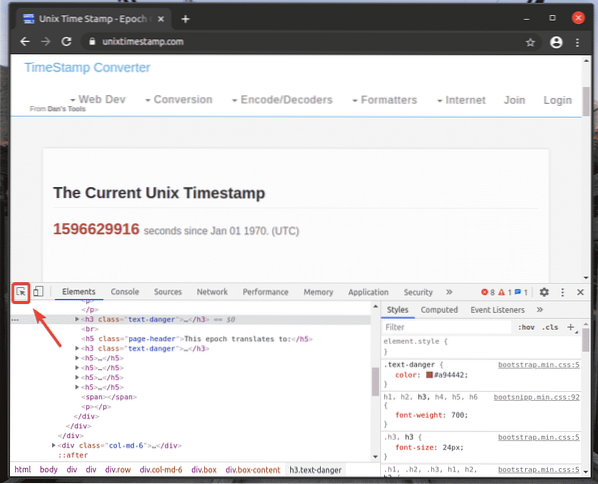
Pour trouver la représentation HTML de l'élément de page Web souhaité, cliquez sur le bouton Inspecter(
), comme indiqué dans la capture d'écran ci-dessous.
Ensuite, survolez l'élément de page Web souhaité et appuyez sur le bouton gauche de la souris (LMB) pour le sélectionner.
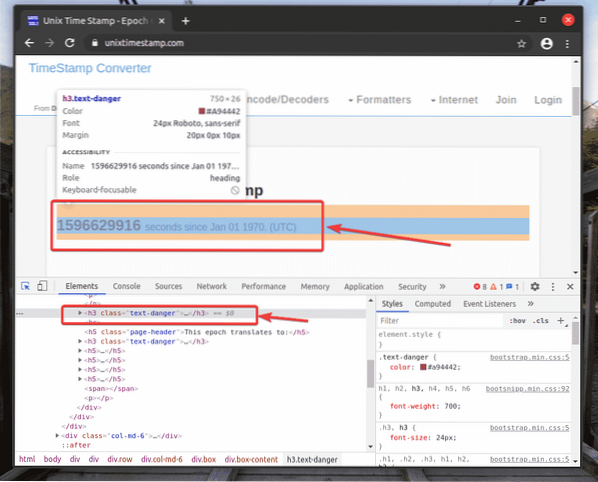
La représentation HTML de l'élément Web que vous avez sélectionné sera mise en surbrillance dans le Éléments onglet du Outil de développement Chrome, comme vous pouvez le voir dans la capture d'écran ci-dessous.
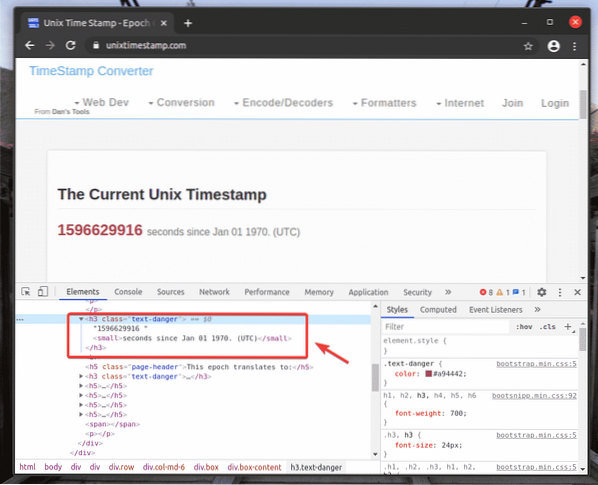
Pour obtenir le sélecteur XPath de l'élément souhaité, sélectionnez l'élément dans le Éléments onglet de Outil de développement Chrome et faites un clic droit (RMB) dessus. Ensuite, sélectionnez Copie > Copier XPath, comme indiqué dans la capture d'écran ci-dessous.
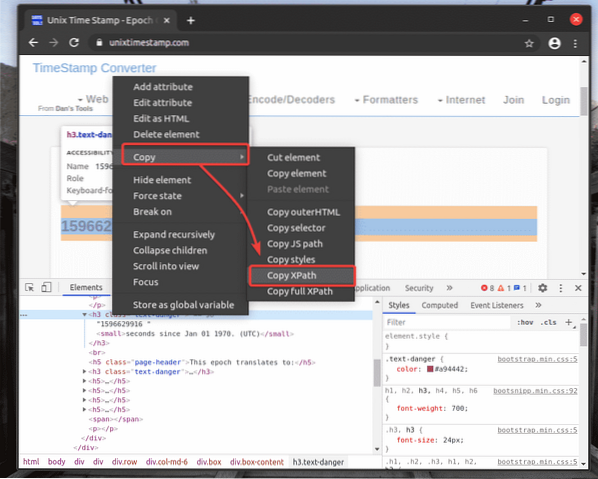
J'ai collé le sélecteur XPath dans un éditeur de texte. Le sélecteur XPath ressemble à celui indiqué dans la capture d'écran ci-dessous.

Obtenez le sélecteur XPath à l'aide de l'outil de développement Firefox :
Dans cette section, je vais vous montrer comment trouver le sélecteur XPath de l'élément de page Web que vous souhaitez sélectionner avec Selenium à l'aide de l'outil de développement intégré du navigateur Web Mozilla Firefox.
Pour obtenir le sélecteur XPath à l'aide du navigateur Web Firefox, ouvrez Firefox et visitez le site Web à partir duquel vous souhaitez extraire des données. Ensuite, appuyez sur le bouton droit de la souris (RMB) sur une zone vide de la page et cliquez sur Inspecter l'élément (Q) pour ouvrir le Outil de développement Firefox.
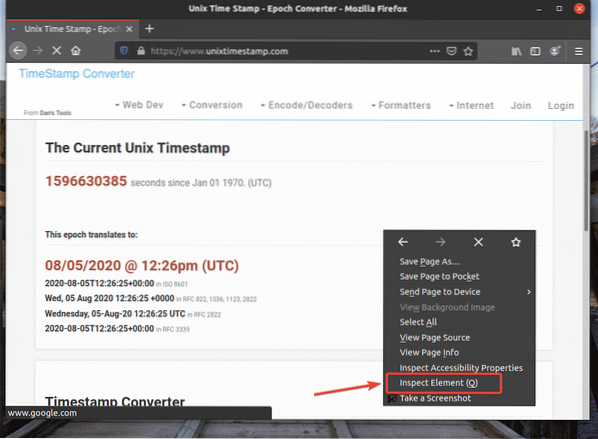
Outil de développement Firefox devrait être ouvert.
Pour trouver la représentation HTML de l'élément de page Web souhaité, cliquez sur le bouton Inspecter(
), comme indiqué dans la capture d'écran ci-dessous.
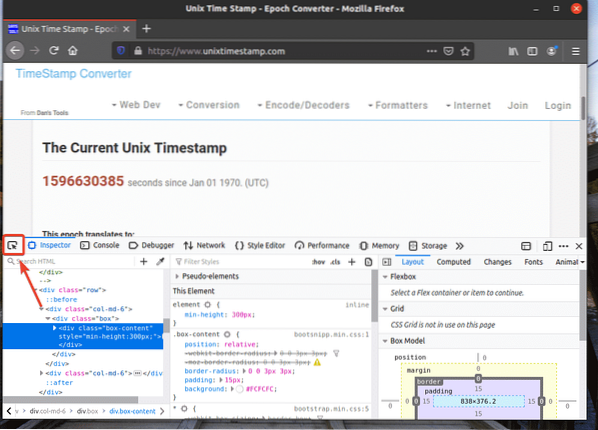
Ensuite, survolez l'élément de page Web souhaité et appuyez sur le bouton gauche de la souris (LMB) pour le sélectionner.
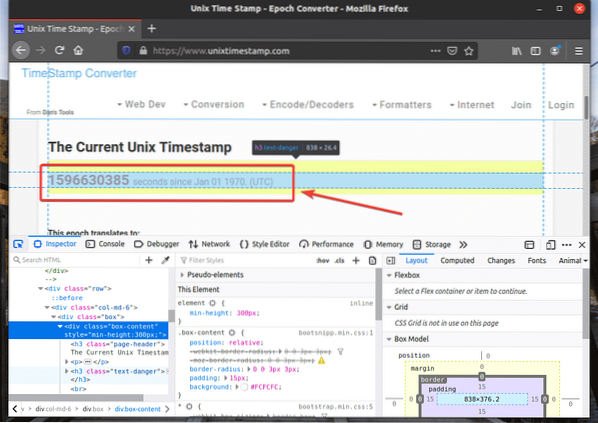
La représentation HTML de l'élément Web que vous avez sélectionné sera mise en surbrillance dans le Inspecteur onglet de Outil de développement Firefox, comme vous pouvez le voir dans la capture d'écran ci-dessous.
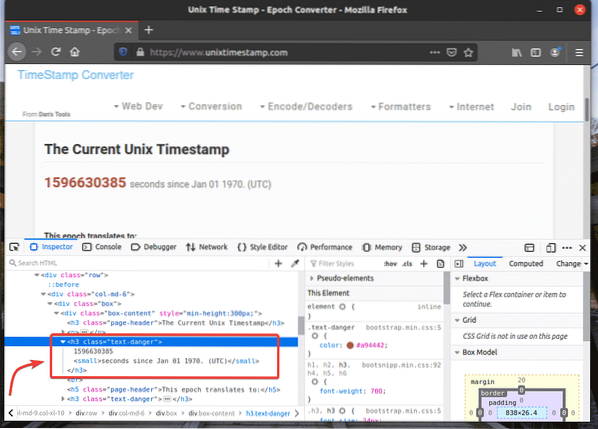
Pour obtenir le sélecteur XPath de l'élément souhaité, sélectionnez l'élément dans le Inspecteur onglet de Outil de développement Firefox et faites un clic droit (RMB) dessus. Ensuite, sélectionnez Copie > XPath comme indiqué dans la capture d'écran ci-dessous.
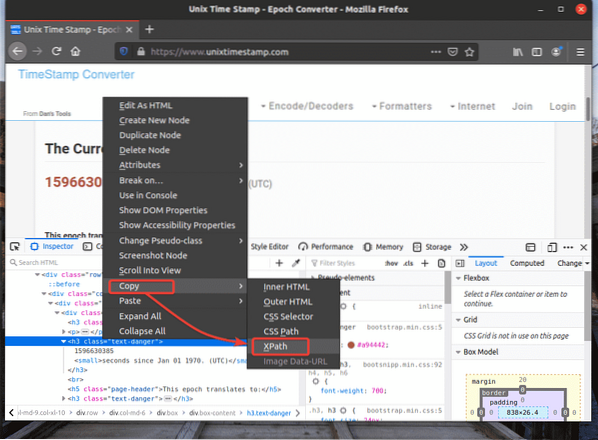
Le sélecteur XPath de l'élément souhaité devrait ressembler à ceci.

Extraction de données à partir de pages Web à l'aide du sélecteur XPath :
Dans cette section, je vais vous montrer comment sélectionner des éléments de page Web et en extraire des données à l'aide de sélecteurs XPath avec la bibliothèque Selenium Python.
Tout d'abord, créez un nouveau script Python ex01.py et tapez les lignes de codes suivantes.
à partir du pilote Web d'importation de séléniumdu sélénium.pilote Web.commun.clés importer des clés
du sélénium.pilote Web.commun.par importation par
options = pilote Web.Options Chrome()
options.sans tête = vrai
navigateur = pilote Web.Chrome(executable_path="./drivers/chromedriver",
options=options)
le navigateur.obtenir("https://www.unixtimestamp.com/")
horodatage = navigateur.find_element_by_xpath('/html/body/div[1]/div[1]
/div[2]/div[1]/div/div/h3[2]')
print('Horodatage actuel : %s' % (horodatage.texte.diviser(")[0]))
le navigateur.Fermer()
Une fois que vous avez terminé, enregistrez le ex01.py Script Python.
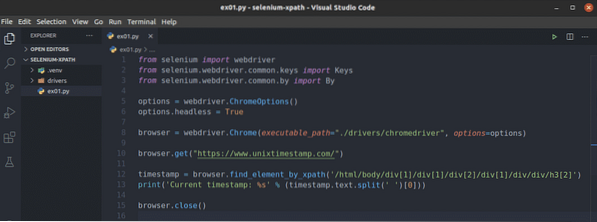
La ligne 1-3 importe tous les composants Selenium requis.

La ligne 5 crée un objet Options Chrome et la ligne 6 active le mode sans tête pour le navigateur Web Chrome.

La ligne 8 crée un Chrome le navigateur objet en utilisant le Chromedriver binaire de la Conducteurs/ répertoire du projet.

La ligne 10 indique au navigateur de charger le site Web unixtimestamp.com.

La ligne 12 recherche l'élément qui contient les données d'horodatage de la page à l'aide du sélecteur XPath et les stocke dans le horodatage variable.
La ligne 13 analyse les données d'horodatage de l'élément et les imprime sur la console.

J'ai copié le sélecteur XPath du marqué h2 élément de unixtimestamp.com à l'aide de l'outil de développement Chrome.
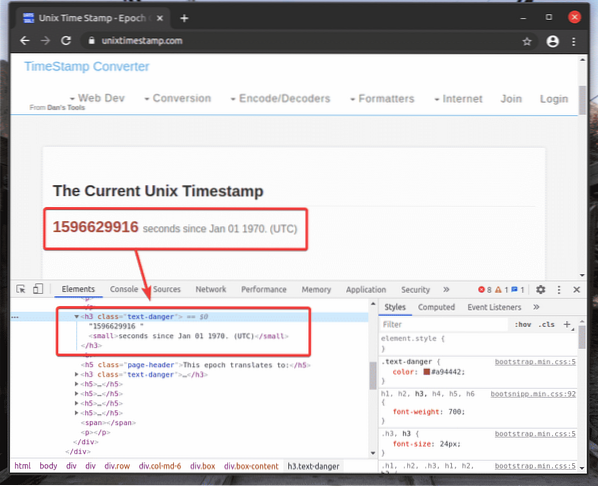
La ligne 14 ferme le navigateur.

Exécutez le script Python ex01.py comme suit:
$ python3 ex01.py
Comme vous pouvez le voir, les données d'horodatage sont imprimées à l'écran.
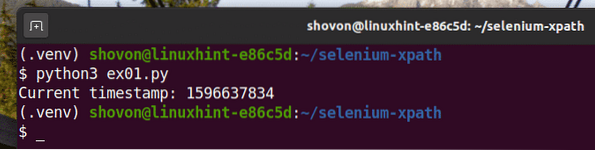
Ici, j'ai utilisé le le navigateur.find_element_by_xpath(sélecteur) méthode. Le seul paramètre de cette méthode est le sélecteur, qui est le sélecteur XPath de l'élément.
À la place de le navigateur.find_element_by_xpath() méthode, vous pouvez également utiliser le navigateur.find_element(Par, sélecteur) méthode. Cette méthode nécessite deux paramètres. Le premier paramètre Par sera Par.XPATH car nous utiliserons le sélecteur XPath, et le deuxième paramètre sélecteur sera le sélecteur XPath lui-même. Le résultat sera le même.
Pour voir comment le navigateur.find_element() la méthode fonctionne pour le sélecteur XPath, créez un nouveau script Python ex02.py, copier et coller toutes les lignes de ex01.py à ex02.py et changer ligne 12 comme indiqué dans la capture d'écran ci-dessous.
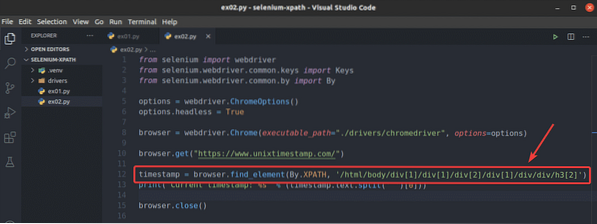
Comme vous pouvez le voir, le script Python ex02.py donne le même résultat que ex01.py.
$ python3 ex02.py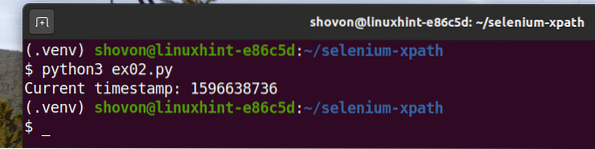
le le navigateur.find_element_by_xpath() et le navigateur.find_element() les méthodes sont utilisées pour rechercher et sélectionner un seul élément dans les pages Web. Si vous souhaitez rechercher et sélectionner plusieurs éléments à l'aide des sélecteurs XPath, vous devez utiliser le navigateur.find_elements_by_xpath() ou alors le navigateur.find_elements() méthodes.
le le navigateur.find_elements_by_xpath() La méthode prend le même argument que la le navigateur.find_element_by_xpath() méthode.
le le navigateur.find_elements() La méthode prend les mêmes arguments que la le navigateur.find_element() méthode.
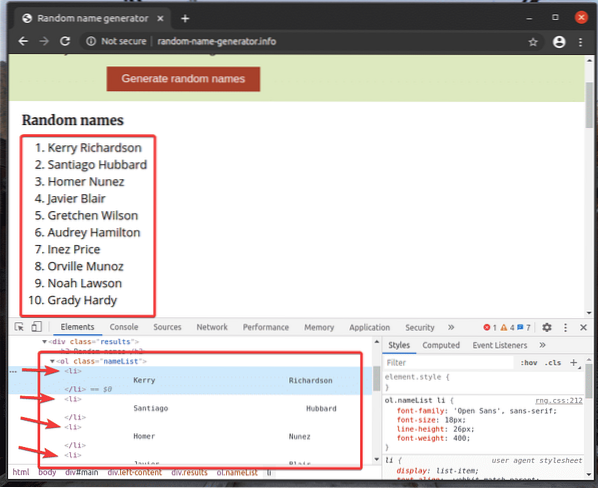
Voyons un exemple d'extraction d'une liste de noms à l'aide du sélecteur XPath de générateur-de-noms-aléatoires.Info avec la bibliothèque Selenium Python.
La liste non ordonnée (vieux balise) a un 10 je suis balises à l'intérieur de chacune contenant un nom aléatoire. Le XPath pour sélectionner tous les je suis balises à l'intérieur du vieux la balise dans ce cas est //*[@id="principal"]/div[3]/div[2]/ol//li
Passons en revue un exemple de sélection de plusieurs éléments de la page Web à l'aide de sélecteurs XPath.
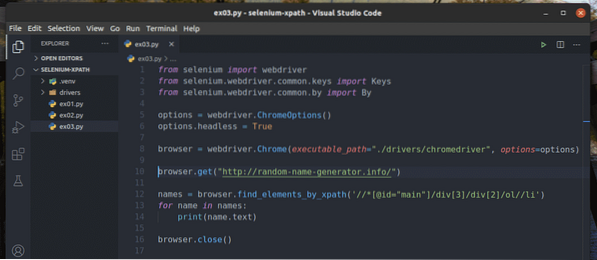
Créer un nouveau script Python ex03.py et tapez les lignes de codes suivantes dedans.
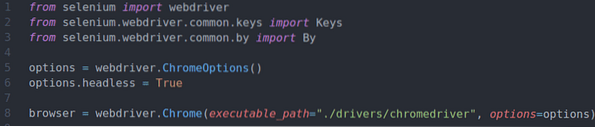
à partir du pilote Web d'importation de séléniumdu sélénium.pilote Web.commun.clés importer des clés
du sélénium.pilote Web.commun.par importation par
options = pilote Web.Options Chrome()
options.sans tête = vrai
navigateur = pilote Web.Chrome(executable_path="./drivers/chromedriver",
options=options)
le navigateur.get("http://random-name-generator.Info/")
noms = navigateur.find_elements_by_xpath('
//*[@id="main"]/div[3]/div[2]/ol//li')
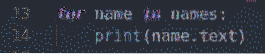
pour le nom dans les noms :
imprimer(nom.texte)
le navigateur.Fermer()
Une fois que vous avez terminé, enregistrez le ex03.py Script Python.
La ligne 1-8 est la même que dans ex01.py Script Python. Donc, je ne vais pas les expliquer à nouveau ici.
La ligne 10 indique au navigateur de charger le générateur de noms aléatoires du site Web.Info.

La ligne 12 sélectionne la liste de noms à l'aide de la le navigateur.find_elements_by_xpath() méthode. Cette méthode utilise le sélecteur XPath //*[@id="principal"]/div[3]/div[2]/ol//li pour trouver la liste des noms. Ensuite, la liste de noms est stockée dans le des noms variable.

Aux lignes 13 et 14, un pour la boucle est utilisée pour parcourir le des noms lister et imprimer les noms sur la console.
La ligne 16 ferme le navigateur.

Exécutez le script Python ex03.py comme suit:
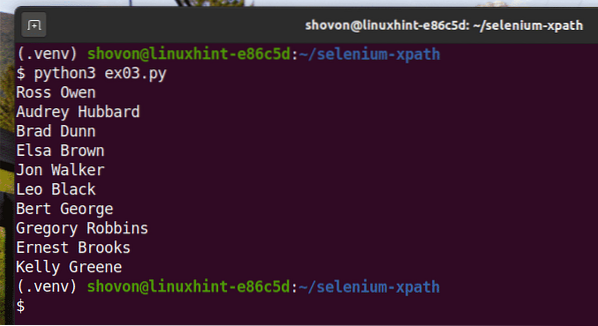
$ python3 ex03.py
Comme vous pouvez le voir, les noms sont extraits de la page Web et imprimés sur la console.
Au lieu d'utiliser le le navigateur.find_elements_by_xpath() méthode, vous pouvez également utiliser la le navigateur.find_elements() méthode comme avant. Le premier argument de cette méthode est Par.XPATH, et le deuxième argument est le sélecteur XPath.
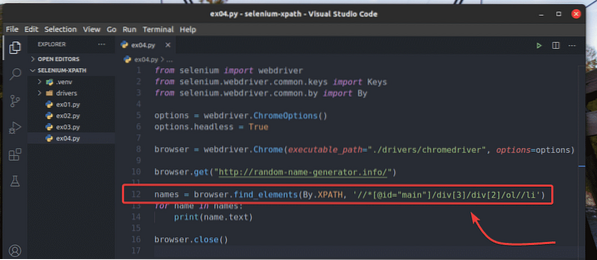
A expérimenter avec le navigateur.find_elements() méthode, créez un nouveau script Python ex04.py, copier tous les codes de ex03.py à ex04.py, et modifiez la ligne 12 comme indiqué dans la capture d'écran ci-dessous.
Vous devriez obtenir le même résultat qu'avant.
$ python3 ex04.py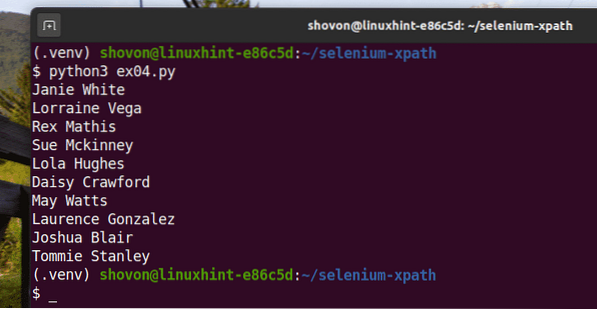
Principes de base du sélecteur XPath :
L'outil de développement du navigateur Web Firefox ou Google Chrome génère automatiquement le sélecteur XPath. Mais ces sélecteurs XPath ne sont parfois pas suffisants pour votre projet. Dans ce cas, vous devez savoir ce que fait un certain sélecteur XPath pour construire votre sélecteur XPath. Dans cette section, je vais vous montrer les bases des sélecteurs XPath. Ensuite, vous devriez pouvoir créer votre propre sélecteur XPath.
Créer un nouveau répertoire www/ dans votre répertoire de projet comme suit :
$ mkdir -v www
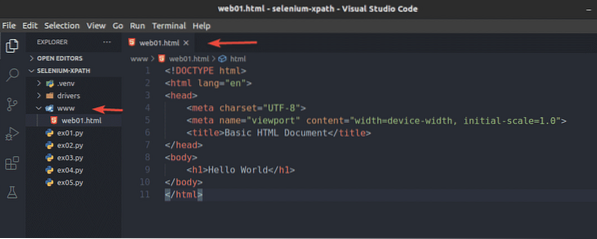
Créer un nouveau fichier web01.html dans le www/ répertoire et tapez les lignes suivantes dans ce fichier.
Bonjour le monde
Une fois que vous avez terminé, enregistrez le web01.html déposer.
Exécutez un simple serveur HTTP sur le port 8080 à l'aide de la commande suivante :
$ python3 -m http.serveur --répertoire www/ 8080
Le serveur HTTP devrait démarrer.
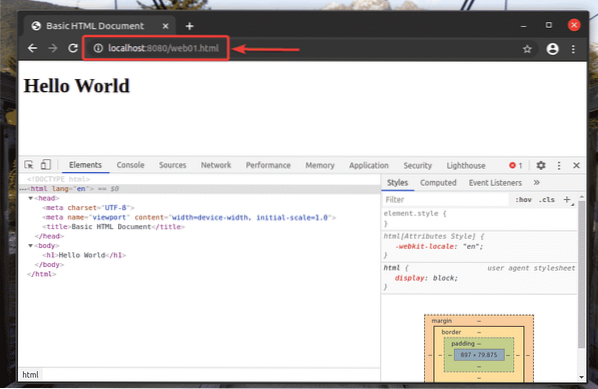
Vous devriez pouvoir accéder au web01.html fichier en utilisant l'URL http://localhost:8080/web01.html, comme vous pouvez le voir dans la capture d'écran ci-dessous.
Lorsque l'outil de développement Firefox ou Chrome est ouvert, appuyez sur
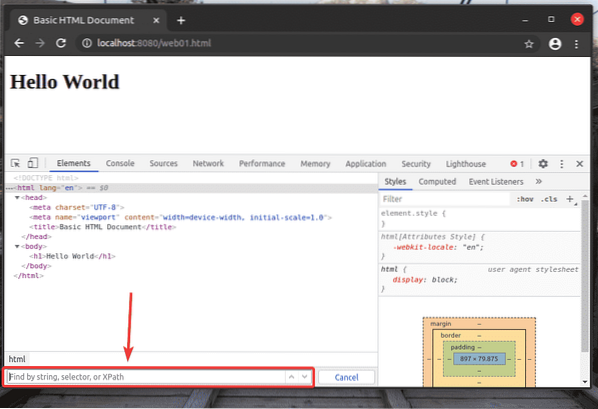
Un sélecteur XPath commence par un barre oblique (/) le plus souvent. C'est comme une arborescence de répertoires Linux. le / est la racine de tous les éléments de la page Web.
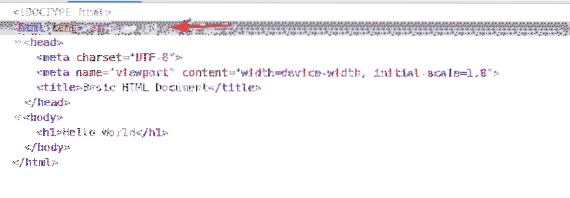
Le premier élément est le html. Ainsi, le sélecteur XPath /html sélectionne l'ensemble html étiqueter.
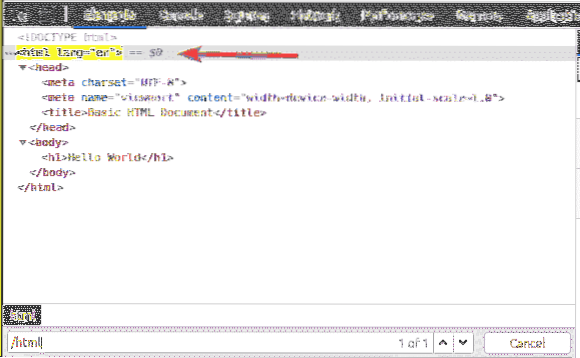
À l'intérieur de html étiquette, nous avons un corps étiqueter. le corps la balise peut être sélectionnée avec le sélecteur XPath /html/corps
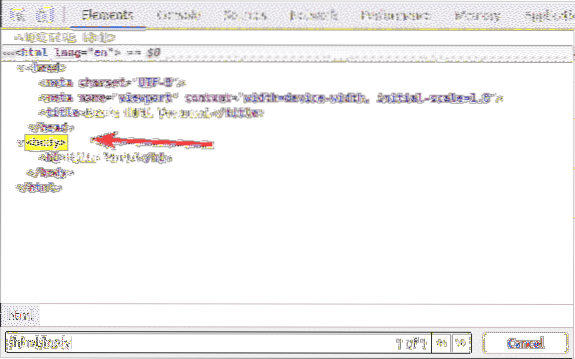
le h1 l'en-tête est à l'intérieur du corps étiqueter. le h1 l'en-tête peut être sélectionné avec le sélecteur XPath /html/corps/h1
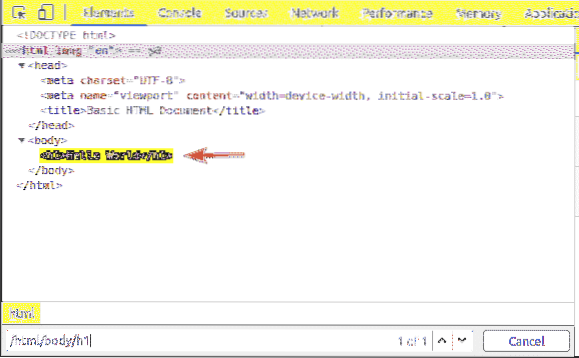
Ce type de sélecteur XPath est appelé sélecteur de chemin absolu. En sélecteur de chemin absolu, vous devez parcourir la page web depuis la racine (/) de la page. L'inconvénient d'un sélecteur de chemin absolu est que même une légère modification de la structure de la page Web peut rendre votre sélecteur XPath invalide. La solution à ce problème est un sélecteur XPath relatif ou partiel.
Pour voir comment fonctionne le chemin relatif ou le chemin partiel, créez un nouveau fichier web02.html dans le www/ répertoire et tapez les lignes de codes suivantes dedans.
Bonjour le monde
c'est un message
Bonjour le monde
Une fois que vous avez terminé, enregistrez le web02.html fichier et chargez-le dans votre navigateur Web.
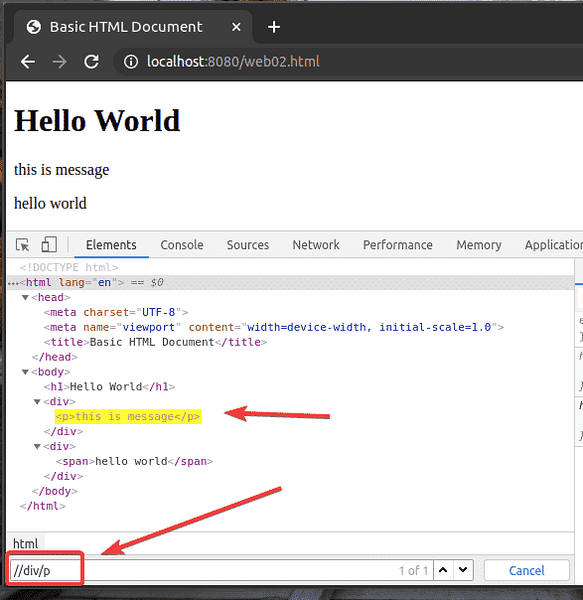
Comme vous pouvez le voir, le sélecteur XPath //div/p sélectionne le p étiquette à l'intérieur du div étiqueter. Ceci est un exemple de sélecteur XPath relatif.
Le sélecteur XPath relatif commence par //. Ensuite, vous spécifiez la structure de l'élément que vous souhaitez sélectionner. Dans ce cas, div/p.
Donc, //div/p signifie sélectionner le p élément à l'intérieur d'un div élément, peu importe ce qui le précède.
Vous pouvez également sélectionner des éléments par différents attributs comme identifiant, classer, taper, etc. en utilisant le sélecteur XPath. Voyons comment faire ça.
Créer un nouveau fichier web03.html dans le www/ répertoire et tapez les lignes de codes suivantes dedans.
Bonjour le monde
c'est un message
c'est un autre message
titre 2
Lorem ipsum dolor sit amet consectetur, adipisicing elit. Quibusdam
eligendi doloribus sapiente, molestias quos quae non nam incident quis delectus
facilis magni officiis alias neque atque fuga? Unde, aut natus?
Une fois que vous avez terminé, enregistrez le web03.html fichier et chargez-le dans votre navigateur Web.
Disons que vous voulez sélectionner tous les div éléments qui ont le classer Nom conteneur1. Pour ce faire, vous pouvez utiliser le sélecteur XPath //div[@class='conteneur1']
Comme vous pouvez le voir, j'ai 2 éléments qui correspondent au sélecteur XPath //div[@class='conteneur1']
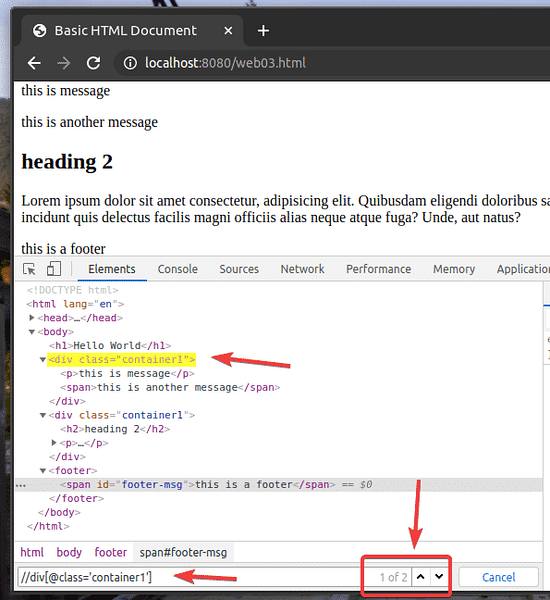
Pour sélectionner le premier div élément avec le classer Nom conteneur1, ajouter [1] à la fin de la sélection XPath, comme indiqué dans la capture d'écran ci-dessous.
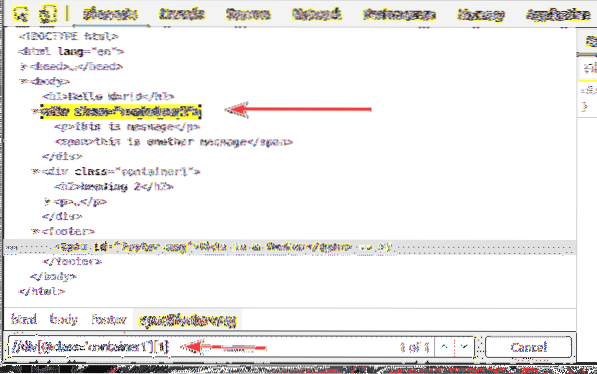
De la même manière, vous pouvez sélectionner le deuxième div élément avec le classer Nom conteneur1 en utilisant le sélecteur XPath //div[@class='container1'][2]
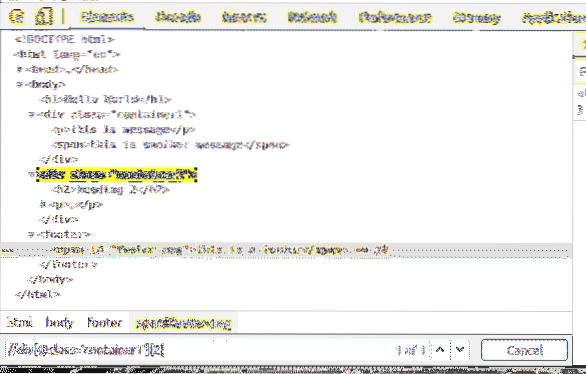
Vous pouvez sélectionner des éléments en identifiant ainsi que.
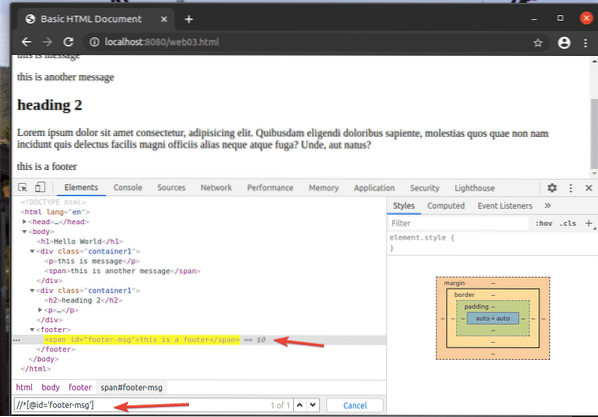
Par exemple, pour sélectionner l'élément qui a le identifiant de footer-msg, vous pouvez utiliser le sélecteur XPath //*[@id='footer-msg']
Ici le * avant que [@id='footer-msg'] est utilisé pour sélectionner n'importe quel élément quelle que soit sa balise.
C'est la base du sélecteur XPath. Maintenant, vous devriez pouvoir créer votre propre sélecteur XPath pour vos projets Selenium.
Conclusion:
Dans cet article, je vous ai montré comment rechercher et sélectionner des éléments de pages Web à l'aide du sélecteur XPath avec la bibliothèque Selenium Python. J'ai également discuté des sélecteurs XPath les plus courants. Après avoir lu cet article, vous devriez vous sentir assez à l'aise pour sélectionner des éléments de pages Web à l'aide du sélecteur XPath avec la bibliothèque Selenium Python.

