Dans cette leçon, nous verrons ce qu'est Apache Kafka et comment cela fonctionne avec ses cas d'utilisation les plus courants. Apache Kafka a été initialement développé sur LinkedIn en 2010 et est devenu un projet Apache de haut niveau en 2012. Il a trois composantes principales :
- Éditeur-Abonné: ce composant est responsable de la gestion et de la livraison efficace des données sur les nœuds Kafka et les applications grand public qui évoluent beaucoup (comme littéralement).
- API de connexion: L'API Connect est la fonctionnalité la plus utile pour Kafka et permet l'intégration de Kafka avec de nombreuses sources de données externes et puits de données.
- Kafka Streams: En utilisant Kafka Streams, nous pouvons envisager de traiter les données entrantes à grande échelle en temps quasi réel.
Nous étudierons beaucoup plus de concepts Kafka dans les prochaines sections. Allons de l'avant.
Concepts Apache Kafka
Avant d'approfondir, nous devons être approfondis sur certains concepts d'Apache Kafka. Voici les termes que nous devrions connaître, très brièvement :
-
- Producteur: Ceci est une application qui envoie un message à Kafka
- Consommateur: C'est une application qui consomme les données de Kafka
- Un message: Données envoyées par l'application Producteur à l'application Consommateur via Kafka
- Lien: Kafka établit une connexion TCP entre le cluster Kafka et les applications
- Sujet: Un sujet est une catégorie à laquelle les données envoyées sont étiquetées et livrées aux applications des consommateurs intéressés
- Partition de sujet: comme un seul sujet peut obtenir beaucoup de données en une seule fois, pour que Kafka reste évolutif horizontalement, chaque sujet est divisé en partitions et chaque partition peut vivre sur n'importe quel nœud d'un cluster. Essayons de le présenter :
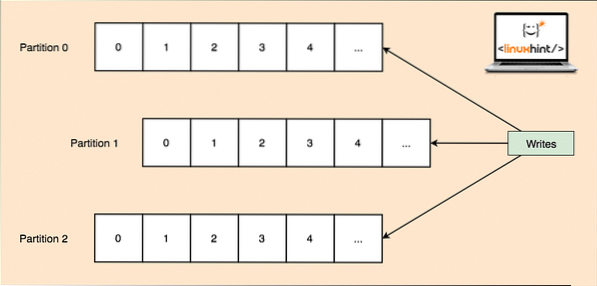
Partitions thématiques
- Les répliques: Comme nous l'avons étudié ci-dessus, un sujet est divisé en partitions, chaque enregistrement de message est répliqué sur plusieurs nœuds du cluster pour maintenir l'ordre et les données de chaque enregistrement au cas où l'un des nœuds meurt.
- Groupes de consommateurs: Plusieurs consommateurs intéressés par le même sujet peuvent être regroupés dans un groupe appelé Groupe de consommateurs
- Décalage: Kafka est évolutif car ce sont les consommateurs qui stockent réellement le dernier message récupéré par eux en tant que valeur « offset ». Cela signifie que pour le même sujet, le décalage du consommateur A peut avoir une valeur de 5, ce qui signifie qu'il doit traiter le sixième paquet ensuite et pour le consommateur B, la valeur de décalage peut être 7, ce qui signifie qu'il doit traiter le huitième paquet ensuite. Cela a complètement supprimé la dépendance au sujet lui-même pour stocker ces métadonnées liées à chaque consommateur.
- Nœud: Un nœud est une machine serveur unique dans le cluster Apache Kafka.
- Groupe: Un cluster est un groupe de nœuds i.e., un groupe de serveurs.
Le concept pour Topic, Topic Partitions et offset peut également être expliqué avec une figure illustrative :
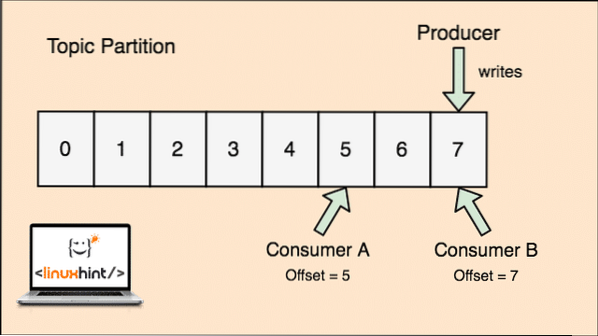
Partition de sujet et décalage de consommateur dans Apache Kafka
Apache Kafka comme système de messagerie de publication-abonnement
Avec Kafka, les applications Producteur publient des messages qui arrivent à un Kafka Node et non directement à un Consumer. A partir de ce nœud Kafka, les messages sont consommés par les applications Consumer.
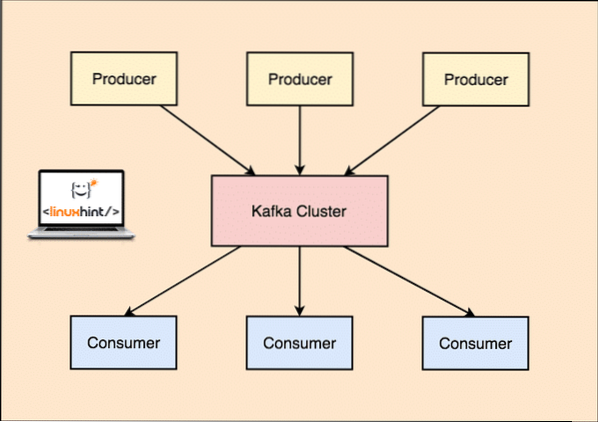
Producteur et consommateur de Kafka
Comme un seul sujet peut obtenir beaucoup de données en une seule fois, pour que Kafka reste évolutif horizontalement, chaque sujet est divisé en partitions et chaque partition peut vivre sur n'importe quelle machine de nœud d'un cluster.
Encore une fois, Kafka Broker n'enregistre pas le consommateur qui a consommé combien de paquets de données. C'est le la responsabilité des consommateurs de garder une trace des données qu'il a consommées. Étant donné que Kafka ne garde pas une trace des accusés de réception et des messages de chaque application client, il peut gérer beaucoup plus de clients avec un impact négligeable sur le débit. En production, de nombreuses applications suivent même un modèle de consommateurs par lots, ce qui signifie qu'un consommateur consomme tous les messages d'une file d'attente à un intervalle de temps régulier.
Installation
Pour commencer à utiliser Apache Kafka, il doit être installé sur la machine. Pour ce faire, lisez Installer Apache Kafka sur Ubuntu.
Cas d'utilisation : suivi de l'utilisation du site Web
Kafka est un excellent outil à utiliser lorsque nous devons suivre l'activité sur un site Web. Les données de suivi incluent, sans s'y limiter, les pages vues, les recherches, les téléchargements ou d'autres actions que les utilisateurs peuvent entreprendre. Lorsqu'un utilisateur est sur un site Web, l'utilisateur peut effectuer un certain nombre d'actions lorsqu'il navigue sur le site Web.
Par exemple, lorsqu'un nouvel utilisateur s'inscrit sur un site Web, l'activité peut être suivie dans quel ordre un nouvel utilisateur explore les fonctionnalités d'un site Web, si l'utilisateur définit son profil selon ses besoins ou préfère sauter directement sur les fonctionnalités du site Internet. Chaque fois que l'utilisateur clique sur un bouton, les métadonnées de ce bouton sont collectées dans un paquet de données et envoyées au cluster Kafka à partir duquel le service d'analyse de l'application peut collecter ces données et produire des informations utiles sur les données associées. Si nous cherchons à diviser les tâches en étapes, voici à quoi ressemblera le processus :
- Un utilisateur s'enregistre sur un site Web et entre dans le tableau de bord. L'utilisateur essaie d'accéder directement à une fonctionnalité en interagissant avec un bouton.
- L'application Web construit un message avec ces métadonnées vers une partition de rubrique de rubrique « clic ».
- Le message est ajouté au journal de validation et l'offset est incrémenté
- Le consommateur peut désormais extraire le message du courtier Kafka et afficher l'utilisation du site Web en temps réel et afficher les données passées s'il réinitialise son décalage à une valeur passée possible
Cas d'utilisation : file d'attente de messages
Apache Kafka est un excellent outil qui peut remplacer les outils de messagerie comme RabbitMQ. La messagerie asynchrone aide à découpler les applications et crée un système hautement évolutif.
Tout comme le concept de microservices, au lieu de créer une seule grande application, nous pouvons diviser l'application en plusieurs parties et chaque partie a une responsabilité très spécifique. De cette façon, les différentes parties peuvent également être écrites dans des langages de programmation complètement indépendants! Kafka dispose d'un système de partitionnement, de réplication et de tolérance aux pannes intégré qui en fait un bon système de courtier de messages à grande échelle.
Récemment, Kafka est également considéré comme une très bonne solution de collecte de journaux qui peut gérer le courtier de serveur de collecte de fichiers journaux et fournir ces fichiers à un système central. Avec Kafka, il est possible de générer n'importe quel événement que vous souhaitez que toute autre partie de votre application connaisse.
Utiliser Kafka sur LinkedIn
Il est intéressant de noter qu'Apache Kafka a été précédemment vu et utilisé comme un moyen de rendre les pipelines de données cohérents et à travers lequel les données ont été ingérées dans Hadoop. Kafka fonctionnait parfaitement lorsque plusieurs sources de données et destinations étaient présentes et qu'il n'était pas possible de fournir un processus de pipeline distinct pour chaque combinaison de source et de destination. L'architecte Kafka de LinkedIn, Jay Kreps décrit bien ce problème familier dans un article de blog :
Ma propre implication dans cela a commencé vers 2008 après que nous ayons expédié notre magasin à valeur-clé. Mon prochain projet consistait à essayer de mettre en place une configuration Hadoop fonctionnelle et d'y déplacer certains de nos processus de recommandation. Ayant peu d'expérience dans ce domaine, nous avons naturellement budgété quelques semaines pour faire entrer et sortir des données, et le reste de notre temps pour mettre en œuvre des algorithmes de prédiction sophistiqués. Alors commença un long travail.
Apache Kafka et Flume
Si vous vous déplacez pour comparer ces deux sur la base de leurs fonctions, vous trouverez de nombreuses caractéristiques communes. En voici quelques uns:
- Il est recommandé d'utiliser Kafka lorsque plusieurs applications consomment les données au lieu de Flume, qui est spécialement conçu pour être intégré à Hadoop et ne peut être utilisé que pour ingérer des données dans HDFS et HBase. Flume est optimisé pour les opérations HDFS.
- Avec Kafka, c'est un inconvénient de devoir coder les applications producteurs et consommateurs alors que dans Flume, il a de nombreuses sources et puits intégrés. Cela signifie que si les besoins existants correspondent aux fonctionnalités de Flume, il est recommandé d'utiliser Flume lui-même pour gagner du temps.
- Flume peut consommer des données en vol à l'aide d'intercepteurs. Cela peut être important pour le masquage et le filtrage des données alors que Kafka a besoin d'un système de traitement de flux externe.
- Il est possible pour Kafka d'utiliser Flume en tant que consommateur lorsque nous devons ingérer des données vers HDFS et HBase. Cela signifie que Kafka et Flume s'intègrent très bien.
- Kakfa et Flume peuvent garantir une perte de données nulle avec une configuration correcte, ce qui est également facile à réaliser. Néanmoins, pour souligner, Flume ne réplique pas les événements, ce qui signifie que si l'un des nœuds Flume échoue, nous perdrons l'accès aux événements jusqu'à ce que le disque soit récupéré
Conclusion
Dans cette leçon, nous avons examiné de nombreux concepts sur Apache Kafka. Lire plus de messages basés sur Kafka ici.


