20 exemples maladroits
De nombreux outils utilitaires existent dans le système d'exploitation Linux pour rechercher et générer un rapport à partir de données texte ou d'un fichier. L'utilisateur peut facilement effectuer de nombreux types de tâches de recherche, de remplacement et de génération de rapports à l'aide des commandes awk, grep et sed. awk n'est pas seulement une commande. C'est un langage de script qui peut être utilisé à la fois depuis un terminal et un fichier awk. Il prend en charge la variable, l'instruction conditionnelle, le tableau, les boucles, etc. comme les autres langages de script. Il peut lire n'importe quel contenu de fichier ligne par ligne et séparer les champs ou les colonnes en fonction d'un délimiteur spécifique. Il prend également en charge l'expression régulière pour rechercher une chaîne particulière dans le contenu texte ou le fichier et prend des mesures si une correspondance est trouvée. Comment vous pouvez utiliser la commande et le script awk est montré dans ce tutoriel en utilisant 20 exemples utiles.
Contenu:
- awk avec printf
- awk à diviser sur un espace blanc
- awk pour changer le délimiteur
- awk avec des données délimitées par des tabulations
- awk avec des données csv
- regex awk
- awk regex insensible à la casse
- awk avec la variable nf (nombre de champs)
- fonction awk gensub()
- awk avec la fonction rand()
- fonction définie par l'utilisateur awk
- ok si
- variables awk
- tableaux awk
- boucle awk
- awk pour imprimer la première colonne
- awk pour imprimer la dernière colonne
- awk avec grep
- awk avec le fichier de script bash
- awk avec sed
Utiliser awk avec printf
printf() La fonction est utilisée pour formater n'importe quelle sortie dans la plupart des langages de programmation. Cette fonction peut être utilisée avec ok commande pour générer différents types de sorties formatées. commande awk principalement utilisée pour tout fichier texte. Créer un fichier texte nommé employé.SMS avec le contenu donné ci-dessous où les champs sont séparés par des tabulations ('\t').
employé.SMS
1001 Jean sena 400001002 Jafar Iqbal 60000
1003 Meher Nigar 30000
1004 Jonny Liver 70000
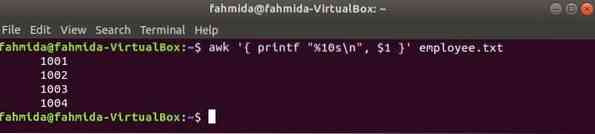
La commande awk suivante lira les données de employé.SMS fichier ligne par ligne et imprimer le premier fichier après formatage. Ici, "%10s\n” signifie que la sortie comportera 10 caractères. Si la valeur de la sortie est inférieure à 10 caractères alors les espaces seront ajoutés devant la valeur.
$ awk ' printf "%10s\n", $1 ' employé.SMSProduction:
Aller au contenu
awk à diviser sur un espace blanc
Le séparateur de mots ou de champs par défaut pour diviser n'importe quel texte est un espace blanc. La commande awk peut prendre la valeur du texte en entrée de différentes manières. Le texte saisi est passé de écho commande dans l'exemple suivant. Le texte, 'j'aime programmer' sera divisé par le séparateur par défaut, espace, et le troisième mot sera imprimé en sortie.
$ echo 'J'aime programmer' | awk ' print $3 'Production:

Aller au contenu
awk pour changer le délimiteur
La commande awk peut être utilisée pour modifier le délimiteur de tout contenu de fichier. Supposons que vous ayez un fichier texte nommé téléphoner.SMS avec le contenu suivant où ':' est utilisé comme séparateur de champ du contenu du fichier.
téléphoner.SMS
+123:334:889:778+880 : 1855 : 456 : 907
+9:7777:38644:808
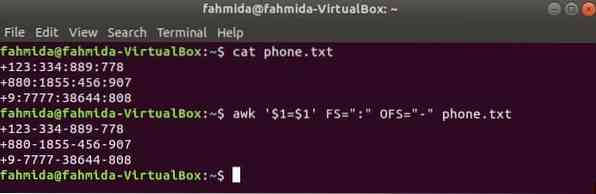
Exécutez la commande awk suivante pour modifier le délimiteur, ':' par '-' au contenu du fichier, téléphoner.SMS.
$ chat téléphone.SMS$ awk '$1=$1' FS=":" OFS="-" téléphone.SMS
Production:
Aller au contenu
awk avec des données délimitées par des tabulations
La commande awk a de nombreuses variables intégrées qui sont utilisées pour lire le texte de différentes manières. Deux d'entre eux sont FS et OFS. FS est le séparateur de champ d'entrée et OFS est des variables de séparation de champ de sortie. Les utilisations de ces variables sont présentées dans cette section. Créer un languette fichier séparé nommé contribution.SMS avec le contenu suivant pour tester les utilisations de FS et OFS variables.
Contribution.SMS
Langage de script côté clientLangage de script côté serveur
Serveur de base de données
Serveur Web
Utilisation de la variable FS avec onglet
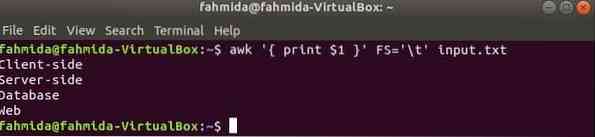
La commande suivante divisera chaque ligne de contribution.SMS fichier basé sur l'onglet ('\t') et imprimez le premier champ de chaque ligne.
$ awk ' print $1 ' FS='\t' entrée.SMSProduction:
Utilisation de la variable OFS avec tabulation
La commande awk suivante imprimera le 9e et 5e champs de 'ls -l' sortie de la commande avec séparateur de tabulation après impression du titre de la colonne "Nom" et "Taille". Ici, OFS variable est utilisée pour formater la sortie par un onglet.
$ ls -l$ ls -l | awk -v OFS='\t' 'BEGIN printf "%s\t%s\n", "Nom", "Taille" print $9,$5'
Production:

Aller au contenu
awk avec des données CSV
Le contenu de n'importe quel fichier CSV peut être analysé de plusieurs manières à l'aide de la commande awk. Créez un fichier CSV nommé 'client.csv' avec le contenu suivant pour appliquer la commande awk.
client.SMS
Identifiant, nom, e-mail, téléphone1, Sophia, [email protégé], (862) 478-7263
2, Amelia, [email protégé], (530) 764-8000
3, Emma, [email protégé], (542) 986-2390
Lecture d'un seul champ du fichier CSV
'-F' L'option est utilisée avec la commande awk pour définir le délimiteur pour diviser chaque ligne du fichier. La commande awk suivante imprimera le Nom domaine de le consommateur.csv déposer.
$ chat client.csv$ awk -F "," 'print $2' client.csv
Production: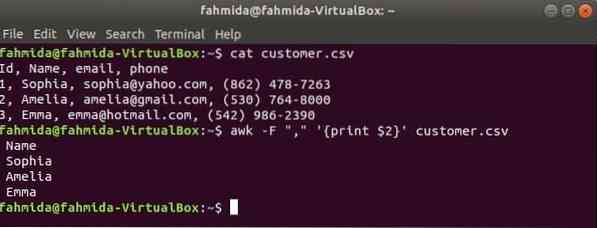
Lecture de plusieurs champs en combinant avec un autre texte
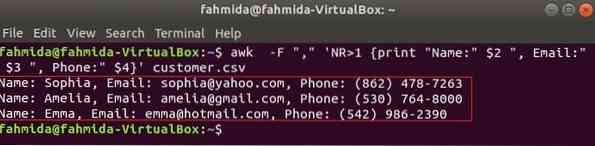
La commande suivante imprimera trois champs de client.csv en combinant le texte du titre, Nom, e-mail et téléphone. La première ligne du client.csv le fichier contient le titre de chaque champ. NR la variable contient le numéro de ligne du fichier lorsque la commande awk analyse le fichier. Dans cet exemple, le NR variable est utilisée pour omettre la première ligne du fichier. La sortie affichera le 2sd, 3rd et 4e champs de toutes les lignes sauf la première ligne.
$ awk -F "," 'NR>1 print "Name :" $2 ", E-mail :" $3 ", Téléphone :" $4' client.csvProduction:
Lecture d'un fichier CSV à l'aide d'un script awk
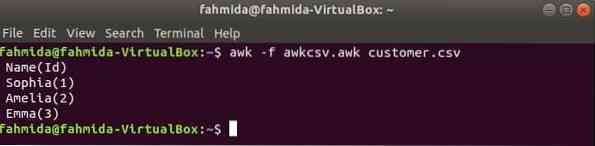
le script awk peut être exécuté en exécutant le fichier awk. Comment vous pouvez créer un fichier awk et exécuter le fichier est montré dans cet exemple. Créer un fichier nommé awkcsv.ok avec le code suivant. COMMENCER le mot-clé est utilisé dans le script pour informer la commande awk d'exécuter le script du COMMENCER partie d'abord avant d'exécuter d'autres tâches. Ici, le séparateur de champs (FS) est utilisé pour définir le délimiteur de fractionnement et 2sd et 1st les champs seront imprimés selon le format utilisé dans la fonction printf().
awkcsv.okCOMMENCER FS = "," printf "%5s(%s)\n", $2,$1
Cours awkcsv.ok fichier avec le contenu de le consommateur.csv fichier par la commande suivante.
$ awk -f awkcsv.client maladroit.csvProduction:
Aller au contenu
regex awk
L'expression régulière est un modèle qui est utilisé pour rechercher n'importe quelle chaîne dans un texte. Différents types de tâches de recherche et de remplacement complexes peuvent être effectués très facilement en utilisant l'expression régulière. Quelques utilisations simples de l'expression régulière avec la commande awk sont présentées dans cette section.
Jeu de caractères correspondantLa commande suivante correspondra au mot Fou ou idiot ou alors Frais avec la chaîne d'entrée et imprimer si le mot trouve. Ici, Poupée ne correspondra pas et ne s'imprimera pas.
$ printf "Imbécile\nCool\nPoupée\nbool" | awk '/[FbC]ool/'Production:

Recherche de chaîne en début de ligne
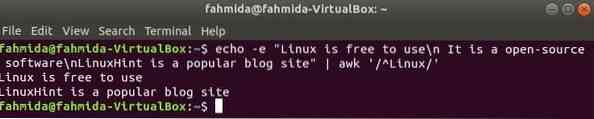
'^' le symbole est utilisé dans l'expression régulière pour rechercher n'importe quel motif au début de la ligne. 'Linux' mot sera recherché au début de chaque ligne du texte dans l'exemple suivant. Ici, deux lignes commencent par le texte, 'Linux' et ces deux lignes seront affichées dans la sortie.
$ echo -e "Linux est gratuit\n C'est un logiciel open source\nLinuxHint estun site de blog populaire" | awk '/^Linux/'
Production:
Recherche de chaîne en fin de ligne
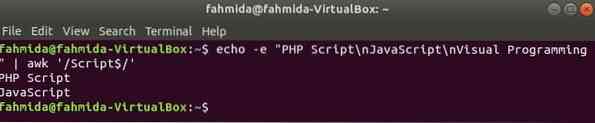
'$' le symbole est utilisé dans l'expression régulière pour rechercher n'importe quel motif à la fin de chaque ligne du texte. 'Scénario' mot est recherché dans l'exemple suivant. Ici, deux lignes contiennent le mot, Scénario au bout de la ligne.
$ echo -e "Script PHP\nJavaScript\nProgrammation visuelle" | awk '/Script$/'Production:
Recherche en omettant un jeu de caractères particulier
'^' le symbole indique le début du texte lorsqu'il est utilisé devant n'importe quel motif de chaîne ('/^… /') ou avant tout jeu de caractères déclaré par ^[… ]. Si la '^' symbole est utilisé à l'intérieur de la troisième parenthèse, [^… ] alors le jeu de caractères défini à l'intérieur de la parenthèse sera omis au moment de la recherche. La commande suivante recherchera tout mot qui ne commence pas par 'F' mais se terminant par 'ool'. Frais et bobo sera imprimé selon le modèle et les données de texte.
$ printf "Fou\nCool\nPoupée\nbool" | awk '/[^F]ool/'Production:

Aller au contenu
awk regex insensible à la casse
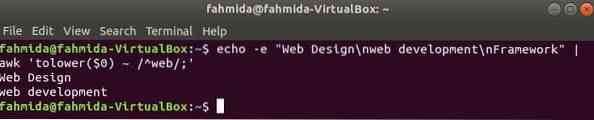
Par défaut, l'expression régulière effectue une recherche sensible à la casse lors de la recherche d'un modèle dans la chaîne. La recherche insensible à la casse peut être effectuée par la commande awk avec l'expression régulière. Dans l'exemple suivant, baisser() la fonction est utilisée pour faire une recherche insensible à la casse. Ici, le premier mot de chaque ligne du texte saisi sera converti en minuscule en utilisant baisser() fonction et correspondance avec le modèle d'expression régulière. topper() fonction peut également être utilisée à cet effet, dans ce cas, le motif doit être défini par toutes les lettres majuscules. Le texte défini dans l'exemple suivant contient le mot recherché, 'la toile' en deux lignes qui sera imprimé en sortie.
$ echo -e "Conception Web\nDéveloppement Web\nFramework" | awk 'tolow($0) ~ /^web/;'Production:
Aller au contenu
awk avec variable NF (nombre de champs)
NF est une variable intégrée de la commande awk qui est utilisée pour compter le nombre total de champs dans chaque ligne du texte d'entrée. Créez n'importe quel fichier texte avec plusieurs lignes et plusieurs mots. l'entrée.SMS est utilisé ici qui est créé dans l'exemple précédent.
Utilisation de NF à partir de la ligne de commande
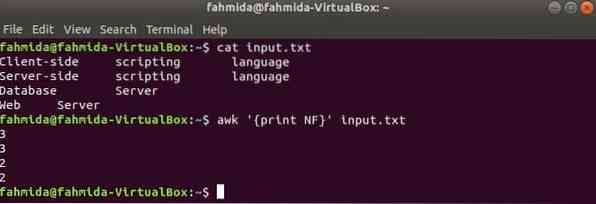
Ici, la première commande permet d'afficher le contenu de contribution.SMS fichier et la deuxième commande est utilisée pour afficher le nombre total de champs dans chaque ligne du fichier en utilisant NF variable.
$ entrée de chat.SMS$ awk 'print NF' entrée.SMS
Production:
Utilisation de NF dans le fichier awk
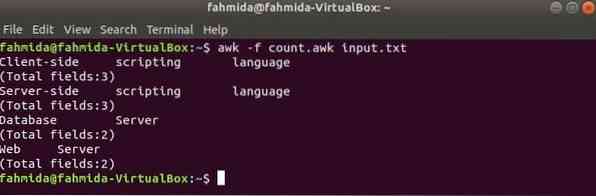
Créer un fichier awk nommé compter.ok avec le script ci-dessous. Lorsque ce script s'exécutera avec des données de texte, chaque contenu de ligne avec le nombre total de champs sera imprimé en sortie.
compter.ok
imprimer $0imprimer "[Total des champs :" NF "]"
Exécutez le script par la commande suivante.
$ awk -f compte.entrée maladroite.SMSProduction:
Aller au contenu
fonction awk gensub()
getsub() est une fonction de substitution utilisée pour rechercher une chaîne en fonction d'un délimiteur particulier ou d'un modèle d'expression régulière. Cette fonction est définie dans 'rester bouche bée' paquet qui n'est pas installé par défaut. La syntaxe de cette fonction est donnée ci-dessous. Le premier paramètre contient le modèle d'expression régulière ou le délimiteur de recherche, le deuxième paramètre contient le texte de remplacement, le troisième paramètre indique comment la recherche sera effectuée et le dernier paramètre contient le texte dans lequel cette fonction sera appliquée.
Syntaxe:
gensub(regexp, replacement, how [, target])Exécutez la commande suivante pour installer rester bouche bée paquet pour l'utilisation getsub() fonction avec la commande awk.
$ sudo apt-get install gawkCréez un fichier texte nommé 'informations de vente.SMS' avec le contenu suivant pour mettre en pratique cet exemple. Ici, les champs sont séparés par un onglet.
informations de vente.SMS
Lun 700000Mar 800000
Mer 750000
jeu 200 000
ven 430000
Sam 820000
Exécutez la commande suivante pour lire les champs numériques du informations de vente.SMS fichier et imprimer le total de tous les montants des ventes. Ici, le troisième paramètre, 'G' indique la recherche globale. Cela signifie que le modèle sera recherché dans tout le contenu du fichier.
$ awk ' x=gensub("\t","","G",$2) ; printf x "+" END print 0 ' salesinfo.txt | bc -lProduction:

Aller au contenu
awk avec la fonction rand()
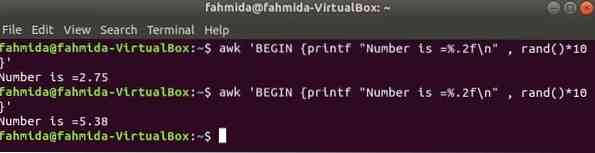
rand() La fonction est utilisée pour générer tout nombre aléatoire supérieur à 0 et inférieur à 1. Ainsi, il générera toujours un nombre fractionnaire inférieur à 1. La commande suivante générera un nombre aléatoire fractionnaire et multipliera la valeur par 10 pour obtenir un nombre supérieur à 1. Un nombre fractionnaire avec deux chiffres après la virgule sera imprimé pour appliquer la fonction printf(). Si vous exécutez la commande suivante plusieurs fois, vous obtiendrez une sortie différente à chaque fois.
$ awk 'BEGIN printf "Le nombre est =%.2f\n" , rand()*10'Production:
Aller au contenu
fonction définie par l'utilisateur awk
Toutes les fonctions utilisées dans les exemples précédents sont des fonctions intégrées. Mais vous pouvez déclarer une fonction définie par l'utilisateur dans votre script awk pour effectuer une tâche particulière. Supposons que vous souhaitiez créer une fonction personnalisée pour calculer l'aire d'un rectangle. Pour effectuer cette tâche, créez un fichier nommé 'surface.ok' avec le script suivant. Dans cet exemple, une fonction définie par l'utilisateur nommée surface() est déclaré dans le script qui calcule la zone en fonction des paramètres d'entrée et renvoie la valeur de la zone. obtenir la ligne la commande est utilisée ici pour prendre l'entrée de l'utilisateur.
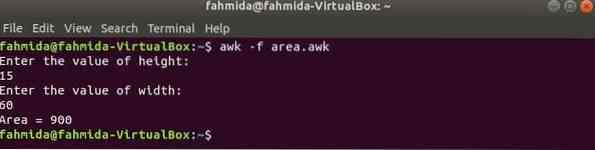
surface.ok
# Calculer la superficiezone de fonction (hauteur, largeur)
hauteur de retour*largeur
# Commence l'exécution
COMMENCER
print "Entrez la valeur de la hauteur :"
obtenir la ligne h < "-"
print "Entrez la valeur de la largeur :"
getline w < "-"
print "Area = " area(h,w)
Exécutez le script.
$ awk -f zone.okProduction:
Aller au contenu
awk si exemple
awk prend en charge les instructions conditionnelles comme les autres langages de programmation standard. Trois types d'instructions if sont présentés dans cette section à l'aide de trois exemples. Créer un fichier texte nommé éléments.SMS avec le contenu suivant.
éléments.SMS
Disque dur Samsung 100 $Souris A4Tech
Imprimante HP 200 $
Simple si exemple:
La commande suivante lira le contenu du éléments.SMS fichier et vérifiez le 3rd valeur du champ dans chaque ligne. Si la valeur est vide, il imprimera un message d'erreur avec le numéro de ligne.
$ awk ' if ($3 == "") print "Le champ de prix est manquant dans la ligne " NR ' articles.SMSProduction:
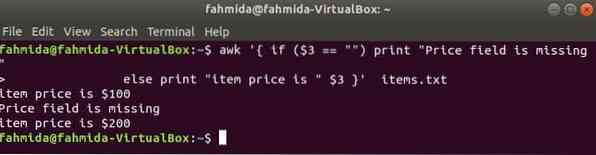
exemple if-else :
La commande suivante imprimera le prix de l'article si le 3rd existe dans la ligne, sinon, il imprimera un message d'erreur.
$ awk ' if ($3 == "") print "Le champ de prix est manquant"else print "le prix de l'article est de " 3 $ articles.SMS
Production:
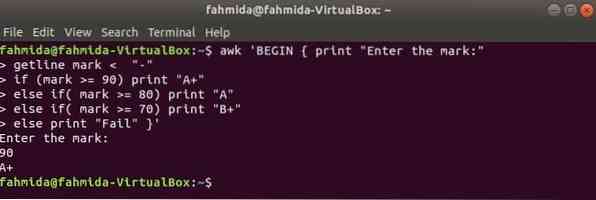
exemple if-else-if :
Lorsque la commande suivante s'exécutera à partir du terminal, elle prendra l'entrée de l'utilisateur. La valeur d'entrée sera comparée à chaque condition if jusqu'à ce que la condition soit vraie. Si une condition devient vraie, il imprimera la note correspondante. Si la valeur d'entrée ne correspond à aucune condition, l'impression échouera.
$ awk 'BEGIN print "Entrez la marque :"marque getline < "-"
si (marque >= 90) imprimez "A+"
else if( mark >= 80) print "A"
else if( mark >= 70) print "B+"
else imprimer "Échec" '
Production:
Aller au contenu
variables awk
La déclaration de la variable awk est similaire à la déclaration de la variable shell. Il y a une différence dans la lecture de la valeur de la variable. Le symbole '$' est utilisé avec le nom de la variable pour la variable shell pour lire la valeur. Mais il n'est pas nécessaire d'utiliser '$' avec la variable awk pour lire la valeur.
En utilisant une variable simple :
La commande suivante déclarera une variable nommée 'placer' et une valeur de chaîne est attribuée à cette variable. La valeur de la variable est imprimée dans l'instruction suivante.
$ awk 'BEGIN site="LinuxHint.com" ; imprimer le site'Production:

Utiliser une variable pour récupérer les données d'un fichier
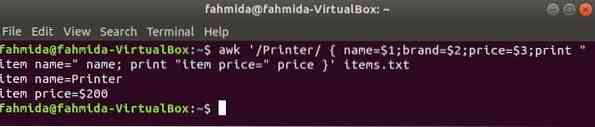
La commande suivante recherchera le mot 'Imprimante' dans le fichier éléments.SMS. Si une ligne du fichier commence par 'Imprimante' alors il stockera la valeur de 1st, 2sd et 3rd champs en trois variables. Nom et le prix les variables seront imprimées.
$ awk '/Printer/ name=$1;brand=$2;price=$3;print "item name=" name;imprimer "prix article=" prix ' articles.SMS
Production:
Aller au contenu
tableaux awk
Les tableaux numériques et associés peuvent être utilisés dans awk. La déclaration de variable de tableau dans awk est la même que dans d'autres langages de programmation. Certaines utilisations des tableaux sont présentées dans cette section.
Tableau associatif :
L'index du tableau sera n'importe quelle chaîne pour le tableau associatif. Dans cet exemple, un tableau associatif de trois éléments est déclaré et imprimé.
$ awk 'BEGINlivres["Web Design"] = "Apprendre HTML 5";
livres["Programmation Web"] = "PHP et MySQL"
livres["PHP Framework"]="Apprentissage de Laravel 5"
printf "%s\n%s\n%s\n", livres["Conception Web"],livres["Programmation Web"],
livres["PHP Framework"] '
Production:
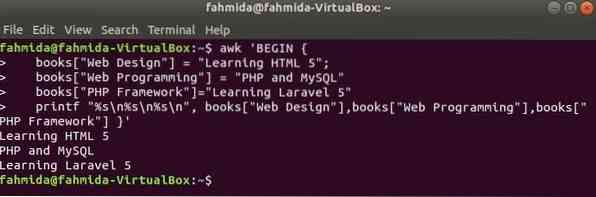
Tableau numérique :
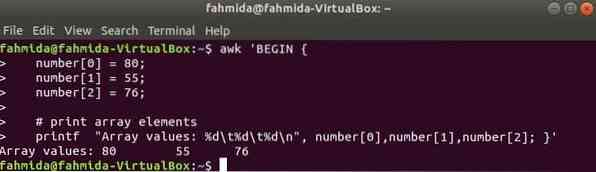
Un tableau numérique de trois éléments est déclaré et imprimé en séparant la tabulation.
$ awk 'BEGINnombre[0] = 80 ;
nombre[1] = 55 ;
nombre[2] = 76 ;
# affiche les éléments du tableau
printf " Valeurs du tableau : %d\t%d\t%d\n", nombre[0],nombre[1],nombre[2] ; '
Production:
Aller au contenu
boucle awk
Trois types de boucles sont pris en charge par awk. Les utilisations de ces boucles sont montrées ici à l'aide de trois exemples.
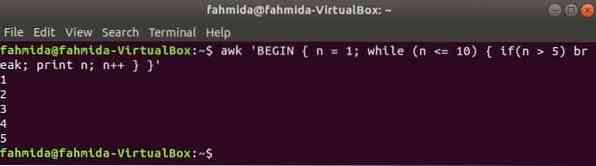
Boucle while :
La boucle while utilisée dans la commande suivante sera itérée 5 fois et quittera la boucle pour l'instruction break.
$ awk 'BEGIN n = 1 ; tandis que (n <= 10) if(n > 5) pause ; imprimer n; n++ 'Production:
Boucle for :
La boucle for utilisée dans la commande awk suivante calculera la somme de 1 à 10 et imprimera la valeur.
$ awk 'BEGIN somme=0; pour (n = 1; n <= 10; n++) sum=sum+n; print sum 'Production:

Boucle Do-while :
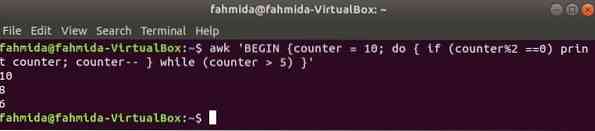
une boucle do-while de la commande suivante imprimera tous les nombres pairs de 10 à 5.
$ awk 'BEGIN compteur = 10; do if (counter%2 ==0) imprime le compteur ; compteur--tandis que (compteur > 5) '
Production:
Aller au contenu
awk pour imprimer la première colonne
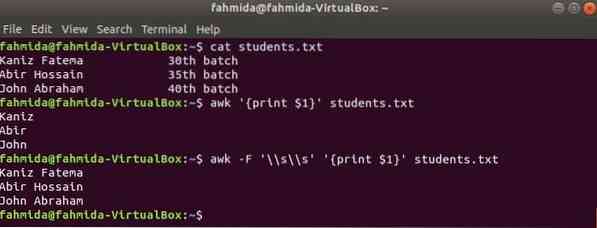
La première colonne de n'importe quel fichier peut être imprimée en utilisant la variable $1 dans awk. Mais si la valeur de la première colonne contient plusieurs mots, alors seul le premier mot de la première colonne s'imprime. En utilisant un délimiteur spécifique, la première colonne peut être imprimée correctement. Créer un fichier texte nommé étudiants.SMS avec le contenu suivant. Ici, la première colonne contient le texte de deux mots.
Étudiants.SMS
Kaniz Fatema 30e grouperAbir Hossain 35e grouper
Jean Abraham 40e grouper
Exécuter la commande awk sans aucun délimiteur. La première partie de la première colonne sera imprimée.
$ awk 'print $1' étudiants.SMSExécutez la commande awk avec le délimiteur suivant. La partie entière de la première colonne sera imprimée.
$ awk -F '\\s\\s' 'print $1' étudiants.SMSProduction:
Aller au contenu
awk pour imprimer la dernière colonne
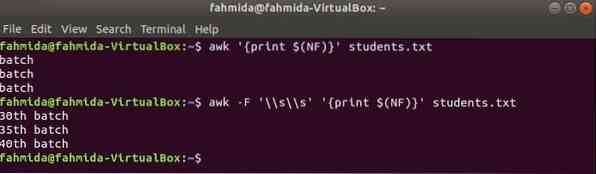
$(NF) la variable peut être utilisée pour imprimer la dernière colonne de n'importe quel fichier. Les commandes awk suivantes imprimeront la dernière partie et la partie complète de la dernière colonne de les étudiants.SMS déposer.
$ awk 'print $(NF)' étudiants.SMS$ awk -F '\\s\\s' 'print $(NF)' étudiants.SMS
Production:
Aller au contenu
awk avec grep
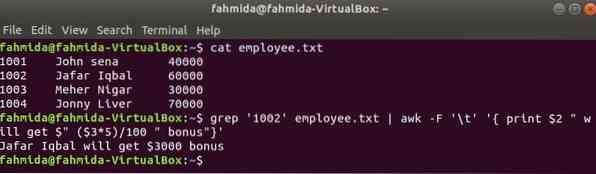
grep est une autre commande utile de Linux pour rechercher du contenu dans un fichier basé sur n'importe quelle expression régulière. L'exemple suivant montre comment les commandes awk et grep peuvent être utilisées ensemble. grep La commande est utilisée pour rechercher des informations sur l'identifiant de l'employé, '1002' de l'employé.SMS déposer. La sortie de la commande grep sera envoyée à awk en tant que données d'entrée. 5% de bonus seront comptés et imprimés en fonction du salaire de l'identifiant de l'employé, '1002' par commande awk.
$ chat employé.SMS$ grep '1002' employé.txt | awk -F '\t' ' print $2 " obtiendra $" (3*5)/100 " bonus"'
Production:
Aller au contenu
awk avec le fichier BASH
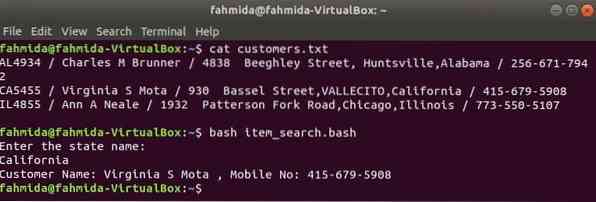
Comme les autres commandes Linux, la commande awk peut également être utilisée dans un script BASH. Créer un fichier texte nommé les clients.SMS avec le contenu suivant. Chaque ligne de ce fichier contient des informations sur quatre champs. Il s'agit de l'identifiant, du nom, de l'adresse et du numéro de téléphone du client, séparés par '/'.
les clients.SMS
AL4934 / Charles M Brunner / 4838 rue Beeghley, Huntsville, Alabama / 256-671-7942CA5455 / Virginia S Mota / 930 Bassel Street, VALLECITO, Californie / 415-679-5908
IL4855 / Ann A Neale / 1932 Patterson Fork Road, Chicago, Illinois / 773-550-5107
Créez un fichier bash nommé item_search.frapper avec le script suivant. Selon ce script, la valeur d'état sera extraite de l'utilisateur et recherchée dans les clients.SMS déposer par grep commande et passée à la commande awk en entrée. La commande Awk lira 2sd et 4e champs de chaque ligne. Si la valeur d'entrée correspond à une valeur d'état de les clients.SMS fichier puis il imprimera le client Nom et numéro de portable, sinon, il imprimera le message "Aucun client trouvé".
item_search.frapper
#!/bin/bashecho "Entrez le nom de l'état :"
état de lecture
clients='grep "$state" clients.txt | awk -F "/" 'print "Nom du client :" $2, ",
N° de mobile : " 4 $ ''
si [ "$clients" != "" ]; ensuite
echo $clients
autre
echo "Aucun client trouvé"
Fi
Exécutez les commandes suivantes pour afficher les sorties.
$ clients chats.SMS$ bash item_search.frapper
Production:
Aller au contenu
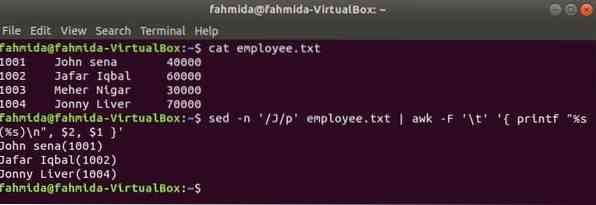
awk avec sed
Un autre outil de recherche utile de Linux est sed. Cette commande peut être utilisée à la fois pour rechercher et remplacer le texte de n'importe quel fichier. L'exemple suivant montre l'utilisation de la commande awk avec sed commander. Ici, la commande sed recherchera tous les noms d'employés commençant par 'J' et passe à la commande awk en entrée. awk imprimera l'employé Nom et identifiant après formatage.
$ chat employé.SMS$ sed -n '/J/p' employé.txt | awk -F '\t' ' printf "%s(%s)\n", $2, $1 '
Production:
Aller au contenu
Conclusion:
Vous pouvez utiliser la commande awk pour créer différents types de rapports basés sur des données tabulaires ou délimitées après avoir correctement filtré les données. J'espère que vous pourrez apprendre comment fonctionne la commande awk après avoir pratiqué les exemples présentés dans ce didacticiel.


