Apache Kafka
Pour une définition de haut niveau, présentons une courte définition d'Apache Kafka :
Apache Kafka est un journal de validation distribué, tolérant aux pannes et évolutif horizontalement.
C'étaient des mots de haut niveau sur Apache Kafka. Laissez-nous comprendre les concepts en détail ici.
- Distribué: Kafka divise les données qu'il contient en plusieurs serveurs et chacun de ces serveurs est capable de traiter les demandes des clients pour le partage des données qu'il contient
- Tolérance de panne: Kafka n'a pas de point de défaillance unique. Dans un système SPoF, comme une base de données MySQL, si le serveur hébergeant la base de données tombe en panne, l'application est foutue. Dans un système qui n'a pas de SPoF et qui se compose de plusieurs nœuds, même si la majeure partie du système tombe en panne, il en est toujours de même pour un utilisateur final.
- Évolutif horizontal: ce type de scaling fait référence à l'ajout de plus de machines au cluster existant. Cela signifie qu'Apache Kafka est capable d'accepter plus de nœuds dans son cluster et de ne fournir aucun temps d'arrêt pour les mises à niveau requises du système. Regardez l'image ci-dessous pour comprendre le type de concepts d'échelle :
- Journal de validation: Un journal de commit est une structure de données tout comme une liste chaînée. Il ajoute tous les messages qui lui parviennent et maintient toujours leur ordre. Les données ne peuvent pas être supprimées de ce journal tant qu'un délai spécifié n'est pas atteint pour ces données.
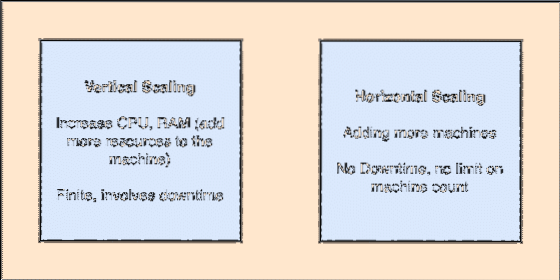
Échellement vertical et horizontal
Un sujet dans Apache Kafka est comme une file d'attente où les messages sont stockés. Ces messages sont stockés pendant une durée configurable et le message n'est pas supprimé tant que cette durée n'est pas atteinte, même s'il a été consommé par tous les consommateurs connus.
Kafka est évolutif car ce sont les consommateurs qui stockent réellement le dernier message récupéré par eux en tant que valeur « offset ». Regardons un chiffre pour mieux comprendre cela :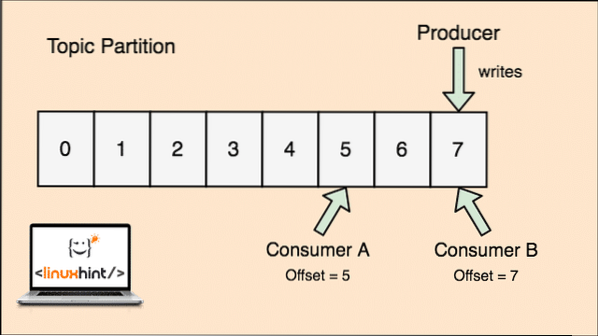
Partition de sujet et décalage de consommateur dans Apache Kafka
Premiers pas avec Apache Kafka
Pour commencer à utiliser Apache Kafka, il doit être installé sur la machine. Pour ce faire, lisez Installer Apache Kafka sur Ubuntu.
Assurez-vous d'avoir une installation Kafka active si vous voulez essayer des exemples que nous présenterons plus tard dans la leçon.
Comment ça marche?
Avec Kafka, le Producteur applications publier messages qui arrive à un Kafka Nœud et non directement à un consommateur. A partir de ce nœud Kafka, les messages sont consommés par le Consommateur applications.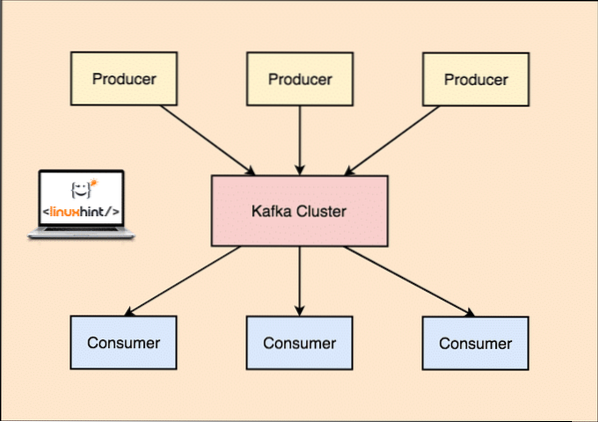
Producteur et consommateur de Kafka
Comme un seul sujet peut obtenir beaucoup de données en une seule fois, pour que Kafka reste évolutif horizontalement, chaque sujet est divisé en partitions et chaque partition peut vivre sur n'importe quelle machine de nœud d'un cluster. Essayons de le présenter :
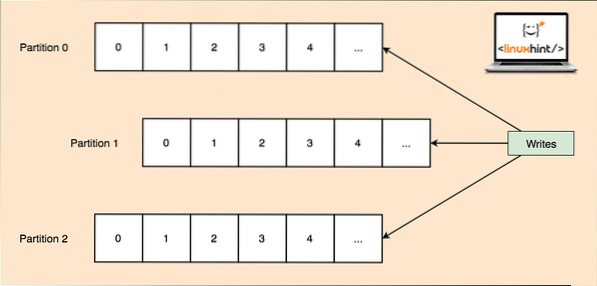
Partitions thématiques
Encore une fois, Kafka Broker n'enregistre pas quel consommateur a consommé combien de paquets de données. C'est le la responsabilité des consommateurs de garder une trace des données qu'il a consommées.
Persistance sur le disque
Kafka conserve les enregistrements de messages qu'il reçoit des producteurs sur le disque et ne les garde pas en mémoire. Une question qui pourrait se poser est de savoir comment cela rend les choses réalisables et rapides? Il y avait plusieurs raisons derrière cela, ce qui en fait un moyen optimal de gérer les enregistrements de messages :
- Kafka suit un protocole de regroupement des enregistrements de messages. Les producteurs produisent des messages qui sont conservés sur le disque en gros morceaux et les consommateurs consomment également ces enregistrements de messages en gros morceaux linéaires.
- La raison pour laquelle les écritures sur disque sont linéaires est que cela rend les lectures rapides en raison du temps de lecture linéaire du disque fortement réduit.
- Les opérations de disque linéaire sont optimisées par Systèmes d'exploitation ainsi qu'en utilisant des techniques de écriture-derrière et lecture anticipée.
- Les systèmes d'exploitation modernes utilisent également le concept de Mise en cache des pages ce qui signifie qu'ils mettent en cache certaines données du disque dans la RAM libre disponible.
- Comme Kafka conserve les données dans des données standard uniformes dans l'ensemble du flux du producteur au consommateur, il utilise le optimisation sans copie traiter.
Distribution et réplication des données
Comme nous avons étudié ci-dessus qu'un sujet est divisé en partitions, chaque enregistrement de message est répliqué sur plusieurs nœuds du cluster pour maintenir l'ordre et les données de chaque enregistrement au cas où l'un des nœuds meurt.
Même si une partition est répliquée sur plusieurs nœuds, il existe toujours un chef de partition nœud à travers lequel les applications lisent et écrivent des données sur le sujet et le leader réplique les données sur d'autres nœuds, appelés suiveurs de cette partition.
Si les données d'enregistrement de message sont très importantes pour une application, la garantie que l'enregistrement de message est sûr dans l'un des nœuds peut être augmentée en augmentant le facteur de réplication du cluster.
Qu'est-ce que Zookeeper?
Zookeeper est un magasin de clé-valeur distribué hautement tolérant aux pannes. Apache Kafka dépend fortement de Zookeeper pour stocker les mécanismes de cluster comme le rythme cardiaque, la distribution des mises à jour/configurations, etc.).
Il permet aux courtiers Kafka de s'abonner à lui-même et de savoir chaque fois qu'un changement concernant un chef de partition et la distribution des nœuds s'est produit.
Les applications Producteurs et Consommateurs communiquent directement avec Zookeeper application pour savoir quel nœud est le chef de partition pour un sujet afin qu'ils puissent effectuer des lectures et des écritures à partir du chef de partition.
Diffusion
Un processeur de flux est un composant principal d'un cluster Kafka qui prend un flux continu de données d'enregistrement de message à partir de sujets d'entrée, traite ces données et crée un flux de données pour des sujets de sortie qui peuvent être n'importe quoi, de la corbeille à une base de données.
Il est tout à fait possible d'effectuer un traitement simple directement à l'aide des API producteur/consommateur, bien que pour un traitement complexe comme la combinaison de flux, Kafka fournit une bibliothèque d'API Streams intégrée, mais veuillez noter que cette API est destinée à être utilisée dans notre propre base de code et qu'elle ne t fonctionner sur un courtier. Il fonctionne de manière similaire à l'API grand public et nous aide à étendre le travail de traitement de flux sur plusieurs applications.
Quand utiliser Apache Kafka?
Comme nous l'avons étudié dans les sections ci-dessus, Apache Kafka peut être utilisé pour traiter un grand nombre d'enregistrements de messages pouvant appartenir à un nombre pratiquement infini de sujets dans nos systèmes.
Apache Kafka est un candidat idéal lorsqu'il s'agit d'utiliser un service qui peut nous permettre de suivre une architecture événementielle dans nos applications. Cela est dû à ses capacités de persistance des données, à son architecture tolérante aux pannes et hautement distribuée où les applications critiques peuvent compter sur ses performances.
L'architecture évolutive et distribuée de Kafka rend l'intégration avec les microservices très facile et permet à une application de se découpler avec beaucoup de logique métier.
Créer un nouveau sujet
Nous pouvons créer un sujet de test essai sur le serveur Apache Kafka avec la commande suivante :
Créer un sujet
sudo kafka-sujets.sh --create --zookeeper localhost:2181 --replication-factor 1--partitions 1 --topic testing
Voici ce que nous obtenons avec cette commande :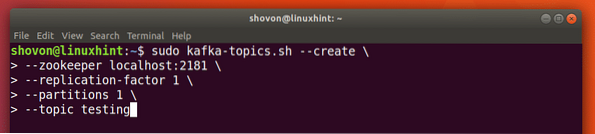
Créer un nouveau sujet Kafka
Un sujet de test sera créé que nous pouvons confirmer avec la commande mentionnée :
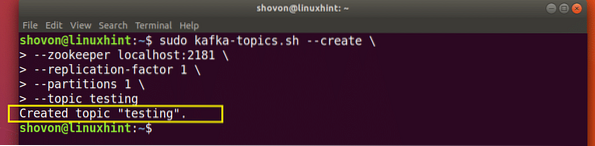
Confirmation de création du sujet Kafka
Écrire des messages sur un sujet
Comme nous l'avons étudié précédemment, l'une des API présentes dans Apache Kafka est la API de producteur. Nous utiliserons cette API pour créer un nouveau message et le publier dans le sujet que nous venons de créer :
Écrire un message au sujet
sudo kafka-console-producteur.sh --broker-list localhost:9092 --topic testingVoyons le résultat de cette commande :
Publier un message sur Kafka Sujet
Une fois que nous avons appuyé sur la touche, nous verrons une nouvelle flèche (>) qui signifie que nous pouvons maintenant entrer des données :

Saisie d'un message
Tapez simplement quelque chose et appuyez sur pour commencer une nouvelle ligne. J'ai tapé 3 lignes de textes :
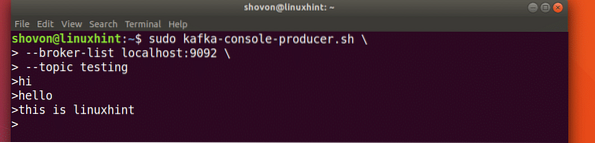
Lire les messages du sujet
Maintenant que nous avons publié un message sur le sujet Kafka que nous avons créé, ce message sera là pendant un certain temps configurable. Nous pouvons le lire maintenant en utilisant le API grand public:
Lire les messages du sujet
sudo kafka-console-consommateur.sh --zookeeper localhost:2181 --test de sujet --from-beginning
Voici ce que nous obtenons avec cette commande :
Commande pour lire le message du sujet Kafka
Nous pourrons voir les messages ou les lignes que nous avons écrits à l'aide de l'API Producer comme indiqué ci-dessous :
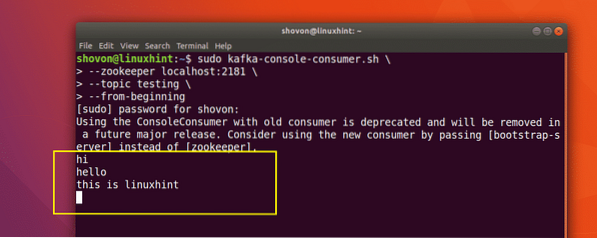
Si nous écrivons un autre nouveau message à l'aide de l'API Producer, il sera également affiché instantanément du côté Consumer :
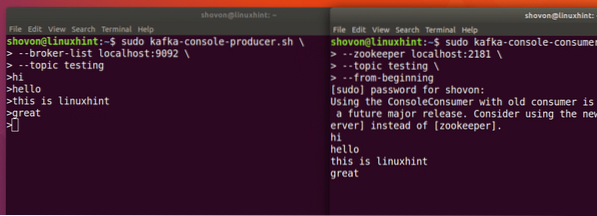
Publier et consommer en même temps
Conclusion
Dans cette leçon, nous avons vu comment nous commençons à utiliser Apache Kafka, qui est un excellent courtier de messages et peut également servir d'unité spéciale de persistance des données.


