
Quand j'ai commencé à travailler avec des problèmes d'apprentissage automatique, j'ai alors paniqué quel algorithme devrais-je utiliser? Ou lequel est facile à appliquer? Si vous êtes comme moi, cet article pourrait vous aider à connaître les algorithmes, méthodes ou techniques d'intelligence artificielle et d'apprentissage automatique pour résoudre tout problème inattendu ou même attendu.
L'apprentissage automatique est une technique d'IA si puissante qui peut effectuer une tâche efficacement sans utiliser d'instructions explicites. Un modèle de ML peut apprendre de ses données et de son expérience. Les applications d'apprentissage automatique sont automatiques, robustes et dynamiques. Plusieurs algorithmes sont développés pour répondre à cette nature dynamique des problèmes de la vie réelle. En gros, il existe trois types d'algorithmes d'apprentissage automatique tels que l'apprentissage supervisé, l'apprentissage non supervisé et l'apprentissage par renforcement.
Meilleurs algorithmes d'IA et d'apprentissage automatique
La sélection de la technique ou de la méthode d'apprentissage automatique appropriée est l'une des tâches principales pour développer un projet d'intelligence artificielle ou d'apprentissage automatique. Parce qu'il existe plusieurs algorithmes disponibles, et tous ont leurs avantages et leur utilité. Ci-dessous, nous racontons 20 algorithmes d'apprentissage automatique pour les débutants et les professionnels. Alors, jetons un coup d'oeil.
1. Naïf Bayes
Un classificateur naïf de Bayes est un classificateur probabiliste basé sur le théorème de Bayes, avec l'hypothèse d'indépendance entre les caractéristiques. Ces fonctionnalités diffèrent d'une application à l'autre. C'est l'une des méthodes d'apprentissage automatique confortables pour les débutants à pratiquer.
Naïve Bayes est un modèle de probabilité conditionnelle. Étant donné une instance de problème à classer, représentée par un vecteur X = (Xje … Xm) représentant quelques n caractéristiques (variables indépendantes), il attribue à l'instance actuelle des probabilités pour chacun des K résultats potentiels :
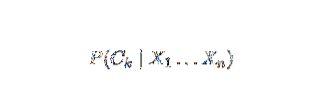 Le problème avec la formulation ci-dessus est que si le nombre de caractéristiques n est significatif ou si un élément peut prendre un grand nombre de valeurs, alors baser un tel modèle sur des tables de probabilité est infaisable. Nous réaménageons donc le modèle pour le rendre plus maniable. En utilisant le théorème de Bayes, la probabilité conditionnelle peut être écrite comme,
Le problème avec la formulation ci-dessus est que si le nombre de caractéristiques n est significatif ou si un élément peut prendre un grand nombre de valeurs, alors baser un tel modèle sur des tables de probabilité est infaisable. Nous réaménageons donc le modèle pour le rendre plus maniable. En utilisant le théorème de Bayes, la probabilité conditionnelle peut être écrite comme,
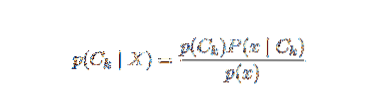
En utilisant la terminologie de probabilité bayésienne, l'équation ci-dessus peut être écrite comme :
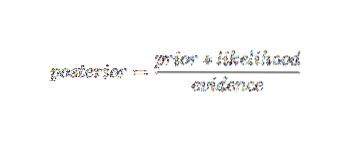
Cet algorithme d'intelligence artificielle est utilisé dans la classification de texte, je.e., analyse des sentiments, catégorisation des documents, filtrage des spams et classification des actualités. Cette technique d'apprentissage automatique fonctionne bien si les données d'entrée sont classées en groupes prédéfinis. De plus, elle nécessite moins de données que la régression logistique. Il surpasse dans divers domaines.
2. Machine à vecteur de soutien
Support Vector Machine (SVM) est l'un des algorithmes d'apprentissage automatique supervisé les plus utilisés dans le domaine de la classification de texte. Cette méthode est également utilisée pour la régression. Il peut également être appelé réseaux de vecteurs de support. Cortes & Vapnik ont développé cette méthode pour la classification binaire. Le modèle d'apprentissage supervisé est l'approche d'apprentissage automatique qui déduit la sortie des données d'entraînement étiquetées.
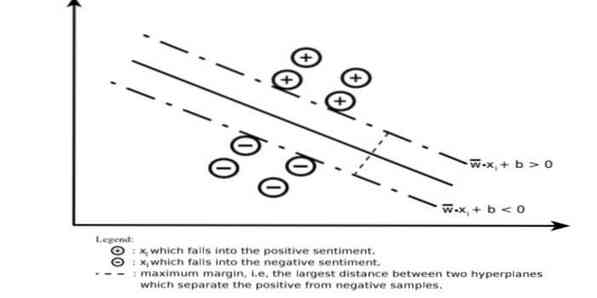
Une machine à vecteurs de support construit un hyperplan ou un ensemble d'hyperplans dans une zone de dimension très élevée ou infinie. Il calcule la surface de séparation linéaire avec une marge maximale pour un ensemble d'apprentissage donné.
Seul un sous-ensemble des vecteurs d'entrée influencera le choix de la marge (entouré sur la figure) ; de tels vecteurs sont appelés vecteurs de support. Lorsqu'une surface de séparation linéaire n'existe pas, par exemple, en présence de données bruitées, les algorithmes SVM avec une variable slack sont appropriés. Ce classificateur tente de partitionner l'espace de données à l'aide de délimitations linéaires ou non linéaires entre les différentes classes.
SVM a été largement utilisé dans les problèmes de classification de modèles et de régression non linéaire. En outre, c'est l'une des meilleures techniques pour effectuer une catégorisation automatique de texte. La meilleure chose à propos de cet algorithme est qu'il ne fait aucune hypothèse forte sur les données.
Pour implémenter Support Vector Machine : bibliothèques de science des données en Python - SciKit Learn, PyML, SVMStructurer Bibliothèques Python, LIBSVM et science des données dans R-Klar, e1071.
3. Régression linéaire
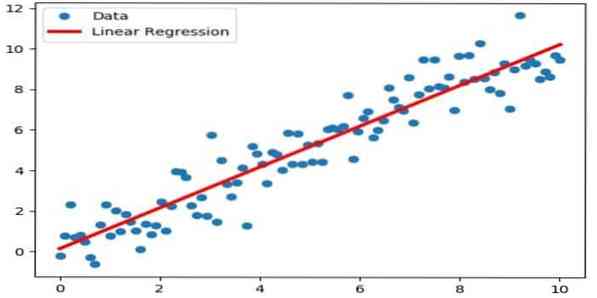
La régression linéaire est une approche directe utilisée pour modéliser la relation entre une variable dépendante et une ou plusieurs variables indépendantes. S'il y a une variable indépendante, on parle alors de régression linéaire simple. Si plus d'une variable indépendante est disponible, on parle alors de régression linéaire multiple.
Cette formule est utilisée pour estimer des valeurs réelles telles que le prix des maisons, le nombre d'appels, les ventes totales basées sur des variables continues. Ici, la relation entre les variables indépendantes et dépendantes est établie en ajustant la meilleure droite. Cette ligne de meilleur ajustement est connue sous le nom de ligne de régression et représentée par une équation linéaire
Y= un *X + b.
ici,
- Y - variable dépendante
- une pente
- X - variable indépendante
- b - intercepter
Cette méthode d'apprentissage automatique est facile à utiliser. Il s'exécute rapidement. Cela peut être utilisé dans les affaires pour la prévision des ventes. Il peut également être utilisé dans l'évaluation des risques.
4. Régression logistique
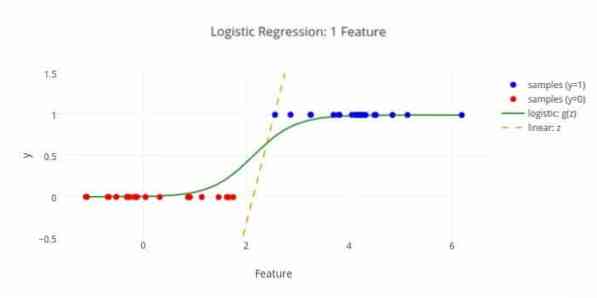
Voici un autre algorithme d'apprentissage automatique - Régression logistique ou régression logit qui est utilisée pour estimer des valeurs discrètes (valeurs binaires comme 0/1, oui/non, vrai/faux) sur la base d'un ensemble donné de la variable indépendante. La tâche de cet algorithme est de prédire la probabilité d'un incident en ajustant les données à une fonction logit. Ses valeurs de sortie sont comprises entre 0 et 1.
La formule peut être utilisée dans divers domaines tels que l'apprentissage automatique, la discipline scientifique et les domaines médicaux. Il peut être utilisé pour prédire le danger de survenue d'une maladie donnée en fonction des caractéristiques observées du patient. La régression logistique peut être utilisée pour prédire le désir d'un client d'acheter un produit. Cette technique d'apprentissage automatique est utilisée dans les prévisions météorologiques pour prédire la probabilité d'avoir de la pluie.
La régression logistique peut être divisée en trois types -
- Régression logistique binaire
- Régression logistique multi-nominale
- Régression logistique ordinale
La régression logistique est moins compliquée. De plus, il est robuste. Il peut gérer les effets non linéaires. Cependant, si les données d'entraînement sont rares et de grande dimension, cet algorithme ML peut surdimensionner. Il ne peut pas prédire les résultats continus.
5. K-Le plus proche-voisin (KNN)
K-nearest-neighbor (kNN) est une approche statistique bien connue pour la classification et a été largement étudiée au fil des ans, et s'est appliquée très tôt aux tâches de catégorisation. Il agit comme une méthodologie non paramétrique pour les problèmes de classification et de régression.
Cette méthode AI et ML est assez simple. Il détermine la catégorie d'un document de test t sur la base du vote d'un ensemble de k documents les plus proches de t en termes de distance, généralement distance euclidienne. La règle de décision essentielle étant donné un document de test t pour le classificateur kNN est :
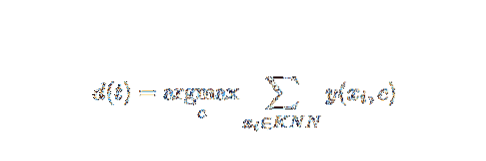
Où y (xi,c ) est une fonction de classification binaire pour le document d'apprentissage xi (qui renvoie la valeur 1 si xi est étiqueté avec c, ou 0 sinon), cette règle étiquette avec t avec la catégorie qui reçoit le plus de votes dans le k -quartier le plus proche.
Nous pouvons être mappés KNN à nos vies réelles. Par exemple, si vous souhaitez connaître quelques personnes dont vous n'avez aucune information, vous préférerez peut-être décider de ses proches et donc des cercles dans lesquels il évolue et accéder à ses informations. Cet algorithme est coûteux en calcul.
6. K-moyens
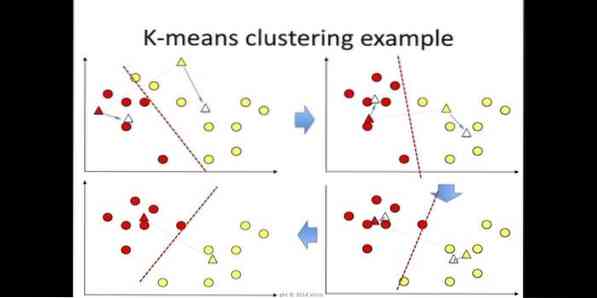
Le clustering k-means est une méthode d'apprentissage non supervisé accessible pour l'analyse de cluster dans l'exploration de données. Le but de cet algorithme est de diviser n observations en k clusters où chaque observation appartient à la moyenne la plus proche du cluster. Cet algorithme est utilisé dans la segmentation du marché, la vision par ordinateur et l'astronomie parmi de nombreux autres domaines.
7. Arbre de décision
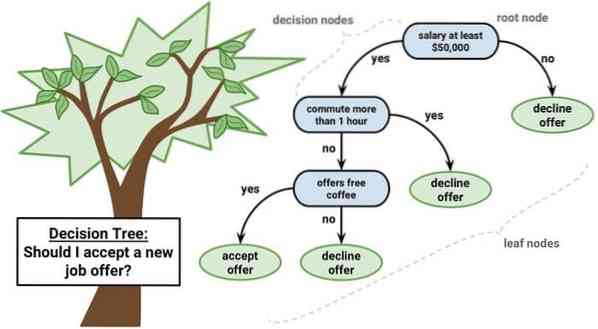
Un arbre de décision est un outil d'aide à la décision qui utilise une représentation graphique, je.e., graphique en forme d'arbre ou modèle de décisions. Il est couramment utilisé dans l'analyse décisionnelle et également un outil populaire dans l'apprentissage automatique. Les arbres de décision sont utilisés dans la recherche opérationnelle et la gestion des opérations.
Il a une structure de type organigramme dans laquelle chaque nœud interne représente un « test » sur un attribut, chaque branche représente le résultat du test et chaque nœud feuille représente une étiquette de classe. La route de la racine à la feuille est connue sous le nom de règles de classification. Il se compose de trois types de nœuds :
- Nœuds de décision : généralement représentés par des carrés,
- Noeuds de chance : généralement représentés par des cercles,
- Nœuds d'extrémité : généralement représentés par des triangles.
Un arbre de décision est simple à comprendre et à interpréter. Il utilise un modèle de boîte blanche. En outre, il peut se combiner avec d'autres techniques de décision.
8. Forêt aléatoire
La forêt aléatoire est une technique populaire d'apprentissage d'ensemble qui fonctionne en construisant une multitude d'arbres de décision au moment de l'apprentissage et en sortie la catégorie qui est le mode des catégories (classification) ou la prédiction moyenne (régression) de chaque arbre.
Le temps d'exécution de cet algorithme d'apprentissage automatique est rapide et il peut fonctionner avec les données déséquilibrées et manquantes. Cependant, lorsque nous l'avons utilisé pour la régression, il ne peut pas prédire au-delà de la plage des données d'entraînement, et il peut surajuster les données.
9. CHARIOT
L'arbre de classification et de régression (CART) est un type d'arbre de décision. Un arbre de décision fonctionne comme une approche de partitionnement récursif et CART divise chacun des nœuds d'entrée en deux nœuds enfants. À chaque niveau d'un arbre de décision, l'algorithme identifie une condition - quelle variable et quel niveau utiliser pour diviser le nœud d'entrée en deux nœuds enfants.
Les étapes de l'algorithme CART sont indiquées ci-dessous :
- Prendre des données d'entrée
- Meilleur fractionné
- Meilleure variable
- Divisez les données d'entrée en nœuds gauche et droit
- Continuez l'étape 2-4
- Élagage des arbres de décision
dix. Algorithme d'apprentissage automatique apriori

L'algorithme Apriori est un algorithme de catégorisation. Cette technique d'apprentissage automatique est utilisée pour trier de grandes quantités de données. Il peut également être utilisé pour suivre la façon dont les relations se développent et les catégories sont construites. Cet algorithme est une méthode d'apprentissage non supervisé qui génère des règles d'association à partir d'un ensemble de données donné.
L'algorithme d'apprentissage automatique Apriori fonctionne comme :
- Si un ensemble d'éléments se produit fréquemment, alors tous les sous-ensembles de l'ensemble d'éléments se produisent également souvent.
- Si un ensemble d'éléments se produit rarement, alors tous les sur-ensembles de l'ensemble d'éléments ont également une occurrence peu fréquente.
Cet algorithme ML est utilisé dans une variété d'applications telles que la détection des effets indésirables des médicaments, l'analyse du panier de marché et les applications de saisie semi-automatique. C'est simple à mettre en oeuvre.
11. Analyse en Composantes Principales (ACP)
L'analyse en composantes principales (ACP) est un algorithme non supervisé. Les nouvelles caractéristiques sont orthogonales, c'est-à-dire qu'elles ne sont pas corrélées. Avant d'effectuer l'ACP, vous devez toujours normaliser votre ensemble de données car la transformation dépend de l'échelle. Si vous ne le faites pas, les caractéristiques qui sont à l'échelle la plus significative domineront les nouveaux composants principaux.
L'ACP est une technique polyvalente. Cet algorithme est sans effort et simple à mettre en œuvre. Il peut être utilisé dans le traitement d'images.
12. ChatBoost
CatBoost est un algorithme d'apprentissage automatique open source qui vient de Yandex. Le nom 'CatBoost' vient de deux mots 'Catégorie' et 'Boosting.' Il peut se combiner avec des cadres d'apprentissage en profondeur, je.e., TensorFlow de Google et Core ML d'Apple. CatBoost peut fonctionner avec de nombreux types de données pour résoudre plusieurs problèmes.
13. Dichotomiseur itératif 3 (ID3)
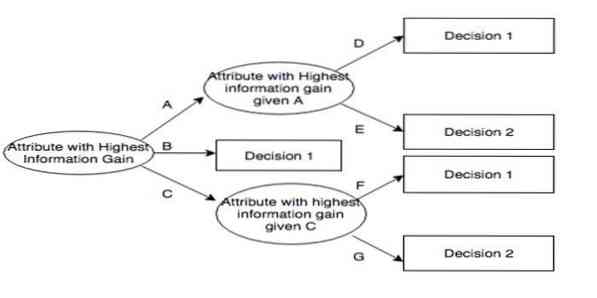
Iterative Dichotomiser 3 (ID3) est une règle algorithmique d'apprentissage d'arbre de décision présentée par Ross Quinlan qui est utilisée pour fournir un arbre de décision à partir d'un ensemble de données. C'est le précurseur de la C4.5 programme algorithmique et est utilisé dans les domaines de processus d'apprentissage automatique et de communication linguistique.
ID3 peut suradapter aux données d'entraînement. Cette règle algorithmique est plus difficile à utiliser sur des données continues. Il ne garantit pas une solution optimale.
14. Classification hiérarchique
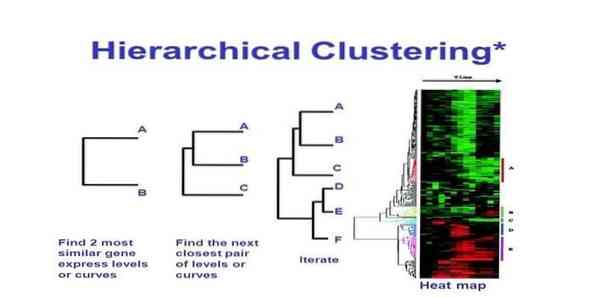
Le clustering hiérarchique est un moyen d'analyse de cluster. Dans le clustering hiérarchique, un arbre de cluster (un dendrogramme) est développé pour illustrer les données. Dans le clustering hiérarchique, chaque groupe (nœud) est lié à deux ou plusieurs groupes successeurs. Chaque nœud de l'arborescence du cluster contient des données similaires. Groupe de nœuds sur le graphique à côté d'autres nœuds similaires.
Algorithme
Cette méthode d'apprentissage automatique peut être divisée en deux modèles - de bas en haut ou alors de haut en bas:
De bas en haut (regroupement aggloméré hiérarchique, HAC)
- Au début de cette technique d'apprentissage automatique, prenez chaque document comme un seul cluster.
- Dans un nouveau cluster, fusion de deux éléments à la fois. Comment la fusion des combinaisons implique le calcul d'une différence entre chaque paire incorporée et donc les échantillons alternatifs. Il y a beaucoup d'options pour le faire. Certains d'entre eux sont:
une. Attelage complet: Similarité de la paire la plus éloignée. Une limitation est que les valeurs aberrantes peuvent provoquer la fusion de groupes proches plus tard que ce qui est optimal.
b. Attelage simple: La similitude de la paire la plus proche. Cela peut provoquer une fusion prématurée, bien que ces groupes soient assez différents.
c. Moyenne du groupe: similitude entre les groupes.
ré. Similitude centroïde : chaque itération fusionne les clusters avec le point central le plus similaire.
- Jusqu'à ce que tous les éléments fusionnent en un seul cluster, le processus d'appariement se poursuit.
De haut en bas (clusive de division)
- Les données commencent par un cluster combiné.
- Le cluster se divise en deux parties distinctes, selon un certain degré de similitude.
- Les clusters se divisent en deux encore et encore jusqu'à ce que les clusters ne contiennent qu'un seul point de données.
15. Rétro-propagation
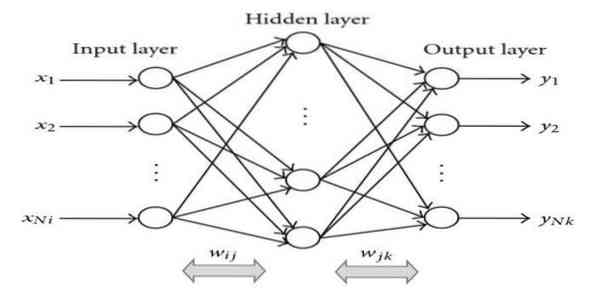
La rétro-propagation est un algorithme d'apprentissage supervisé. Cet algorithme de ML vient du domaine de ANN (Artificial Neural Networks). Ce réseau est un réseau feed-forward multicouche. Cette technique vise à concevoir une fonction donnée en modifiant les poids internes des signaux d'entrée pour produire le signal de sortie souhaité. Il peut être utilisé pour la classification et la régression.

L'algorithme de rétro-propagation présente certains avantages, je.e., c'est facile à mettre en oeuvre. La formule mathématique utilisée dans l'algorithme peut être appliquée à n'importe quel réseau. Le temps de calcul peut être réduit si les poids sont petits.
L'algorithme de rétro-propagation présente certains inconvénients tels qu'il peut être sensible aux données bruitées et aux valeurs aberrantes. C'est une approche entièrement matricielle. Les performances réelles de cet algorithme dépendent entièrement des données d'entrée. La sortie peut être non numérique.
16. AdaBoost
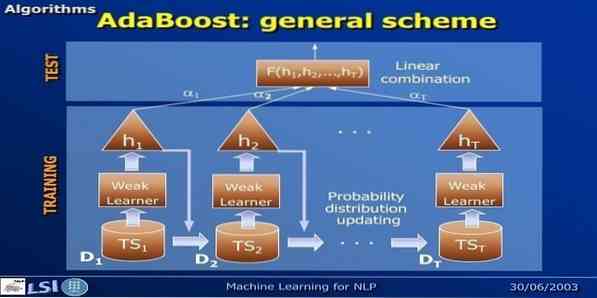
AdaBoost signifie Adaptive Boosting, une méthode d'apprentissage automatique représentée par Yoav Freund et Robert Schapire. Il s'agit d'un méta-algorithme et peut être intégré à d'autres algorithmes d'apprentissage pour améliorer leurs performances. Cet algorithme est rapide et facile à utiliser. Cela fonctionne bien avec de grands ensembles de données.
17. L'apprentissage en profondeur
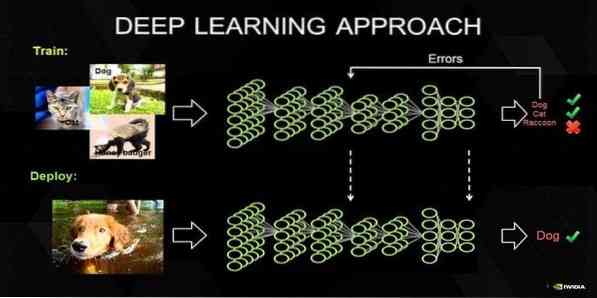
Le deep learning est un ensemble de techniques inspirées du mécanisme du cerveau humain. Les deux principaux apprentissage en profondeur, je.e., Les réseaux de neurones à convolution (CNN) et les réseaux de neurones récurrents (RNN) sont utilisés dans la classification de texte. Des algorithmes d'apprentissage en profondeur tels que Word2Vec ou GloVe sont également utilisés pour obtenir des représentations vectorielles de haut niveau des mots et améliorer la précision des classificateurs qui sont entraînés avec des algorithmes d'apprentissage automatique traditionnels.
Cette méthode d'apprentissage automatique nécessite beaucoup d'échantillons de formation au lieu des algorithmes d'apprentissage automatique traditionnels, je.e., un minimum de millions d'exemples étiquetés. D'autre part, les techniques traditionnelles d'apprentissage automatique atteignent un seuil précis où l'ajout d'échantillons d'entraînement supplémentaires n'améliore pas leur précision globale. Les classificateurs d'apprentissage en profondeur surpassent de meilleurs résultats avec plus de données.
18. Algorithme d'amplification de gradient

L'amplification de gradient est une méthode d'apprentissage automatique qui est utilisée pour la classification et la régression. C'est l'un des moyens les plus puissants de développer un modèle prédictif. Un algorithme d'amplification de gradient comporte trois éléments :
- Fonction de perte
- Apprenant faible
- Modèle additif
19. Réseau Hopfield
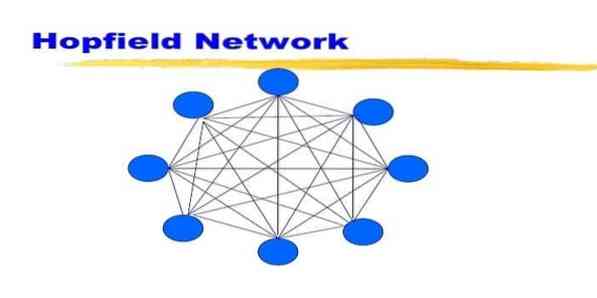
Un réseau Hopfield est un type de réseau de neurones artificiels récurrent donné par John Hopfield en 1982. Ce réseau a pour objectif de stocker un ou plusieurs modèles et de rappeler les modèles complets sur la base d'une entrée partielle. Dans un réseau Hopfield, tous les nœuds sont à la fois des entrées et des sorties et entièrement interconnectés.
20. C4.5

C4.5 est un arbre de décision inventé par Ross Quinlan. C'est une version de mise à niveau d'ID3. Ce programme algorithmique comprend quelques cas de base :
- Tous les échantillons de la liste appartiennent à une catégorie similaire. Il crée un nœud feuille pour l'arbre de décision en disant de décider de cette catégorie.
- Il crée un nœud de décision plus haut dans l'arbre en utilisant la valeur attendue de la classe.
- Il crée un nœud de décision plus haut dans l'arbre en utilisant la valeur attendue.
Mettre fin aux pensées
Il est essentiel d'utiliser le bon algorithme basé sur vos données et votre domaine pour développer un projet d'apprentissage automatique efficace. En outre, il est essentiel de comprendre la différence critique entre chaque algorithme d'apprentissage automatique pour résoudre « quand je choisis lequel.' Comme, dans une approche d'apprentissage automatique, une machine ou un appareil a appris via l'algorithme d'apprentissage. Je crois fermement que cet article vous aide à comprendre l'algorithme. Si vous avez des suggestions ou des questions, n'hésitez pas à demander. Continue de lire.


